Dies ist jetzt schon die achte Auswertung meiner jährlichen Umfrage unter meinen Leser*innen, welche Agenturen ihnen im Vorjahr, also diesmal 2023, den meisten Umsatz gebracht haben. Die Agenturen sollten sie nach Umsatz absteigend sortiert als Kommentar hinterlassen. Zusammen mit mir haben sich 38 Fotograf*innen beteiligt. Leider weniger als in den Vorjahren, aber trotzdem vielen Dank dafür!
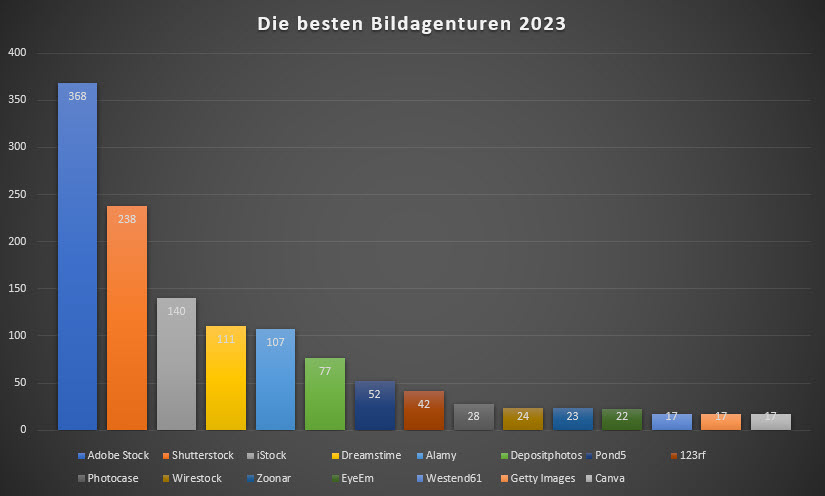
Die Ergebnisse will ich euch hier gerne vorstellen. Zuerst die eindeutige Grafik (Klick zum Vergrößern):
Meine Vorgehensweise: Ich habe in einer Excel-Tabelle eine Liste gemacht und in die erste Spalte jede Agentur eingetragen, die genannt wurde. In den nächsten Spalten habe ich dann für jede Teilnehmer*in und jede Agentur Punkte vergeben, basierend auf der Sortierung der genannten Agenturen. Die erste Agentur, also die mit dem meisten Umsatz, bekam 10 Punkte, die als zweites genannte Agentur bekam 9 Punkte und so weiter. Die Werte habe ich pro Agentur summiert und die Liste dann nach den Punkten sortiert. Das Ergebnis seht ihr oben, die Zahl in Klammern ist also die Gesamtpunktzahl der jeweiligen Agentur. Insgesamt wurden 33 verschiedene Agenturen benannt, ich habe die Liste jedoch auf die ersten 15 Agenturen beschränkt, weil das statistische Rauschen zum Ende hin mit meist nur einer Nennung sehr viel größer ist.
Hinweise: Bei der Umfrage wurde nicht unterschieden, ob die Leute Videos oder Fotos oder beides verkaufen, wie viele Dateien sie online haben oder seit wann sie dort hochladen. In der letzten Klammer sehr ihr die Veränderung zum Vorjahr.
In der Liste oben sind iStock und Getty zwar getrennt aufgeführt, ganz trennscharf lassen sich diese jedoch nicht auseinanderhalten, da iStock ja auch über Getty Images verkauft und beide Agenturen zusammengehören. Aber selbst wenn ich Getty zu iStock addiert hätte, hätte sich an der Platzierung von iStock auf dem dritten Platz nicht geändert, dafür wäre hinten nur Vecteezy als Neueinsteiger auf Platz 15 aufgetaucht, wenn Getty entfallen wäre.
Meine besten Agenturen 2023 Wer die obige Liste nachrechnen oder anders auswerten will, kann das ebenfalls machen, meine Datenbasis ist frei einsehbar, nur ein Teilnehmer hat mir seine Daten per Direktnachricht geschickt.
Was jedoch noch fehlt, sind die Agenturen, bei denen ich selbst 2023 am meisten Umsatz erzielt habe und die ich ebenfalls in obige Rechnung habe einfließen lassen. In Klammern wieder die Veränderung zum Vorjahr:
Adobe Stock (-)
Shutterstock (-)
Canva (-)
123rf (-)
Zoonar (-)
Dreamstime (+1)
Alamy (+1)
EyeEm (-2)
Pond5 (-)
Westend61 (-)
Was sagt uns diese Auswertung?
Adobe Stock hat seine Spitzenposition im Vergleich zu den Vorjahren noch weiter ausgebaut, Shutterstock bleibt jedoch – mit gebührendem Abstand – weiterhin stabil auf dem zweiten Platz.
iStock führt das Mittelfeld an, in dem sich noch Dreamstime, Alamy und Depositphotos tummeln. Die restlichen Agenturen sind kaum noch der Rede wert. Diese Formulierung fand sich auch häufig in den Kommentaren der Teilnehmer.
Den größten Abstieg musste EyeEm erleiden, was sehr wahrscheinlich direkt mit deren Insolvenz letztes Jahr zusammenhängt. Am stärksten aufgestiegen ist Pond5, wobei ich hier nicht erkennen kann, woran das liegen könnte.
