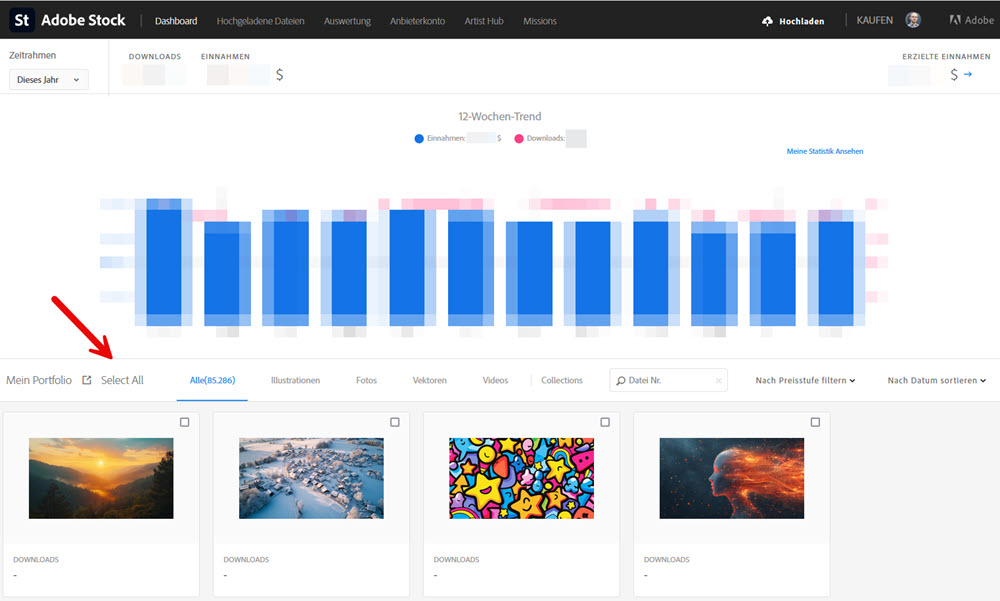
Ich habe bei der Bildagentur Adobe Stock über 85.000 Bilder online und alle dieser Bilder sind – nach Shootings o.ä. sortiert – in „Collections“ einsortiert, damit ich diese mit dem Analysetool Stock Performer separat auslesen und meine Statistiken nach Collection getrennt analysieren kann.
Leider ist es oft sehr mühsam, alle Bilder auf einer Seite einzeln anklicken zu müssen, nur um diese 100 Bilder einer Collection zuzuweisen.
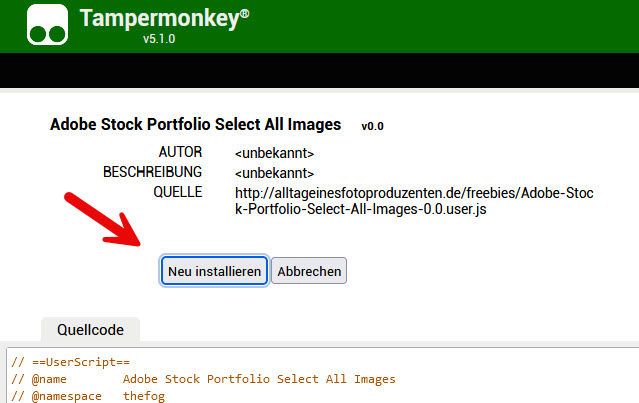
Mit der Hilfe von Jörg Stöber (siehe „Podcast eines Fotoproduzenten“-Folge 21) gibt es nun aber endlich eine Abhilfe. Mit der Installation eines kleinen und kostenlosen Greasemonkey/Tampermonkey-Skripts namens „Adobe Stock Portfolio Select All Images“ erscheint nach dem Neu-Laden der Adobe Stock-Portfolio-Seite der Button „select all“.
Damit lassen sich mit einem Knopfdruck gleich alle 100 Bilder auf der jeweiligen Seite markieren. Das spart also bei Bedarf 99 Mausklicks!
Wie installiere ich das Skript?
Installiere die kostenlose Erweiterung „Tampermonkey“ oder „Greasemonkey“ für Firefox, bzw. die kostenlose Erweiterung „Tampermonkey“ oder „Violentmonkey“ für Google Chrome. Für macOS (Safari), Opera und MS Edge gibt es sicher ähnliche Erweiterungen.
Lade zuerst die kostenlose UserScript-Datei „Adobe Stock Portfolio Select All Images“ hier herunter (ggf. „Speichern unter“ mit Rechtsklick).
Installiere das UserScript mit TamperMonkey bzw. den genannten Alternativen. Fertig.
