Seit Tagen ist in der KI-Welt kaum von etwas anderem die Rede als den beeindruckenden Ergebnissen von Sora.
Sora ist der Name des kürzlich hier vorgestellten Text2Video-Generators der Firma OpenAI, welche auch schon den Text2Bild-Generator Dall‑E und das Text2Text-Generator ChatGPT veröffentlicht hat.
Standbild aus einem Sora-Video [Montage]
Mit Sora können durch simple Texteingaben hochauflösende Videos von bis zu einer Minute Länge generiert werden.
Einen Überblick über die Ergebnisse findet ihr haufenweise, entweder auf der Sora-Seite direkt oder bei YouTube, zum Beispiel in diesem Video:
Ki-Videos, mittels Sora von OpenAI generiert
Auf der offiziellen Webseite wird lang und breit über die Sicherheit des Tools geredet und gerne erwähnt, dass geplant sei, den C2PA-Metadaten-Standard zur Erkennung von KI-generierten Inhalten zu unterstützen. Auffällig ist aber, dass andere Informationen fehlen.
Das Geheimnis der Trainingsdaten
Auffällig ist, dass an keiner Stelle der Vorstellung von Sora darauf eingegangen wird, wie genau das KI-Tool trainiert wurde. Welche Daten wurden dafür verwendet?
Im technischen Report findet sich nur der lapidare Satz: “[…] we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios.“
Ach? Ja, das war uns allen klar, aber welche Videos und Bilder habt ihr dafür nun genau benutzt?
In der Vergangenheit hat sich OpenAI nicht mit Ruhm bekleckert, wenn es um Rücksicht auf Urheberrechte bei Trainingsdaten ging.
Auch beim zweiten Produkt von OpenAI, ChatGPT, liegt die Sache ähnlich. OpenAI wird gerade von der Zeitung New York Times verklagt, weil urheberrechtlich geschützte Trainingsdaten der Zeitung für das KI-Training von ChatGPT benutzt worden seien.
Bei einer Zeugenanhörung von OpenAI durch das Oberhaus des britischen Parlaments fiel seitens OpenAI auch der folgenschwere Satz:
„Because copyright today covers virtually every sort of human expression–including blog posts, photographs, forum posts, scraps of software code, and government documents–it would be impossible to train today’s leading AI models without using copyrighted materials. Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today’s citizens“
Frei übersetzt: Ohne den Zugriff auf urheberrechtlich geschützte Trainingsdaten könnten wir unsere Tools nicht anbieten.
Genau wegen diesem bisher schon bekannten rücksichtslosen Umgang mit Urheberrechten muss eine Frage viel lauter gestellt werden:
Welche Videos und Bilder wurden für das Training der Sora-KI verwendet?
Die Wahrscheinlichkeit ist sehr hoch, dass auch hier – ähnlich wie beim Training von Dall‑E und ChatGPT urheberrechtlich geschützte Videos (und Bilder) zum Einsatz kamen.
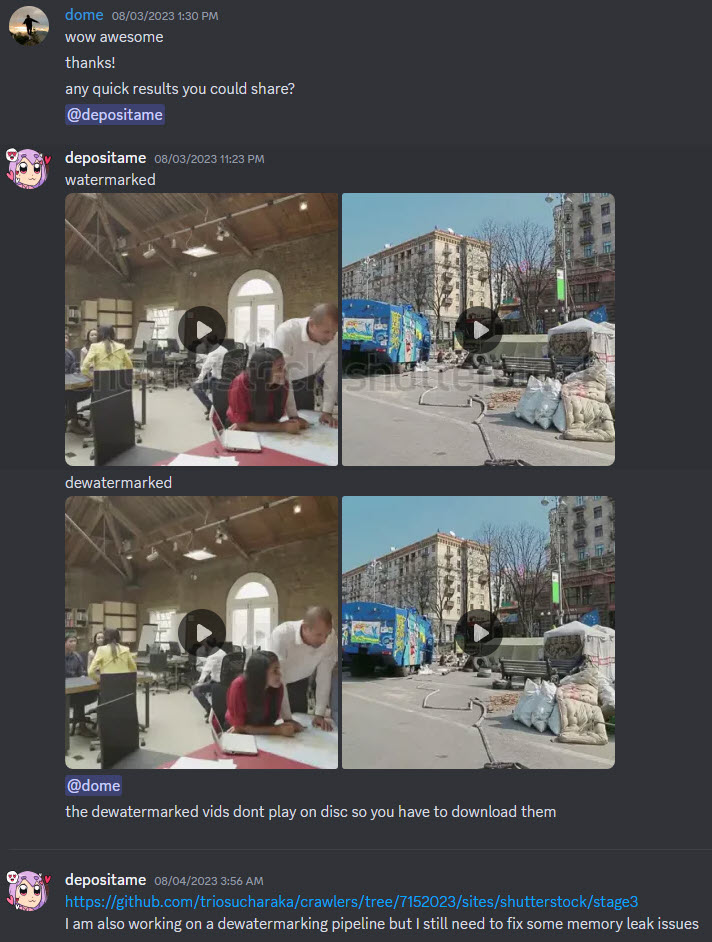
Selbst Wasserzeichen in Videos sind für KI-Entwickler schon lange kein Hindernis mehr. Schon 2017 hat Google selbst eine Technik vorgestellt, mit der Wasserzeichen aus Bildern entfernt werden können.