Die Beteiligung dieses Jahr war leider auch deutlich geringer, was die Datenqualität natürlich etwas leiden lässt.
Habt ihr die Ergebnisse erwartet? Oder sind Überraschungen für euch dabei?
Im Juli 2021 hatte die Bildagentur Shutterstock angekündigt, auch KI-Datensätze anzubieten, mit denen kommerzielle Anbieter ihre KI-Tools trainieren können.
Im Oktober 2022 führte Shutterstock dann in Zusammenarbeit mit den Firmen OpenAI und LG selbst die Möglichkeit ein, dass Kunden KI-generierte Bilder auf deren Webseite erstellen und lizenzieren können.
Für solche KI-Nutzungen des Bildmaterials sollen die Anbieter entschädigt werden.
Shutterstock selbst schreibt dazu im oben verlinkten FAQ:
„Wir haben einen Shutterstock Anbieter-Fonds eingerichtet, der Shutterstock Anbieter direkt vergütet, wenn ihr geistiges Eigentum bei der Entwicklung von KI-generativen Modellen wie dem OpenAI-Modell verwendet wurde, indem Daten aus dem Shutterstock Archiv lizenziert werden. Darüber hinaus wird Shutterstock die Anbieter weiterhin für die zukünftige Lizenzierung von KI-generiertem Content über das Shutterstock AI-Content-Generierungstool vergüten. Die Einnahmen aus den OpenAI-Datensätzen, auch bekannt als Datendeals, werden im 4. Quartal 2022 veröffentlicht. […]
Dies ist eine neue Einnahmequelle für Anbieter, die über Downloads und die Lizenzierung einzelner Assets für kommerzielle oder redaktionelle Zwecke hinausgeht. Wir sind fest entschlossen, unsere Anbieter als Partner auf diesem Weg einzubeziehen und sicherzustellen, dass sie einen Anteil an den Erlösen aus Computer-Vision-Datensätzen (auch bekannt als Datendeals) und generativen KI-Modellen erhalten, wenn ihre Inhalte bei der Erstellung dieser Technologien verwendet werden. Angesichts des kollektiven Charakters dieses Produkts haben wir ein Vergütungsmodell für Umsatzbeteiligungen entwickelt. […]
Die Anbieter erhalten einen Anteil am gesamten Vertragswert, der von den Plattform-Partnern bezahlt wird. Der Anteil, den einzelne Anbieter erhalten, steht im Verhältnis zum Umfang ihrer Inhalte und Metadaten, die in den erworbenen Datensätzen enthalten sind. Obwohl die Aufnahme in Datensätze nicht wie andere einzelne Downloads in der Ergebnisübersicht berücksichtigt wird, wie die Einnahmen aus anderen E‑Commerce-Produkten, unterhält Shutterstock eine interne Datenbank aller Assets, die in allen Datensätzen verwendet werden, die seit der Einführung dieses Produkts erstellt wurden, sodass wir unsere Anbieter entsprechend vergüten können.
Anbieter, deren Inhalte zum Trainieren eines der Modelle verwendet wurden, werden für die Rolle, die ihr geistiges Eigentum bei der Entwicklung der ursprünglichen Modelle gespielt hat, sowie durch Lizenzgebührenzahlungen vergütet, die an zukünftige generative Lizenzierungsaktivitäten gebunden sind. Wenn Ihre Inhalte in beiden verwendet wurden, erhalten Sie eine Zahlung, die Sie für die Aufnahme Ihrer Inhalte in beide Datensätze (auch bekannt als Datendeals) vergütet, und Sie haben Zugang zu mehr zukünftigen Umsatzmöglichkeiten, da Sie Anspruch auf eine Vergütung aus unserem Anbieter-Fonds für zukünftige Lizenzierungsereignisse der generativen Content-Entwicklung aus beiden Modellen haben. […]“
Alle sechs Monate werden laut Shutterstock die gesammelten Einnahmen an die Fotografen ausgeschüttet und in der Umsatzübersicht im Bereich „Anbieterfonds“ (auf englisch „Contributor Funds“) angezeigt.
So ganz scheint das nicht zu stimmen, da ich erstmalig eine solche Auszahlung Ende Dezember 2022 erhalten hatte und nun – wie viele andere Fotografen auch – Anfang Mai 2023 noch mal. Aber vielleicht pendelt sich das noch ein.
Analyse der Anbieterfonds-Umsätze
Da das eine ganz neue Einnahmekategorie für Fotografen ist, habe ich in auf meiner Facebook-Seite darum gebeten, dass meine Leser*innen ihre Umsätze aus den Anbieterfonds sowie ihre Portfolio-Größe nennen, damit ich die Durchschnitts- und Maximalwerte berechnen kann.