Alternativ kannst Du auch direkt auf den Link klicken, wenn obige Erweiterung schon aktiviert ist, dann erkennt Tampermonkey das Skript und fragt, ob Du es benutzen möchtest. Das sieht dann ungefähr so aus:
Wie nutze ich das „select all“-Skript?
Wenn sowohl die Erweiterung als auch das UserScript aktiviert sind, kannst Du auf die Portfolio-Seite von Adobe Stock gehen und Du solltest wie im Screenshot oben den Text „Select All“ sehen. Wenn der nicht sichtbar ist, hilft in der Regel ein Refresh der Webseite. Durch das Klicken auf den Text werden alle 100 Bilder auf der Seite gleichzeitig selektiert.
Ich wünsche euch viel Zeitersparnis mit dem Skript.
Kurz hintereinander haben sowohl Shutterstock als auch Getty Images mit deren Tochter-Agentur iStock angekündigt, keine KI-Bilder mehr annehmen zu wollen.
Ki-Bild (Dall‑E 2) von einem Roboter, der ein Bild malt
Angesichts der steigenden Popularität von KI-Software zur Bild-Generierung wie Dall‑E 2, Stable Diffusion, Midjourney und Konsorten sowie der verbesserten Bildqualität dieser Tools gab es in den letzten Monaten einen starken Anstieg von KI-Bildern im Portfolio von Bildagenturen.
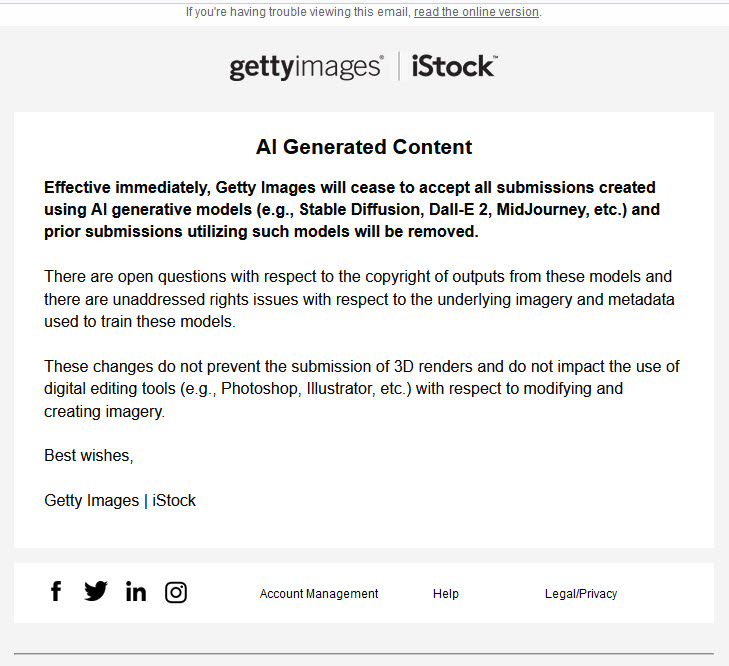
Email, die an iStock/Getty-Fotografen ging
Nun haben zumindest die beiden großen Platzhirsche Shutterstock und Getty Images die Reißleine gezogen und angekündigt, keine KI-Bilder mehr annehmen zu wollen.
Als Grund werden in einer Email von Getty Images „unadressierte rechtliche Fragen mit Hinblick auf die zugrunde liegenden Bilder und Metadaten, die zum Training der KI genutzt worden sind“ angegeben.
Auch Shutterstock formuliert in einer Email an ausgewählte Kontributoren ähnliche Bedenken:
Email von Shutterstock an einige Kontributoren
Hier werden „rechtliche Implikationen“ als Grund dafür genannt, dass etliche KI-Bilder der angeschriebenen Personen gelöscht wurden und es wird geschrieben, dass Shutterstock „keine maschinengenerierten Inhalte akzeptieren“ würde gemäß Sektion 13.d/f ihrer Nutzungsbedingungen.
Ich bin mir zwar nicht ganz sicher, ob sie da wirklich die richtigen Absätze rausgesucht haben, aber grundsätzlich steht es Shutterstock natürlich frei, solche Regeln aufzustellen, wenn sie der Meinung sind, dass sie hilfreich seien.
Zeitgleich experimentiert Shutterstock aber selbst schon mit künstlicher Intelligenz. So bietet deren neues Projekt „Predict“ Kunden die Möglichkeit, mittels KI erkennen zu können, welche Bilder für welche Zwecke am passendsten sein sollen. Shutterstock schreibt:
„Was performt besser? Diese wiederkehrende Frage ist mit Predict viel einfacher zu beantworten. Die App nutzt KI, um die Stärken und Schwächen individueller Assets speziell für Ihre Anforderungen zu analysieren. Predict sagt Ihnen, WARUM ein empfohlener Inhalt voraussichtlich gut performt, damit Sie selbstbewusst kreativ werden können.“
Nach einer kostenlosen Testphase wollen sie sich diese Informationen natürlich bezahlen lassen.