Auch der LAION-Verein bietet auf GitHub ein kostenloses Tool für die „Wasserzeichen-Erkennung“ an. Von der Erkennung zur Entfernung ist es für geübte Programmierer dann nur noch ein kleiner Schritt, über den aus rechtlichen Gründen nicht so gerne öffentlich geredet wird. Manchmal aber doch:
Aus dem #video-generation Kanal des Discord-Servers von LAION
Aus dem #video-generation Kanal des Discord-Servers von LAION
Bei LAION wird zwar an einem eigenen Text2Video-Generator namens phenaki gearbeitet, die technischen Details des Trainings sind denen von Sora aber sehr ähnlich, soweit ich das beurteilen kann.
Die Wahrscheinlichkeit, dass OpenAI daher mit der gleichen Rücksichtslosigkeit wie LAION gegenüber Urhebern beim KI-Training vorgeht, halte ich für hoch, zumal die bisherigen Aussagen und Handlungen von OpenAI leider nicht geeignet sind, Zweifel zu zerstreuen.
Beim ganzen Hype vom SORA und dem Staunen über die tollen Ergebnisse sollte nicht vergessen werden zu fragen, welche (Video-)Künstler beim Training beteiligt waren.
Am Donnerstag, den 30.03.2023 findet der diesjährige PICTAday in der Alten Kongresshalle in München statt von 10–18 Uhr.
Der PICTAday ist eine einmal jährlich stattfindende Networking-Veranstaltung des renommierten Branchenverbandes BVPA und feiert dieses Jahr sein 20-jähriges Bestehen.
Beim PICTAday können sich Bildagenturen und Dienstleister den Bildeinkäufern präsentieren und letztere sich über Neuigkeiten in der Agenturlandschaft und dem Bildermarkt informieren. Der Eintritt ist für Bildeinkäufer kostenfrei.
Auf dem PICTAday finden auch die PICTAtalks statt, wo namenhafte Branchenexperten neue Impulse zu aktuellen Entwicklungen der Bilderbranche und einen Einblick in ihre tägliche Arbeit geben.
Von 15–15:45 Uhr werde ich dort zusammen mit dem Fachanwalt für Urheber- und Medienrecht, Sebastian Deubelli von der SLD Intellectual Property Rechtsanwaltsgesellschaft über das Thema „DALL- E, Midjourney und Co.: Sind künstlich erzeugte Bilder auf dem Bildermarkt handelbar?“ diskutieren:
„Die Qualität von künstlich erzeugten Bildern wird besser und besser und stellt längst kein Hindernis für deren alltäglichen Einsatz dar. Aus rechtlicher Sicht ist vieles allerdings noch unklar. Der Talk beschäftigt sich insbesondere mit der Frage, ob die rechtliche Unklarheit dem gewohnten Handel mit Bildlizenzen im Weg steht und welche rechtlichen aber auch praktischen Vorkehrungen hier getroffen werden sollten.“
Der PICTAday ist eine großartige Gelegenheit, um sich über die neuesten Entwicklungen auf dem Bildermarkt zu informieren, wertvolle Kontakte zu knüpfen und an den hochkarätigen Vorträgen teilzunehmen.