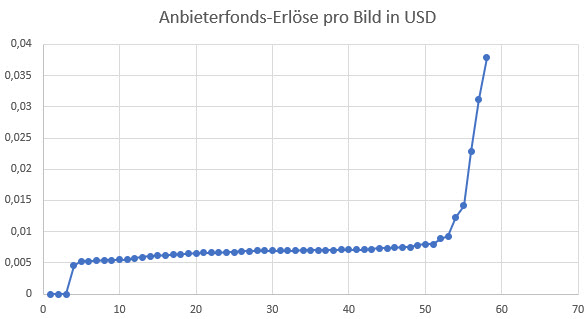
Es haben sich mit mir 58 Leute beteiligt, was die Ergebnisse ganz aussagekräftig macht, wie ich finde. Hier die visuelle Darstellung:
Im Durchschnitt betrug die Portfolio-Größe der Teilnehmer*innen 6343 Bilder. Da der Durchschnitt durch einige extreme Werte schnell verzehrt werden kann, ist der Median in der Regel aussagekräftiger. Dieser betrug 2112 Bilder.
Der durchschnittliche Erlös aus den Anbieterfonds pro Bild lag gerundet bei 0,0078 USD/Bild. Der Median lag bei 0,0069 USD/Bild. Mein eigener Wert lag übrigens zwischen diesen beiden Werten.
Als spannende Fußnote: Der höchste Wert betrug 0,0378 USD/Bild (bei einem eher kleinen Portfolio mit 1480 Bildern).
Die gesamte Auszahlung pro Portfolio der Teilnehmer*innen lag durchschnittlich bei 45,97 USD, der Median bei 18,49 USD.
Hochrechnung auf das gesamte Shutterstock-Portfolio
Für das erste Quartal 2023 hat das börsennotierte Unternehmen Shutterstock 615 Mio. Bilder im Portfolio gemeldet.
Wenn wir nun grob den Median von 0,0069 USD pro Bild auf die 615 Mio. Bilder im gesamten Portfolio umrechnen, erhalten wir einen Wert von ca. 4,24 Mio. USD an Auszahlungen als Schätzung für die Anbieterfonds allein für die Mai-Auszahlung.
Angesichts des gemeldeten Umsatzes von über 215 Mio. USD sowie einem Nettogewinn von über 32 Mio. USD ist das durchaus ein Wert, der nicht so ins Gewicht fällt für Shutterstock.
Perspektive
Sind ca. zwei Drittel eines US-Cents pro Bild im Portfolio zwei Mal im Jahr ausreichend und fair, um die KI-Nutzung der eigenen Bilder ausreichend zu kompensieren? Ich lehne mich mal weit aus dem Fenster und behaupte: Nein.
Allein mein Einnahmeverlust bei Shutterstock im letzten Monat war höher als ein Jahres-KI-Anbieterfonds-Erlös bei Shutterstock, weshalb meine Zweifel groß sind, dass diese Beträge motivierend genug für die Fotograf*innen sind, um weiterhin qualitativ hochwertige Inhalte zu produzieren.
Dies ist jetzt schon die siebte Auswertung meiner jährlichen Umfrage unter meinen Leser*innen, welche Agenturen ihnen im Vorjahr, also diesmal 2022, den meisten Umsatz gebracht haben. Die Agenturen sollten sie nach Umsatz absteigend sortiert als Kommentar hinterlassen. Zusammen mit mir haben sich 56 Fotograf*innen beteiligt. Vielen Dank dafür!
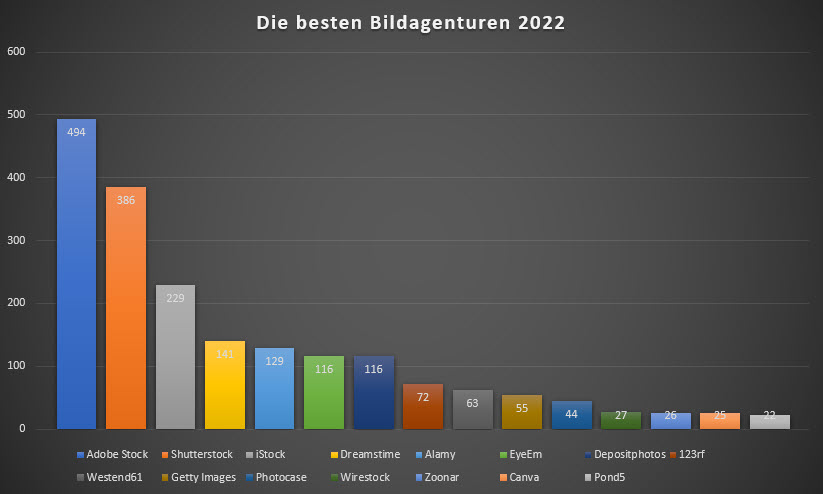
Die Ergebnisse will ich euch hier gerne vorstellen. Zuerst die eindeutige Grafik (Klick zum Vergrößern):
Meine Vorgehensweise: Ich habe in einer Excel-Tabelle eine Liste gemacht und in die erste Spalte jede Agentur eingetragen, die genannt wurde. In den nächsten Spalten habe ich dann für jede Teilnehmer*in und jede Agentur Punkte vergeben, basierend auf der Sortierung der genannten Agenturen. Die erste Agentur, also die mit dem meisten Umsatz, bekam 10 Punkte, die als zweites genannte Agentur bekam 9 Punkte und so weiter. Die Werte habe ich pro Agentur summiert und die Liste dann nach den Punkten sortiert. Das Ergebnis seht ihr oben, die Zahl in Klammern ist also die Gesamtpunktzahl der jeweiligen Agentur. Insgesamt wurden 45 verschiedene Agenturen benannt, ich habe die Liste jedoch auf die ersten 15 Agenturen beschränkt, weil das statistische Rauschen zum Ende hin mit meist nur einer Nennung sehr viel größer ist.