Getty Images versucht ebenfalls seit Januar 2022, die Vorteile der KI für sich auf eine andere Weise zu nutzen. So veröffentlichte die Agentur einen neuen Modelvertrag, der jetzt unter anderem einen neuen Passus enthält, mit dem sich das Model bereit erklärt, dass die Bilder zum Trainieren von Künstlicher Intelligenz genutzt werden dürfen:
„Ich erkläre mich ferner damit einverstanden, dass der Inhalt mit anderen Bildern, Texten, Grafiken, Filmen, Audio- und audiovisuellen Werken kombiniert und zur Entwicklung und Verbesserung von maschinellen Lernalgorithmen, künstlicher Intelligenz und anderen Technologien bearbeitet und genutzt werden darf.“
Auch bei der deutschen Bildagentur Westend61 werden die KI-Bilder als hoch problematisch angesehen und aus rechtlichen Gründen sollten diese momentan nicht akzeptiert werden. Mehr Informationen dazu sollen folgen.
Einige Online-Kunst-Communities wie Newgrounds, Inkblot Art und Fur Affinity haben ebenfalls das Hochladen von KI-Werken untersagt oder eingeschränkt.
Diese Bildlöschungen folgen einige Wochen nach der Veröffentlichung eines Teils des KI-Trainings-Datensatzes mit rund 12 Mio. Bildern von den insgesamt über 2,3 Milliarden Trainingsbildern. Dieser Trainingsdatensatz der Organisation LAION wurde zum Beispiel für das Anlernen der KI von NightCafe, Midjourney und Stable Diffusion genutzt.
In der Veröffentlichung wurde unter anderem deutlich, dass zum Lernen auch große Bildbestände der Bildagenturen benutzt wurden. So waren von den ausgewerteten 12 Mio. Bildern mindestens 497.000 von 123rf, 171.000 von Adobe Stock/Fotolia, 117.000 von PhotoShelter, 35.000 von Dreamstime, 23.000 von iStock, 22.000 von Unsplash, 15.000 von Getty Images, 10.000 von VectorStock, 10.000 von Shutterstock und so weiter. Die Dunkelziffer dürfte hier weit höher sein, da viele dort gekaufte Bilder auf Kundenwebseiten nicht immer als von einer Agentur kommend erkennbar sind.
Ich bin unsicher, ob diese Entscheidung so klug ist. Denn solche Verbote könnten dazu führen, dass sich die KI-Szene andere „Ökosysteme“ aufbaut. So gibt es beispielsweise mit PromptBase schon eine Webseite, wo Anbieter auf einem Marktplatz „Prompts“ für KI-Systeme verkaufen können. Prompts sind die Texteingaben, die zur Bilderstellung (noch) nötig sind und die Anbieter garantieren mit ihren Prompts ähnliche Ergebnisse wie die, die sie im Marktplatz vorzeigen. Im Kern ist das schon eine Art neuer Bildagentur, bei der die Leute nicht die Bilder direkt kaufen, sondern die Option, sich sehr ähnliche Bilder selbst gratis generieren zu können.
Außerdem erhöhen solche Einschränkungen wie das Verbot von KI-Bildern in den bestehenden Bildagenturen nur die Wahrscheinlichkeit, dass ein neues Start-Up eine neue Bildagentur aufmacht, welche offensiv einfach nur noch KI-generiertes Material verkauft.
Mit der Webseite Lexica gibt es auch schon eine Art „Open Source“-Community für KI-Bilder, wo Nutzer sich mehrere Millionen mit Stable Diffusion erstellte Bilder anschauen, durchsuchen und sehen können, welche Prompts zur Erstellung genutzt wurden. Von der Möglichkeit, diese Bilder direkt zur Lizenzierung anzubieten, ist es dann nur noch ein kleiner Schritt.
Während die großen Bildagenturen einen Abwehrkampf gegen die KI-Bilder beginnen, fangen andere Start-Ups längst an, mittels KI aus Text-Prompts ganze Video-Sequenzen zu erstellen.
Was diese KI-Entwicklung für die (Stock-)Fotografen selbst bedeutet, werde ich hoffentlich bald in einem eigenen Artikel beleuchten.
Wie seht ihr das? Bringen Verbote von KI-Bildern etwas?
Vor ca. einem Jahr habe ich mir einen neuen Computer gekauft. Zeitgleich passierten mehrere Dinge, die mein Vertrauen in meine Datensicherung und meine Backups stark auf die Probe gestellt haben.