Wir freuen uns auf eine spannende Diskussion und hoffen, euch am 30. März 2023 auf dem PICTAday in München zu treffen! Weitere Informationen zur Veranstaltung und zur Anmeldung sowie das Anmeldeformular findet ihr auf der Webseite des PICTAday.
Meine geplanten Artikel zu den neusten KI-Entwicklungen sind noch nicht mal fertig, da platzen ständig aufregende Neuigkeiten herein. Die Nachricht vom 25.10.2022 von Shutterstock kann ich hier aber nicht ignorieren, da sie einen wilden Mix von Konsequenzen nach sich zieht, den ich hier vermutlich nur ansatzweise beleuchten kann.
Aber versuchen wir es der Reihe nach: Shutterstock hat vor wenigen Tagen diese Pressemitteilung veröffentlicht, in der die Firma die Partnerschaft mit dem Unternehmen OpenAI verkündet, welche hinter dem KI-Tool DALL‑E stecken. Hinter OpenAI stecken übrigens u.a. Elon Musk als Gründer und Microsoft als Investor.
Bild von DALL‑E 2 generiert mit der Beschreibung „A tornado made of cash hitting a government building“
Zeitgleich gab es eine Rundmail an alle Shutterstock-Anbieter, in der zusätzlich zur obigen Information eine ebenso wichtige weitere Nachricht steckte: Shutterstock will keine KI-generierten Inhalte mehr auf ihrem Marktplatz anbieten, mit der Begründung, dass „die Urheberschaft nicht einer einzelnen Person zugeordnet werden kann, wie es für die Lizenzierung von Rechten erforderlich ist“.
Oder hier im Hilfebereich von Shutterstock noch ausführlicher begründet: „KI-generierte Inhalte dürfen nicht auf Shutterstock hochgeladen werden, da KI-Inhaltsgenerierungsmodelle das geistige Eigentum vieler Künstler und ihrer Inhalte nutzen, was bedeutet, dass das Eigentum an KI-generierten Inhalten nicht einer Einzelperson zugewiesen werden kann und stattdessen alle Künstler entschädigt werden müssen, die an der Erstellung jedes neuen Inhalts beteiligt waren“.
Diese Kombination von Aussagen wirft so viele Fragen auf, dass ich gar nicht weiß, wo ich anfangen soll.
Gehen wir mal in der Zeit etwas zurück: Shutterstock kooperiert schon seit 2021 mit der Firma OpenAI, indem OpenAI Shutterstock-Bilder lizenziert hat, um das Tool DALL‑E zu trainieren. Der CEO von OpenAI, Sam Altman, sagt dazu in der Pressemitteilung:
„Die Daten, die wir von Shutterstock lizenziert haben, waren entscheidend für das Training von DALL‑E. Wir freuen uns, dass Shutterstock seinen Kunden die DALL-E-Bilder als eine der ersten Anwendungen über unsere API zur Verfügung stellt, und wir freuen uns auf künftige Kooperationen, wenn künstliche Intelligenz ein integraler Bestandteil der kreativen Arbeitsabläufe von Künstlern wird.“
In wenigen Monaten sollen Shutterstock-Kunden in der Lage sein, mit Hilfe von OpenAI direkt auf der Shutterstock-Webseite durch Texteingabe Bilder selbst generieren zu können.
Im Gegenzug dafür sollen die Shutterstock-Anbieter für die Rolle, die ihre Inhalte bei der Entwicklung dieser Technologie gespielt haben, entschädigt werden.
Die erste Frage hier ist doch: Wurden die Shutterstock-Anbieter auch für die Trainingsdaten, die seit 2021 von OpenAI lizenziert wurden, entschädigt?
Die zweite Frage ist: Haben die Künstler, auf deren Eigentum Shutterstock angeblich so viel Wert lege, damals überhaupt zugestimmt, dass ihre Bilder für Trainingszwecke genutzt werden dürfen?
Die dritte Frage ist logischerweise: Wie viele Bruchteile von US-Cents sollen die Anbieter als „Entschädigung“ erhalten?