Hinweise: Bei der Umfrage wurde nicht unterschieden, ob die Leute Videos oder Fotos oder beides verkaufen, wie viele Dateien sie online haben oder seit wann sie dort hochladen. In der letzten Klammer sehr ihr die Veränderung zum Vorjahr.
In der Liste oben sind iStock und Getty zwar getrennt aufgeführt, ganz trennscharf lassen sich diese jedoch nicht auseinanderhalten, da iStock ja auch über Getty Images verkauft und beide Agenturen zusammengehören. Aber selbst wenn ich Getty zu iStock addiert hätte, hätte sich an der Platzierung von iStock auf dem dritten Platz nicht geändert, dafür wäre hinten nur der „eigene Bildershop“ (verschiedener Leute) auf Platz 15 aufgetaucht, wenn Getty entfallen wäre.
Meine besten Agenturen 2022 Wer die obige Liste nachrechnen oder anders auswerten will, kann das ebenfalls machen, meine Datenbasis ist frei einsehbar. Was jedoch noch fehlt, sind die Agenturen, bei denen ich selbst 2022 am meisten Umsatz erzielt habe und die ich ebenfalls in obige Rechnung habe einfließen lassen. In Klammern wieder die Veränderung zum Vorjahr, das heißt also, das die Reihenfolge identisch mit der von 2021 ist:
Adobe Stock (-)
Shutterstock (-)
Canva (-)
123rf (-)
Zoonar (-)
EyeEm (-)
Dreamstime (-)
Alamy (-)
Pond5 (-)
Westend61 (-)
Was sagt uns diese Auswertung?
Adobe Stock hat seine Spitzenposition im Vergleich zu den Vorjahren noch weiter ausgebaut, Shutterstock bleibt jedoch weiterhin stabil auf dem zweiten Platz.
Mit deutlichem Abstand führt iStock das Mittelfeld an, in dem sich noch Dreamstime, Alamy, 123rf, Depositphotos und EyeEm tummeln. Depositphotos hat absolut gesehen etwas zugelegt, die anderen Agenturen im Mittelfeld jedoch abgenommen.
Die restlichen Agenturen sind kaum noch der Rede wert. Diese Formulierung fand sich auch häufig in den Kommentaren der Teilnehmer.
Hier könnt die auch die Auswertungen aus den Jahren 2022, 2021, 2020, 2019, 2018 und 2017 nachlesen.
Interessante Auffälligkeiten
Der höchste Neueinstieg letztes Jahr war Wirestock, welche jedoch dieses Jahr auch schon wieder einige Plätze verloren haben. Einziger Neueinstieg 2022 in das Ranking war Canva, ausgestiegen aus der Liste ist dadurch Panthermedia.
Habt ihr die Ergebnisse erwartet? Oder sind Überraschungen für euch dabei?
Meine geplanten Artikel zu den neusten KI-Entwicklungen sind noch nicht mal fertig, da platzen ständig aufregende Neuigkeiten herein. Die Nachricht vom 25.10.2022 von Shutterstock kann ich hier aber nicht ignorieren, da sie einen wilden Mix von Konsequenzen nach sich zieht, den ich hier vermutlich nur ansatzweise beleuchten kann.
Aber versuchen wir es der Reihe nach: Shutterstock hat vor wenigen Tagen diese Pressemitteilung veröffentlicht, in der die Firma die Partnerschaft mit dem Unternehmen OpenAI verkündet, welche hinter dem KI-Tool DALL‑E stecken. Hinter OpenAI stecken übrigens u.a. Elon Musk als Gründer und Microsoft als Investor.
Bild von DALL‑E 2 generiert mit der Beschreibung „A tornado made of cash hitting a government building“
Zeitgleich gab es eine Rundmail an alle Shutterstock-Anbieter, in der zusätzlich zur obigen Information eine ebenso wichtige weitere Nachricht steckte: Shutterstock will keine KI-generierten Inhalte mehr auf ihrem Marktplatz anbieten, mit der Begründung, dass „die Urheberschaft nicht einer einzelnen Person zugeordnet werden kann, wie es für die Lizenzierung von Rechten erforderlich ist“.
Oder hier im Hilfebereich von Shutterstock noch ausführlicher begründet: „KI-generierte Inhalte dürfen nicht auf Shutterstock hochgeladen werden, da KI-Inhaltsgenerierungsmodelle das geistige Eigentum vieler Künstler und ihrer Inhalte nutzen, was bedeutet, dass das Eigentum an KI-generierten Inhalten nicht einer Einzelperson zugewiesen werden kann und stattdessen alle Künstler entschädigt werden müssen, die an der Erstellung jedes neuen Inhalts beteiligt waren“.
Diese Kombination von Aussagen wirft so viele Fragen auf, dass ich gar nicht weiß, wo ich anfangen soll.