Alle Unglücke kamen fast zeitgleich bzw. bauten aufeinander auf und erforderten verschiedene Arten der Datensicherung, welche ich glücklicherweise umgesetzt habe.
Meine Geschichte soll euch zeigen, was passieren kann und wie ihr euch dagegen absichern könnt.
Die Ausgangslage
Für meine Foto-Daten nutze ich als Datensicherung zwei externe „My Book Duo*„-Gehäuse mit 16 TB Kapazität, jeweils im RAID-1-Modus. Das heißt, die je zwei Festplatten in den Gehäusen speichern die identischen Daten, damit diese gesichert sind, sollte eine davon kaputt gehen. Deshalb ist die tatsächlich nutzbare Kapazität nur die Hälfte, in meinem Fall jeweils 8 TB.
Darüber hinaus nutze ich einen Online-Backup-Service, welcher sowohl die Daten dieser externen Gehäuse als auch alle meine internen Festplatten in der Cloud sichert.
Meine externen RAID-1-Speicher
Nach vier Jahren Dienst wurde mein bisheriger PC etwas schwach auf der Brust und ich gönnte mir einen neuen. Ich baute die Festplatten aus dem alten Rechner aus und setzte sie in den neuen ein, um die Daten auf die zwei neu gekauften 4TB-SSD* (ich gönn mir ja sonst nix) zu kopieren.
Die vier Fehler und Probleme
Nach der Installation des neuen Rechners meldete mir jedoch eine der nun dort angeschlossenen „My Duo“-Festplatten einen Fehler (Fehler 1). Ich konnte noch auf die Daten zugreifen, aber das System meldete, dass eine der beiden Platten nicht mehr lesbar sei. Also zog ich alle Daten sicherheitshalber sofort auf eine andere externe Festplatte, bestellte mir eine neue Festplatte, setzte diese in das „My Duo“-Gerät ein und ließ die Daten (wieder im RAID‑1) raufkopieren.
Im Zuge der Prüfungen merkte ich jedoch erschrocken, dass meine andere „My Duo“-Platte gar nicht im RAID-1-Modus lief, sondern nur im RAID‑0 (Fehler 2). Das heißt, ich hatte zwar den Speicherplatz von zwei Festplatten im Gehäuse, aber keine Redundanz der Daten.
Panisch kopierte ich alle Daten auf zwei weitere externe Festplatten (weil ich nicht genug Speicherplatz auf einer hatte), denn um den Modus zu wechseln, muss das „My Duo“ komplett neu formatiert werden.
Also Gerät formatiert, auf RAID‑1 gestellt und die Daten rüberkopiert. Dann kam mir jedoch etwas komisch vor. Im Vergleich zu vorher waren plötzlich ca. 520 GB an RAW-Daten weniger vorhanden (Fehler 3). Glücklicherweise nutze ich den Online-Backup-ServiceBackblaze*, der mir schon mehrmals den Arsch gerettet hatte, wenn ich zum Beispiel eine wichtige Photoshop-Datei mit einer unpassenden Version überschrieben hatte.
Backblaze bietet die Dateiwiederherstellung per Download oder durch die Zusendung eines USB-Sticks oder einer externen Festplatte an. Für die von mir benötigte Datenmenge (256 GB bis 8 TB) kam seitens Backblaze nur die externe Festplatte als Option in Frage.
Diese Festplatte kostete 189 USD, welche erstattet würden, wenn man die Festplatte innerhalb von 30 Tage nach Erhalt wieder zurück schickt. Das klappte bei mir ganz gut, ich musste also nur die Zoll-Einfuhrsteuer und das Porto für den Rückversand tragen (immerhin ca. 30–40 Euro zusammen, aber hey, 520 GB Daten). Die Festplatte wird übrigens verschlüsselt verschickt und kann nur mit dem Decryption-Key entschlüsselt werden, der im eigenen Backblaze Kundenbereich hinterlegt wird. So sind die Daten auch sicher, falls die Fesplatte beim Transport in die falschen Hände gerät.
Erschwerend kam hinzu, dass ich meinen neuen Computer wegen eines Defekts am Kühlsystem noch mal zur Reklamation einschicken musste. Die Reparatur dauerte einige Wochen, in denen jedoch mein Online-Backup nicht aktiviert werden konnte (Fehler 4).
(Nerd-Begründung: Weil ich das Backup-System schon auf den neuen Rechner übertragen hatte, änderten sich dadurch derHash-Wert der Platte und die vorhandenen wären Daten standardmäßig nach 30 Tagen überschrieben worden. Zwar hätte das System die (alten) Daten auf der neuen Platte noch mal neu gesichert, was aber bei der Datenmenge von einigen TB Daten mehr als 30 Tage gedauert hätte.)