Ich könnte jetzt eine Weile mit solchen Fragen weitermachen, aber betrachten wir erst mal andere Perspektiven.
Die Kunden-Sicht
Aus Kundensicht erschließt sich nicht sofort, warum sie KI-Bilder bei Shutterstock – sehr vermutlich gegen Geld – generieren sollten, wenn sie es bei OpenAI auch kostenlos machen können. Jeden Monat gibt es bei DALL‑E 2 kostenlos 15 Credits für je Bilderstellungen (1 Credit pro Bild), 115 weitere Credits kosten dann 15 USD, also ca. 13 US-Cent pro Bild.
Es könnte auch sein, dass Shutterstock diesen Preis noch mal unterbieten will.
Darüber hinaus gibt es aber gänzlich kostenlose KI-Tools wie Stable Diffusion (und passende GUIs), mit der Nutzer ihre Bilder komplett gratis erstellen können.
Der Vorteil wäre maximal, wenn Kunden mit Shutterstock eine Firma haben, die für eventuelle (rechtliche?) Probleme haften könnte. Ansonsten spekuliert Shutterstock vielleicht darauf, dass es genug Bestandskunden gibt, welche sich nicht die Mühe machen (wollen), sich bei einer Plattform wie Dall‑E 2 zu registrieren, um dort die Gratis-KI-Bilder zu nutzen.
Die Agentur-Sicht
Aus Sicht von Shutterstock ist es natürlich clever: Warum sollten sie diese nervigen Bildlieferanten bezahlen müssen, wenn sie den Kunden auch ohne den Umweg über die Fotografen Bilder verkaufen können?
Das geht natürlich nur, wenn gleichzeitig den Anbietern verboten wird, KI-generierte Bilder selbst zum Verkauf anzubieten, denn immerhin will das ja die Agentur übernehmen. Warum die angeblichen rechtlichen Risiken, welche als Grund für das Upload-Verbot vorgeschoben werden, plötzlich nicht mehr gegeben sind, wenn Shutterstock die KI-Bilder generiert, erschließt sich nicht ganz. Dazu später mehr.
Das Verbot ist augenscheinlich vor allem dazu da, um mehr Kunden zur agentureigenen KI-Generierung zu bewegen.
Zwar hat Shutterstock schon „Entschädigungen“ für die Shutterstock-Künstler angeboten, deren Werke zum Training der KI benutzt werden, aber machen wir uns nichts vor: Das werden pro Bild maximal etliche Stellen hinter dem Komma sein und auch in der Summe deutlich weniger sein als die Verluste, welche die Anbieter erleiden werden, weil Kunden keine Bilder aus dem Portfolio kaufen, sondern sich welche generieren lassen und die Fotografen auch selbst keine KI-Bilder verkaufen dürfen.
Zur Erinnerung: Als Getty Images 2013 einen Deal mit Pinterest machte, um die Getty-Fotografen für deren Bildnutzungen auf Pinterest zu entschädigen, erhielten diese zum Beispiel 0,00062 USD für das „weltweite Recht, Metadaten ihres Bildes auf Pinterest anzuzeigen und zu nutzen“, während Getty selbst sich immerhin noch 0,00411 USD in die Tasche steckte. Anders gerechnet: Bei 1000 Bildnutzungen waren das für den Fotografen 62 Cent und für Getty Images aber 4,11 USD.
Die Konkurrenz ist zudem groß: Auch Microsoft will DALL‑E in deren Suchmaschine Bing integrieren und hat eine neue App namens „Designer“, die Produkt- oder Firmennamen und die dazu passenden Bilder oder Logos generieren können soll.
Bild von Stable Diffusion generiert mit der Beschreibung „A tornado made of cash hitting a government building“
Die Anbieter-Sicht
Für Shutterstock-Anbieter sind diese Nachrichten ausnahmslos schlecht. Die „Entschädigung“ ist ein armseliges Feigenblatt, hinter dem Shutterstock die Marginalisierung ihrer Lieferanten versteckt. In der Pressemitteilung wird ständig von „Ethik“ und „Verantwortung“ geredet, aber damit ist nicht die Rücksicht auf die Anbieter gemeint, sondern auf die der Shutterstock-Aktionäre.