Gehen wir mal in der Zeit etwas zurück: Shutterstock kooperiert schon seit 2021 mit der Firma OpenAI, indem OpenAI Shutterstock-Bilder lizenziert hat, um das Tool DALL‑E zu trainieren. Der CEO von OpenAI, Sam Altman, sagt dazu in der Pressemitteilung:
„Die Daten, die wir von Shutterstock lizenziert haben, waren entscheidend für das Training von DALL‑E. Wir freuen uns, dass Shutterstock seinen Kunden die DALL-E-Bilder als eine der ersten Anwendungen über unsere API zur Verfügung stellt, und wir freuen uns auf künftige Kooperationen, wenn künstliche Intelligenz ein integraler Bestandteil der kreativen Arbeitsabläufe von Künstlern wird.“
In wenigen Monaten sollen Shutterstock-Kunden in der Lage sein, mit Hilfe von OpenAI direkt auf der Shutterstock-Webseite durch Texteingabe Bilder selbst generieren zu können.
Im Gegenzug dafür sollen die Shutterstock-Anbieter für die Rolle, die ihre Inhalte bei der Entwicklung dieser Technologie gespielt haben, entschädigt werden.
Die erste Frage hier ist doch: Wurden die Shutterstock-Anbieter auch für die Trainingsdaten, die seit 2021 von OpenAI lizenziert wurden, entschädigt?
Die zweite Frage ist: Haben die Künstler, auf deren Eigentum Shutterstock angeblich so viel Wert lege, damals überhaupt zugestimmt, dass ihre Bilder für Trainingszwecke genutzt werden dürfen?
Die dritte Frage ist logischerweise: Wie viele Bruchteile von US-Cents sollen die Anbieter als „Entschädigung“ erhalten?
Ich könnte jetzt eine Weile mit solchen Fragen weitermachen, aber betrachten wir erst mal andere Perspektiven.
Die Kunden-Sicht
Aus Kundensicht erschließt sich nicht sofort, warum sie KI-Bilder bei Shutterstock – sehr vermutlich gegen Geld – generieren sollten, wenn sie es bei OpenAI auch kostenlos machen können. Jeden Monat gibt es bei DALL‑E 2 kostenlos 15 Credits für je Bilderstellungen (1 Credit pro Bild), 115 weitere Credits kosten dann 15 USD, also ca. 13 US-Cent pro Bild.
Es könnte auch sein, dass Shutterstock diesen Preis noch mal unterbieten will.
Darüber hinaus gibt es aber gänzlich kostenlose KI-Tools wie Stable Diffusion (und passende GUIs), mit der Nutzer ihre Bilder komplett gratis erstellen können.
Der Vorteil wäre maximal, wenn Kunden mit Shutterstock eine Firma haben, die für eventuelle (rechtliche?) Probleme haften könnte. Ansonsten spekuliert Shutterstock vielleicht darauf, dass es genug Bestandskunden gibt, welche sich nicht die Mühe machen (wollen), sich bei einer Plattform wie Dall‑E 2 zu registrieren, um dort die Gratis-KI-Bilder zu nutzen.
Die Agentur-Sicht
Aus Sicht von Shutterstock ist es natürlich clever: Warum sollten sie diese nervigen Bildlieferanten bezahlen müssen, wenn sie den Kunden auch ohne den Umweg über die Fotografen Bilder verkaufen können?
Das geht natürlich nur, wenn gleichzeitig den Anbietern verboten wird, KI-generierte Bilder selbst zum Verkauf anzubieten, denn immerhin will das ja die Agentur übernehmen. Warum die angeblichen rechtlichen Risiken, welche als Grund für das Upload-Verbot vorgeschoben werden, plötzlich nicht mehr gegeben sind, wenn Shutterstock die KI-Bilder generiert, erschließt sich nicht ganz. Dazu später mehr.
Das Verbot ist augenscheinlich vor allem dazu da, um mehr Kunden zur agentureigenen KI-Generierung zu bewegen.
Zwar hat Shutterstock schon „Entschädigungen“ für die Shutterstock-Künstler angeboten, deren Werke zum Training der KI benutzt werden, aber machen wir uns nichts vor: Das werden pro Bild maximal etliche Stellen hinter dem Komma sein und auch in der Summe deutlich weniger sein als die Verluste, welche die Anbieter erleiden werden, weil Kunden keine Bilder aus dem Portfolio kaufen, sondern sich welche generieren lassen und die Fotografen auch selbst keine KI-Bilder verkaufen dürfen.
Zur Erinnerung: Als Getty Images 2013 einen Deal mit Pinterest machte, um die Getty-Fotografen für deren Bildnutzungen auf Pinterest zu entschädigen, erhielten diese zum Beispiel 0,00062 USD für das „weltweite Recht, Metadaten ihres Bildes auf Pinterest anzuzeigen und zu nutzen“, während Getty selbst sich immerhin noch 0,00411 USD in die Tasche steckte. Anders gerechnet: Bei 1000 Bildnutzungen waren das für den Fotografen 62 Cent und für Getty Images aber 4,11 USD.
Die Konkurrenz ist zudem groß: Auch Microsoft will DALL‑E in deren Suchmaschine Bing integrieren und hat eine neue App namens „Designer“, die Produkt- oder Firmennamen und die dazu passenden Bilder oder Logos generieren können soll.
Bild von Stable Diffusion generiert mit der Beschreibung „A tornado made of cash hitting a government building“
Die Anbieter-Sicht
Für Shutterstock-Anbieter sind diese Nachrichten ausnahmslos schlecht. Die „Entschädigung“ ist ein armseliges Feigenblatt, hinter dem Shutterstock die Marginalisierung ihrer Lieferanten versteckt. In der Pressemitteilung wird ständig von „Ethik“ und „Verantwortung“ geredet, aber damit ist nicht die Rücksicht auf die Anbieter gemeint, sondern auf die der Shutterstock-Aktionäre.