Wäre mein neuer Rechner länger als 30 Tage in Reparatur gewesen, wäre Backblaze davon ausgegangen, dass ich die Daten nicht mehr benötige und hätte sie gelöscht. Deshalb habe ich in der Zeit gleich noch die verlängerte Dateiversion-Historie dazugebucht, welche die Daten nun ein Jahr lang speichert.
So hatte ich nach einigen Wochen Panik endlich wieder Ruhe und nebenbei den Fehler des falsch konfigurierten externen „My Duo“-Gehäuses behoben.
Die Analyse
Experten empfehlen für die Datensicherung in der Regel mindestens eine 3–2‑1-Sicherung. Das bedeutet: Sichere deine Daten mindestens 3x, auf 2 verschiedenen Datenmedien, davon 1x an einem anderen Ort.
Glücklicherweise hatte ich genau diesen Grundsatz beherzigt, der mir bei der Kombination der auftretenden Fehler den Arsch gerettet hat. Ich hatte drei Datensicherungen (2x auf den beiden Festplatten in einem My-Book-Duo-Gehäuse und 1x in der Cloud). Festplatte und Cloud sind zwei verschiedene Datenmedien und die Cloud ist auch woanders gesichert als die Festplatten.
Bei Fehler 1 ist eine der beiden Fesplatten des RAID-1-Verbunds abgeschmiert. Durch die zweite Festplatte mit den identischen Daten konnte ich diese retten.
Bei Fehler 2 hatte ich Glück, dass ich diesen früh genug bemerkt habe. Aber selbst wenn das komplette RAID‑0 plötzlich weg gewesen wäre, hätte ich alle Daten ja noch in der Cloud gesichert gehabt, also genau das, was mir bei Fehler 3 aus der Patsche geholfen hat.
Für Fehler 4 griff dann die erweiterte Vorhaltezeit des Online-Backup-Dienstleisters, damit ich auch Daten länger als 30 Tage wiederherstellen kann, die ich lokal schon gelöscht, überschrieben oder verändert habe.
Verbesserungsbedarf
Selbst in so einem komplexen Problemgemenge wie oben beschrieben konnte ich mich durch meine vorhandene Datensicherung ganz gut aus der Affäre ziehen.
Ich gebe aber zu, dass mein System nicht perfekt und vermutlich auch nicht für alle die beste Lösung ist. Das liegt an mehreren Details:
Das Hauptproblem bei den My Book-Duo-Geräten ist, dass die Daten dort standardmäßig hardwareseitig verschlüsselt werden. Man kann also wie in meinem Fall zwar eine neue Festplatte einsetzen, um eine defekte zu ersetzen, aber man kann nicht die funktionierende Festplatte ausbauen, um sie in einem anderem PC auszulesen. Sollte also nicht die Festplatte im Gerät einen Fehler haben, sondern zum Beispiel der Hardware-Controller vom Gerät selbst, sind beide Backups futsch (deshalb ja zusätzlich das Cloud-Backup). Es gibt andere Systeme, wie RAID-1-Gehäuse von Icy Box* oder Fantec*, welche jedoch etwas weniger komfortabel sind und man sich selbst um passende Festplatten* kümmern muss.
Auch beim Cloud-Backup gibt es Einschränkungen. Der von mir genutzte Backup-Dienst Backblaze* ist zwar sehr günstig (55 USD pro Jahr für unbegrenzten Speicherplatz), erfordert dafür aber, dass die gesicherten Festplatten über den PC regelmäßig mit dem Internet verbunden sind (standardmäßig mindestens alle 30 Tage, mit erweiterter „Version History“ mindestens 1x im Jahr). So soll verhindert werden, dass man die externen Festplatten, welche man im Bankschließfach lagert, auch in der Cloud gesichert werden können.
Außerdem erfordert der erste Upload der ganzen Daten je nach Datenmenge und Internet-Bandbreite meist einige Wochen bis mehrere Monate. Bei mir waren es zum Beispiel auch mit 20 Mbit Upload über drei Monate, bis alle Daten (mehrere Terabyte) gesichert waren. Für Leute mit langsamer Internetleitung empfiehlt sich daher eventuell eine andere Sicherungsmöglichkeit.
Dazu kommt, dass man seinem Backup-Anbieter vertrauen muss, die Daten sicher und privat aufzubewahren.
Jedes Backup ist nur so gut wie der Praxistest
Ein Backup ist nur dann mit ruhigem Gewissen nutzbar, wenn sichergestellt ist, dass die Wiederherstellung der Daten im Ernstfall auch funktioniert.
Insofern war ich froh, dass bei mir gleich mehrere Dinge richtig liefen:
Die defekte Festplatte im RAID-1-Verbund wurde ordnungsgemäß gemeldet und die neu eingesetzte problemlos ins System integriert.