Shutterstock hat halt endlich einen Weg gefunden, die lästigen 20% Fotografen-Kommissionen auch noch loszuwerden, um es lapidar zu formulieren.
Die genannte „Entschädigung“ soll aus einem „Contributor Fund“ kommen und alle sechs Monate ausgezahlt werden. Als Einnahmen dafür sollen sowohl die Lizenzgebühren für die KI-Inhalte als auch Einnahmen aus Datenverkäufen gezählt werden. Der Anteil für die Anbieter soll proportional sein zum Volumen ihrer Inhalte in den Datensätzen.
Wie das kontrolliert oder überprüft werden soll, ist auch völlig schleierhaft und vermutlich unmöglich ohne die Offenlegung des kompletten Datensatzes.
Wenn Shutterstock und Getty Images keine KI-Bilder haben wollen, wird es aber weiterhin genug andere Agenturen geben, welche diese mit Kusshand annehmen. Es drängen jetzt schon die ersten Bildagenturen auf den Markt wie StockAI, welche nur KI-Bilder anbieten und diese natürlich auch generieren können.
Die Künstler-Sicht
In der o.g. Pressemitteilung heißt es zum Schluss:
„Und in einem wichtigen Bestreben, die IP-Rechte seiner Künstler, Fotografen und Schöpfer zu schützen, ist Shutterstock weiterhin führend in der Entwicklung von Richtlinien und Verfahren und setzt Methoden ein, um sicherzustellen, dass Nutzungsrechte und ordnungsgemäße Lizenzen für alle vorgestellten Inhalte – einschließlich KI-generierter Inhalte – gesichert sind.“
DALL‑E wurde mit über 12 Milliarden Text/Bild-Kombinationen trainiert, während Shutterstock gerade mal 424 Millionen Bilder online hat. Das heißt im Umkehrschluss, der größte Teil des Trainings wurden mit Bildern von Künstlern gemacht, die nicht bei Shutterstock sind. Das ganze Gerede vom „Schützen von IP-Rechten“ bezieht sich aber nur auf die Shutterstock-Anbieter, der große Rest kann zusehen, wie für die KI-Trainings „entschädigt“ wird.
Das zeigt auch gut die Heuchelei von Shutterstock. Angeblich weil bei KI-Inhalten alle Künstler entschädigt werden müssten, dürfen Anbieter keine KI-Inhalte hochladen, aber wenn Shutterstock selbst via API einen Zugang zu OpenAI’s DALL‑E anbietet, werden ebenfalls nicht alle Künstler entschädigt.
Die rechtliche Sicht
Ist die Entschädigung von Künstlern, deren Werke für das KI-Training benutzt wurden, rechtlich gesehen überhaupt notwendig? Ich weiß es ehrlich gesagt nicht. Einige meinen, das sei eine klassische „fair use“-Nutzung, andere sehen es nicht so.
Mal angenommen, rechtlich wäre eine Entschädigung nicht notwendig: Dann fallen Shutterstocks Argumente, warum sie keine KI-Bilder annehmen wollen, in sich zusammen.
Wenn eine Entschädigung rechtlich aber doch notwendig wäre: Dann ist vollkommen unbegreiflich, warum sich diese erstens nur auf Shutterstock-Künstler beschränken sollte (und nicht z.B. auf Künstler wie Greg Rutkowski) und zweitens warum diese nicht stattfindet, wenn Bilder direkt bei DALL‑E generiert werden statt über deren API zu Shutterstock.
Es ist also so oder so ein großes unlogisches Konstrukt, welches sich am besten dadurch erklärt, dass es Shutterstock eben nicht um die Belange der Künstler, sondern nur um den eigenen Profit geht.
Spannend auch, dass der Getty Images-CEO Craig Peters KI-Bilder u.a. deshalb in seiner Agentur verbietet, weil sie rechtliche Probleme für die Kunden mit sich bringen könnten. Warum das anders sein soll, wenn Shutterstock Kunden KI-Bilder generieren lässt, ist ein großes Rätsel.