Shutterstock hat halt endlich einen Weg gefunden, die lästigen 20% Fotografen-Kommissionen auch noch loszuwerden, um es lapidar zu formulieren.
Die genannte „Entschädigung“ soll aus einem „Contributor Fund“ kommen und alle sechs Monate ausgezahlt werden. Als Einnahmen dafür sollen sowohl die Lizenzgebühren für die KI-Inhalte als auch Einnahmen aus Datenverkäufen gezählt werden. Der Anteil für die Anbieter soll proportional sein zum Volumen ihrer Inhalte in den Datensätzen.
Wie das kontrolliert oder überprüft werden soll, ist auch völlig schleierhaft und vermutlich unmöglich ohne die Offenlegung des kompletten Datensatzes.
Wenn Shutterstock und Getty Images keine KI-Bilder haben wollen, wird es aber weiterhin genug andere Agenturen geben, welche diese mit Kusshand annehmen. Es drängen jetzt schon die ersten Bildagenturen auf den Markt wie StockAI, welche nur KI-Bilder anbieten und diese natürlich auch generieren können.
Die Künstler-Sicht
In der o.g. Pressemitteilung heißt es zum Schluss:
„Und in einem wichtigen Bestreben, die IP-Rechte seiner Künstler, Fotografen und Schöpfer zu schützen, ist Shutterstock weiterhin führend in der Entwicklung von Richtlinien und Verfahren und setzt Methoden ein, um sicherzustellen, dass Nutzungsrechte und ordnungsgemäße Lizenzen für alle vorgestellten Inhalte – einschließlich KI-generierter Inhalte – gesichert sind.“
DALL‑E wurde mit über 12 Milliarden Text/Bild-Kombinationen trainiert, während Shutterstock gerade mal 424 Millionen Bilder online hat. Das heißt im Umkehrschluss, der größte Teil des Trainings wurden mit Bildern von Künstlern gemacht, die nicht bei Shutterstock sind. Das ganze Gerede vom „Schützen von IP-Rechten“ bezieht sich aber nur auf die Shutterstock-Anbieter, der große Rest kann zusehen, wie für die KI-Trainings „entschädigt“ wird.
Das zeigt auch gut die Heuchelei von Shutterstock. Angeblich weil bei KI-Inhalten alle Künstler entschädigt werden müssten, dürfen Anbieter keine KI-Inhalte hochladen, aber wenn Shutterstock selbst via API einen Zugang zu OpenAI’s DALL‑E anbietet, werden ebenfalls nicht alle Künstler entschädigt.
Die rechtliche Sicht
Ist die Entschädigung von Künstlern, deren Werke für das KI-Training benutzt wurden, rechtlich gesehen überhaupt notwendig? Ich weiß es ehrlich gesagt nicht. Einige meinen, das sei eine klassische „fair use“-Nutzung, andere sehen es nicht so.
Mal angenommen, rechtlich wäre eine Entschädigung nicht notwendig: Dann fallen Shutterstocks Argumente, warum sie keine KI-Bilder annehmen wollen, in sich zusammen.
Wenn eine Entschädigung rechtlich aber doch notwendig wäre: Dann ist vollkommen unbegreiflich, warum sich diese erstens nur auf Shutterstock-Künstler beschränken sollte (und nicht z.B. auf Künstler wie Greg Rutkowski) und zweitens warum diese nicht stattfindet, wenn Bilder direkt bei DALL‑E generiert werden statt über deren API zu Shutterstock.
Es ist also so oder so ein großes unlogisches Konstrukt, welches sich am besten dadurch erklärt, dass es Shutterstock eben nicht um die Belange der Künstler, sondern nur um den eigenen Profit geht.
Spannend auch, dass der Getty Images-CEO Craig Peters KI-Bilder u.a. deshalb in seiner Agentur verbietet, weil sie rechtliche Probleme für die Kunden mit sich bringen könnten. Warum das anders sein soll, wenn Shutterstock Kunden KI-Bilder generieren lässt, ist ein großes Rätsel.
Eine mögliche Lösung wäre, dass die OpenAI-KI ausschließlich auf Shutterstock-Bildern trainiert wurde, für die sowohl Shutterstock die Einwilligung aller Rechteinhaber zum Training hatte als auch OpenAI diese Rechte lizenziert habe. In den aktuellen Shutterstock-AGB von 2020 steht beispielsweise, dass Shutterstock das Recht zur Bildanalyse unterlizenzieren darf. Aber selbst wenn OpenAI jedes einzelne Bild aus der Shutterstock-Datenbank lizenziert habe, würde das bei vermutlich weitem nicht ausreichen, um als alleinige Datenbasis für das KI-Training zu dienen.
Aber vielleicht liege ich damit auch falsch und es ist sogar ein Vorteil, weil die Shutterstock-Bilder alle eine hohe Auflösung haben und im Vergleich zu anderen Bildern meist recht gut verschlagwortet sind.