Durch Abgleich der Festplattenbefüllung habe ich meinen Datenverlust sofort bemerkt.
Die Zusendung der externen Festplatte mit meiner Datensicherung durch den Online-Backup-Dienst funktionierte tadellos. Auch den einzelnen Datei-Download muss ich zwangsweise meist 2–3x im Jahr wegen meiner Schusseligkeit „testen“.
Wichtig ist auch, selbst zu wissen, welche Daten ihr überhaupt sichern müsst oder wollt und wo sich diese befinden. Ich habe in diesem und diesem Artikel aufgelistet, was ich wie genau sichere.
Nun seid ihr dran: Wie sichert ihr eure Daten? Was könnt ihr mir empfehlen? Oder ist dies ein guter Zeitpunkt, eure Daten selbst mal wieder zu sichern?
Der Suchalgorithmus einer Bildagentur gehört zu den stärksten Betriebsgeheimnissen. Besonders pikant ist das, weil dieser Algorithmus wesentlich darüber entscheidet, ob man als Fotograf mit dieser Bildagentur viel Geld verdient oder nicht (YouTuber können da ein Lied von singen).
Weil dieser Suchalgorithmus so geheim ist, kann man nur Mutmaßungen darüber anstellen, welche Kriterien genau relevant sind, um bei einer Bildersuche weit oben zu erscheinen.
Manchmal geben die Entwickler jedoch selbst einen seltenen Einblick in ihre Arbeit. So kürzlich bei diesem sehr spannenden Artikel von Fengbin Chen, Machine Learning Engineer bei Adobe.
In diesem Artikel werden erstens einige beobachtete Verhaltensweisen von Bildkäufern aufgezählt. Dazu zählen zum Beispiel:
Kunden scrollen selten in den Suchergebnissen und schauen selten mehr als die erste Seite der Suchergebnisse an
Abo-Kunden benutzen häufig die gleichen Suchbegriffe, jedoch mit anderen geplanten Endnutzungen im Hinterkopf, weshalb die Topresulte nicht die gleichen bleiben sollten
Kunden laden Bilder oft runter, um diese weiterzuverarbeiten, viele suchen nach Inspirationen durch Stock-Bilder, die sie für ihre finalen Projekte bearbeiten können
Bilder auf der ersten Trefferposition haben mehr als zehn Mal zu viele Downloads wie Bilder auf der dreizehnten Trefferposition.
Mehr als die Hälfte aller Downloads erzielen Bilder im oberen Drittel der Suchergebnisse
Es gibt eine „Positionsbefangenheit“ (Position Bias), das heißt, Kunden kaufen lieber Bilder aus den oberen Suchergebnissen als aus den unteren, unabhängig von der Bildqualität und Relevanz.
Ein Kunde lädt eher das 100. Bild (das letzte einer Seite) als das 95. Bild und wenn sie auf die zweite Seite gehen, eher eins aus den oberen Positionen der zweiten Seite als aus den unteren Positionen der ersten Seite.
Ebenfalls sehr spannend ist der seltene Einblick, wie das Adobe Stock Team auf die oben genannten Verhaltensweisen reagiert. Damit geben sie einen nützlichen Einblick in die Denkweise der „Hüter des Algorithmus“:
Das Team hat ein neues Ranking-Feature hinzugefügt mit dem Namen „unbiased DTR“. DTR steht für „Download-through-rate“. Die Idee dahinter ist, dass bisher die Anzahl der Verkäufe ins Verhältnis zu den Views bei den Suchergebnissen gesetzt wurde. Ein Bild, was genauso oft angezeigt wurde wie ein anderes, aber häufiger gekauft wurde, bekam in der Zukunft einen höheren Platz. Das berücksichtigte aber noch nicht den Fakt, dass die Kunden die oberen Bilder unabhängig von der Bildqualität bevorzugten, weshalb sich diese Topseller oben festsetzten und kaum von neueren, eventuell besseren Bildern ablösen ließen.
Beim „unbiased DTR“ wird das nun berücksichtigt, indem die Anzeigeposition mit einfließt in das Verhältnis. Zum Beispiel wird ein Bild auf dem Platz eins der Suchergebnisse als „ein View“ gezählt, während ein Bild auf der 30. Position nur als „ein Fünftel View“ gezählt wird, weil die Neigung, das erste Bild zu kaufen, fünf Mal höher ist als die, das 30. Bild zu kaufen.
Zusäzlich zu diesem Faktor spielen natürlich noch viele andere Faktoren wie Alter des Bildes, Suchbegriffe, Portfoliogröße und so weiter eine Rolle.