Eine mögliche Lösung wäre, dass die OpenAI-KI ausschließlich auf Shutterstock-Bildern trainiert wurde, für die sowohl Shutterstock die Einwilligung aller Rechteinhaber zum Training hatte als auch OpenAI diese Rechte lizenziert habe. In den aktuellen Shutterstock-AGB von 2020 steht beispielsweise, dass Shutterstock das Recht zur Bildanalyse unterlizenzieren darf. Aber selbst wenn OpenAI jedes einzelne Bild aus der Shutterstock-Datenbank lizenziert habe, würde das bei vermutlich weitem nicht ausreichen, um als alleinige Datenbasis für das KI-Training zu dienen.
Aber vielleicht liege ich damit auch falsch und es ist sogar ein Vorteil, weil die Shutterstock-Bilder alle eine hohe Auflösung haben und im Vergleich zu anderen Bildern meist recht gut verschlagwortet sind.
Auch die EU hat im Blick, dass die Künstliche Intelligenz gefährlich sein könnte und arbeitet an einer „KI-Verordnung“. Ob solche Verordnungen aber den aktuellen Graubereich der Legalität von urheberrechtlich geschützten Werken für KI-Trainingszwecke regulieren werden, bleibt abzuwarten.
Bild von Midjourney generiert mit der Beschreibung „A tornado made of cash hitting a government building“
Die politische Sicht
Shutterstock wurde 2019 von den eigenen Mitarbeitern kritisiert, dass die Agentur in China Suchbegriffe wie „Flagge Taiwans“, „Diktator“, „Präsident Xi“ oder „Regenschirm“ gesperrt habe.
Sehr spannend ist hier jetzt die Frage, ob diese Begriffe dann auch bei der KI-Generierung in China gesperrt sein werden oder nicht.
Auch andere Begriffe, zum Beispiel sexueller oder gewaltverherrlichender Natur, könnten gesperrt werden, um sich weniger Haftungsfragen aussetzen zu müssen.
Die technische Sicht
Viele der genannten Tools sind aktuell noch im Beta-Stadium und sie entwickeln sie unglaublich rasant. Es ist vermutlich nur eine Frage der Zeit, bis Methoden wie das In- und Outpainting von DALL‑E 2 auch in Grafikprogramm wie Adobe Photoshop Einzug halten werden oder es WordPress-Plugins geben wird, welche auf Knopfdruck zum Artikeltext passende Bilder generieren.
Auch das Trainieren der KI zum Generieren vom eigenen Gesicht (oder das von Kundengesichtern) ist jetzt schon möglich und wird bald sicher noch einfacher machbar sein.
Was noch?
Ganz wilde Zeiten also mit viel Unsicherheit, Abwehrreaktionen etablierter Künstler, rechtlichen Grauzonen, dem Zusammenbruch bestehender und Aufbau neuer Geschäftsmodelle und mittendrin Bildagenturen, Fotografen und KI-Anbieter.
Es gibt noch etliche Aspekte, die hier nicht untergebracht werden konnte, das kommt bestimmt bald in einem weiteren Artikel.
Fotorealistische Bilder durch die Eingabe einiger Wörter auf Knopfdruck erstellen? Das ist heutzutage mittels Künstlicher Intelligenz und Tools wie Dall‑E, Stable Diffusion, Nightcafe und anderen Anbietern problemlos möglich.
Für professionelle Fotografen, Illustratoren und Designer wirft das sehr grundlegende Fragen auf. Ist die neue Technik ein Bedrohung oder eine Bereicherung? Vielleicht beides?
Auf der diesjährigen Photopia, dem viertägigen „Festival of Imaging“ in Hamburg vom 13. bis 16.10.2022 dreht sich alles um das Thema Fotografie, Bildbearbeitung und Technik. Die neusten Entwicklungen wie KI-Bilderstellung dürfen da natürlich nicht fehlen.
In der dazugehörigen „Creative Content Conference“ gibt es an drei Tagen (14.–16.10.2022) etliche Vorträge zur Fotografie, darunter auch zum Thema KI: Ich werde am Sonntag, den 16.10.2022 um 16:30 Uhr im Gespräch mit der kwerfeldein-Redakteurin Katja Kemnitz im Vortrag „Ist die KI der Tod der Stockfotografie?“ die Möglichkeiten und Grenzen der neuen Technik ausloten.