Auch die EU hat im Blick, dass die Künstliche Intelligenz gefährlich sein könnte und arbeitet an einer „KI-Verordnung“. Ob solche Verordnungen aber den aktuellen Graubereich der Legalität von urheberrechtlich geschützten Werken für KI-Trainingszwecke regulieren werden, bleibt abzuwarten.
Bild von Midjourney generiert mit der Beschreibung „A tornado made of cash hitting a government building“
Die politische Sicht
Shutterstock wurde 2019 von den eigenen Mitarbeitern kritisiert, dass die Agentur in China Suchbegriffe wie „Flagge Taiwans“, „Diktator“, „Präsident Xi“ oder „Regenschirm“ gesperrt habe.
Sehr spannend ist hier jetzt die Frage, ob diese Begriffe dann auch bei der KI-Generierung in China gesperrt sein werden oder nicht.
Auch andere Begriffe, zum Beispiel sexueller oder gewaltverherrlichender Natur, könnten gesperrt werden, um sich weniger Haftungsfragen aussetzen zu müssen.
Die technische Sicht
Viele der genannten Tools sind aktuell noch im Beta-Stadium und sie entwickeln sie unglaublich rasant. Es ist vermutlich nur eine Frage der Zeit, bis Methoden wie das In- und Outpainting von DALL‑E 2 auch in Grafikprogramm wie Adobe Photoshop Einzug halten werden oder es WordPress-Plugins geben wird, welche auf Knopfdruck zum Artikeltext passende Bilder generieren.
Auch das Trainieren der KI zum Generieren vom eigenen Gesicht (oder das von Kundengesichtern) ist jetzt schon möglich und wird bald sicher noch einfacher machbar sein.
Was noch?
Ganz wilde Zeiten also mit viel Unsicherheit, Abwehrreaktionen etablierter Künstler, rechtlichen Grauzonen, dem Zusammenbruch bestehender und Aufbau neuer Geschäftsmodelle und mittendrin Bildagenturen, Fotografen und KI-Anbieter.
Es gibt noch etliche Aspekte, die hier nicht untergebracht werden konnte, das kommt bestimmt bald in einem weiteren Artikel.
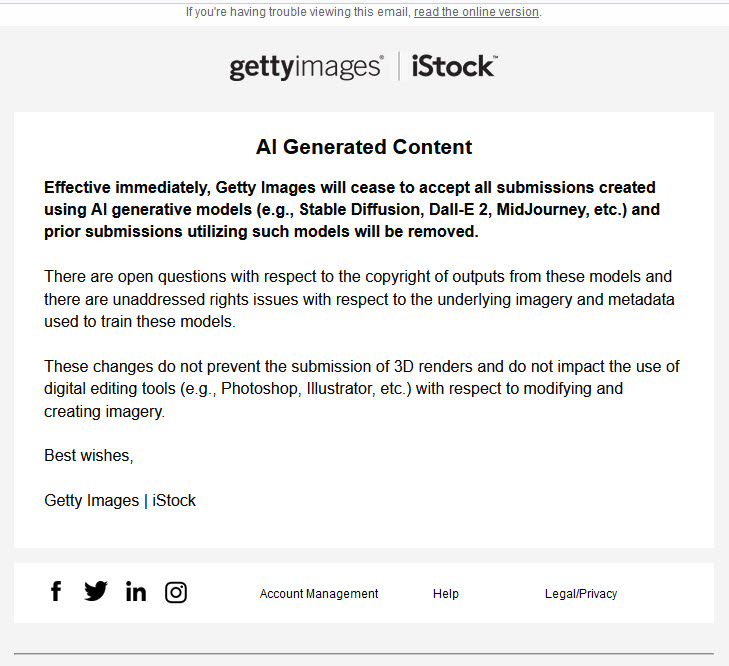
Kurz hintereinander haben sowohl Shutterstock als auch Getty Images mit deren Tochter-Agentur iStock angekündigt, keine KI-Bilder mehr annehmen zu wollen.
Ki-Bild (Dall‑E 2) von einem Roboter, der ein Bild malt
Angesichts der steigenden Popularität von KI-Software zur Bild-Generierung wie Dall‑E 2, Stable Diffusion, Midjourney und Konsorten sowie der verbesserten Bildqualität dieser Tools gab es in den letzten Monaten einen starken Anstieg von KI-Bildern im Portfolio von Bildagenturen.
Email, die an iStock/Getty-Fotografen ging
Nun haben zumindest die beiden großen Platzhirsche Shutterstock und Getty Images die Reißleine gezogen und angekündigt, keine KI-Bilder mehr annehmen zu wollen.
Als Grund werden in einer Email von Getty Images „unadressierte rechtliche Fragen mit Hinblick auf die zugrunde liegenden Bilder und Metadaten, die zum Training der KI genutzt worden sind“ angegeben.
Auch Shutterstock formuliert in einer Email an ausgewählte Kontributoren ähnliche Bedenken:
Email von Shutterstock an einige Kontributoren
Hier werden „rechtliche Implikationen“ als Grund dafür genannt, dass etliche KI-Bilder der angeschriebenen Personen gelöscht wurden und es wird geschrieben, dass Shutterstock „keine maschinengenerierten Inhalte akzeptieren“ würde gemäß Sektion 13.d/f ihrer Nutzungsbedingungen.