Als Ergebnis wird im Artikel dieses Vorher-Nachher-Beispiel gezeigt:
Vorher-Nachher-Vergleich des „unbiased DTR“-Ranking Features bei Adobe Stock
So sehr ich den Einblick in die Arbeitsweise des Such-Teams zu schätzen weiß, so sehr bin ich doch vom Ergebnis enttäuscht. Es wird behauptet, das Nachher-Ergebnis würde mehr Diversität und Variationen zeigen. Ich bin da einer anderen Meinung.
Die Firma icons8 hat gerade etwas Bahnbrechendes gemacht: Sie hat 100.000 durch künstliche Intelligenz erstellte Portraits kostenfrei zur Nutzung bereit gestellt.
Die künstliche Intelligenz brauchte etwas zum „Trainieren“, um zu erkennen, wann ein Ergebnis menschlich genug aussah und wann nicht. Dafür hat die Firma nach eigenen Angaben innerhalb von drei Jahren 29.000 Portraits von 69 Models aufgenommen.
Die fertigen computergenerierten Fotos werden auf der Webseite https://generated.photos/ kostenfrei zum Download und zur Nutzung angeboten im Format 1024x1024 Pixel, also 1 Megapixel. Bei den 100.000 Bildern sind einige dabei, die erkennbar „fake“ sind, weil der Computer seltsame Artefakte an komischen Stellen generiert hat und oft sind bei langen Haaren die Enden falsch, wie wenn man wild in Photoshop mit dem Klonstempel Amok gelaufen wäre oder das Verflüssigen-Tool nicht richtig beherrscht.
Alles AI-basierte künstliche Gesichter von generated.photos
Das soll aber nicht darüber hinweg täuschen, dass viele der Bilder nicht mehr von einem echten Foto zu unterscheiden sind. Geplant ist in Zukunft sogar eine Art Tool, mit der Nutzer (vermutlich gegen Gebühr) auf Knopfdruck sich selbst Portraits generieren und dabei Kriterien wie Geschlecht, Alter, Stimmung, Blickwinkel etc. selbst beeinflussen können.
In diesem Video stellt sich das Projekt kurz selbst vor:
Hier als Beispiel einige Bilder von https://generated.photos, die tatsächlich so realistisch sind, dass kaum vorstellbar ist, dass sie keine Fotos sind (Klicken zum Vergrößern):
Wer ebenfalls mal stöbern will, kann die Webseite https://100k-faces.glitch.me/ aufrufen. Bei jedem neuen Laden der Seite wird zufällig eins der 100.000 Gesichter gezeigt.
Wie dürfen die Bilder genutzt werden?
Laut der Webseite dürfen die Bilder für jegliche („whatever“) Nutzung verwendet werden, zum Beispiel für Präsentationen, Projekte, Mock-Ups, Avatare auf Webseiten, Newsletter, Arbeitsblätter etc., vorausgesetzt, es wird ein Link auf deren Webseite gesetzt. Konkreter erklärt es der Chefdesigner bei icons8, Konstantin Zhabinskiy hier:
„If you plan to use photo on your website, set a link to Generated Photos on all pages where you use our content. If you use it on most pages, a link in your footer is fine. Desktop and Mobile apps should have a link in the About dialog or Settings. Also, please credit our work in your App Store or Google Play description (something like „Photos by Generated Photos“ is fine).“
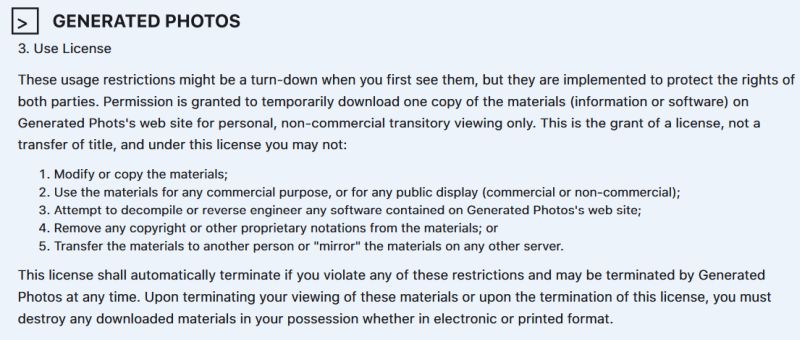
In den kleingedruckten Nutzungsbedingungen auf der Seite steht unter Punkt 3.2 jedoch, dass keine „kommerzielle Nutzung“ erlaubt sei und generell viele Einschränkungen gelten, wie zum Beispiel dass die Lizenz seitens der Betreiber jederzeit entzogen werden kann und dann jedes Material, egal ob digital oder gedruckt, zerstört werden muss:
Das widerspricht sich jedoch mit den öffentlichen Äußerungen der Firma, weshalb ich per Email um eine Stellungnahme gebeten habe, auf die ich leider noch keine Antwort habe.