Ich bin mir zwar nicht ganz sicher, ob sie da wirklich die richtigen Absätze rausgesucht haben, aber grundsätzlich steht es Shutterstock natürlich frei, solche Regeln aufzustellen, wenn sie der Meinung sind, dass sie hilfreich seien.
Zeitgleich experimentiert Shutterstock aber selbst schon mit künstlicher Intelligenz. So bietet deren neues Projekt „Predict“ Kunden die Möglichkeit, mittels KI erkennen zu können, welche Bilder für welche Zwecke am passendsten sein sollen. Shutterstock schreibt:
„Was performt besser? Diese wiederkehrende Frage ist mit Predict viel einfacher zu beantworten. Die App nutzt KI, um die Stärken und Schwächen individueller Assets speziell für Ihre Anforderungen zu analysieren. Predict sagt Ihnen, WARUM ein empfohlener Inhalt voraussichtlich gut performt, damit Sie selbstbewusst kreativ werden können.“
Nach einer kostenlosen Testphase wollen sie sich diese Informationen natürlich bezahlen lassen.
Getty Images versucht ebenfalls seit Januar 2022, die Vorteile der KI für sich auf eine andere Weise zu nutzen. So veröffentlichte die Agentur einen neuen Modelvertrag, der jetzt unter anderem einen neuen Passus enthält, mit dem sich das Model bereit erklärt, dass die Bilder zum Trainieren von Künstlicher Intelligenz genutzt werden dürfen:
„Ich erkläre mich ferner damit einverstanden, dass der Inhalt mit anderen Bildern, Texten, Grafiken, Filmen, Audio- und audiovisuellen Werken kombiniert und zur Entwicklung und Verbesserung von maschinellen Lernalgorithmen, künstlicher Intelligenz und anderen Technologien bearbeitet und genutzt werden darf.“
Auch bei der deutschen Bildagentur Westend61 werden die KI-Bilder als hoch problematisch angesehen und aus rechtlichen Gründen sollten diese momentan nicht akzeptiert werden. Mehr Informationen dazu sollen folgen.
Einige Online-Kunst-Communities wie Newgrounds, Inkblot Art und Fur Affinity haben ebenfalls das Hochladen von KI-Werken untersagt oder eingeschränkt.
Diese Bildlöschungen folgen einige Wochen nach der Veröffentlichung eines Teils des KI-Trainings-Datensatzes mit rund 12 Mio. Bildern von den insgesamt über 2,3 Milliarden Trainingsbildern. Dieser Trainingsdatensatz der Organisation LAION wurde zum Beispiel für das Anlernen der KI von NightCafe, Midjourney und Stable Diffusion genutzt.
In der Veröffentlichung wurde unter anderem deutlich, dass zum Lernen auch große Bildbestände der Bildagenturen benutzt wurden. So waren von den ausgewerteten 12 Mio. Bildern mindestens 497.000 von 123rf, 171.000 von Adobe Stock/Fotolia, 117.000 von PhotoShelter, 35.000 von Dreamstime, 23.000 von iStock, 22.000 von Unsplash, 15.000 von Getty Images, 10.000 von VectorStock, 10.000 von Shutterstock und so weiter. Die Dunkelziffer dürfte hier weit höher sein, da viele dort gekaufte Bilder auf Kundenwebseiten nicht immer als von einer Agentur kommend erkennbar sind.
Ich bin unsicher, ob diese Entscheidung so klug ist. Denn solche Verbote könnten dazu führen, dass sich die KI-Szene andere „Ökosysteme“ aufbaut. So gibt es beispielsweise mit PromptBase schon eine Webseite, wo Anbieter auf einem Marktplatz „Prompts“ für KI-Systeme verkaufen können. Prompts sind die Texteingaben, die zur Bilderstellung (noch) nötig sind und die Anbieter garantieren mit ihren Prompts ähnliche Ergebnisse wie die, die sie im Marktplatz vorzeigen. Im Kern ist das schon eine Art neuer Bildagentur, bei der die Leute nicht die Bilder direkt kaufen, sondern die Option, sich sehr ähnliche Bilder selbst gratis generieren zu können.
Außerdem erhöhen solche Einschränkungen wie das Verbot von KI-Bildern in den bestehenden Bildagenturen nur die Wahrscheinlichkeit, dass ein neues Start-Up eine neue Bildagentur aufmacht, welche offensiv einfach nur noch KI-generiertes Material verkauft.
Mit der Webseite Lexica gibt es auch schon eine Art „Open Source“-Community für KI-Bilder, wo Nutzer sich mehrere Millionen mit Stable Diffusion erstellte Bilder anschauen, durchsuchen und sehen können, welche Prompts zur Erstellung genutzt wurden. Von der Möglichkeit, diese Bilder direkt zur Lizenzierung anzubieten, ist es dann nur noch ein kleiner Schritt.
Während die großen Bildagenturen einen Abwehrkampf gegen die KI-Bilder beginnen, fangen andere Start-Ups längst an, mittels KI aus Text-Prompts ganze Video-Sequenzen zu erstellen.
Was diese KI-Entwicklung für die (Stock-)Fotografen selbst bedeutet, werde ich hoffentlich bald in einem eigenen Artikel beleuchten.
Wie seht ihr das? Bringen Verbote von KI-Bildern etwas?