In deren FAQ wird darauf hingewiesen, dass das Verfassen von Nutzungsrechten für Produkte künstlicher Intelligenz eine Neuheit ist, weshalb sie sich das Ändern dieser Nutzungsbedingungen jederzeit vorbehalten. Wenn man kurz darüber nachdenkt, ist es logisch: Mit welchem Recht sollte jemand das Urheberrecht an Werken beanspruchen, die er nicht selbst geschaffen hat? Das wird noch Stoff für juristische Auseinandersetzungen liefern.
Eine andere Webseite ist www.artificialtalent.co, bei der Modefotos gegen Bezahlung mit künstlich erzeugten Gesichtern „aufgehübscht“ werden können, um mehr Kleidung zu verkaufen.
Eine große Sammlung solcher AI-basierten Webseiten, nicht nur für Personenbilder, liefert diese Webseite.
Was bedeuten diese Projekt für die Stockfotografie?
Kurzfristig sind sie noch keine Bedrohung für Stockfotografen. Erstens funktioniert diese Technik aktuell nur bei Portraits und die Auflösung ist mit 1 MP etwas beschränkt. Der Ausschuss ist, wie man beim Durchblättern der 100.000 Bilder sehen kann, noch ziemlich groß, auch wenn erstaunliche Ergebnisse darunter sind. Außerdem ist nur eine private Nutzung erlaubt, weshalb Werbetreibende weiterhin auf Stockmaterial zurückgreifen müssen.
Mittelfristig sehe ich jedoch durchaus die Möglichkeit, dass ein Teil der Nutzung zu den computergenerierten Bildern abwandert. Erstens sind diese künstlichen Intelligenzen schnell lernfähig, was zu exponentiell besser werdenden Ergebnissen und steigenden Bildauflösungen führen sollte. Die Technik wurde immerhin erst 2014 vorgestellt und kann nun schon glaubwürdige Gesichter generieren.
Außerdem funktioniert die Technik nicht nur bei Menschen, auch Landschaften lassen sich so digital erzeugen, wie diese interaktive Demo von Nvidia zeigt. Selbst für Inneneinrichtungen gibt es schon eine Webseite, bei der Leute ein Foto ihrer Wohnung hochladen können und die AI richtet diese virtuell neu ein.
Die Gefahr für Stockfotografen besteht darin, dass ihre Bilder oft sehr generisch und austauschbar sind, beides also Attribute, welche perfekt für computergenerierte Ansätze sind.
No Model Release, no problem?
Wie bei etlichen neuen Technologien zeigen sich Gefahren leider erst, wenn diese eine Weile im Einsatz sind. Deshalb betonen einige Forscher aus diesem Gebiet, dass die ethische Komponente nicht unterschätzt werden darf. Das heißt im Klartext: Die erzeugten Bilder basieren auf echten Fotos: Wird die AI nur mit schönen, kaukasischen jungen Gesichtern trainiert, werden auch die Ergebnisse schön, jung und weiß sein. Nur wer genügend Diversität im Ausgangsmaterial hat, kann diese auch vom Computer erzeugen lassen.
Eine weitere, bisher nicht erwähnte Gefahr, sehe ich in den Persönlichkeitsrechten. Klar, die abgebildeten Personen haben keine Persönlichkeitsrechte. Wer sich eine Weile durch die Beispiele klickt, wird jedoch merken, dass ihm etliche Gesichter irgendwie bekannt und vertraut vorkommen. Es kann ja sein, dass der Computer Gesichter generiert, die in echt lebenden Menschen wie aus dem Gesicht geschnitten aussehen. Sollten diese Menschen dann nicht das Persönlichkeitsrecht an den AI-Bildern haben, wenn sie mit denen verwechselt werden können? Man könnte den Vergleich zu eineiigen Zwillingen ziehen: Hat der eine das Recht, dem anderen abzusprechen, für bestimmte Produkte oder Meinungen zu werben?
Generell ist das Missbrauchspotential dieser Technik sehr hoch, man denke nur an ausgedachte Testimonials, gefälschte Social Media Accounts und so weiter. Vor allem in Kombination mit anderen Techniken wie „Deep Fakes“, bei der Videos Gesichter anderer Personen erhalten oder Adobe #VoCo, wo Stimmen anderer Personen manipuliert werden können, ergeben sich viele Möglichkeiten, die sehr dazu geeignet sind, das Vertrauen von Menschen in digitale Inhalte zu untergraben. Wie so oft sind Pornos Vorreiter dieser neuen Technologie: Schon heute gibt es einige Webseiten, auf der Gesichter von Berühmtheiten in Pornofilme montiert werden.