Der für Donnerstag, den 25.4.2024 angesetzte Gerichtstermin fällt aus. Grund dafür ist ein kurzfristiger Antrag des gegnerischen Anwalts, welcher an diesem Termin angeblich verhindert sei.
Das Gericht hat diesem Antrag eben stattgegeben. Der Termin wurde verlegt auf: Donnerstag, den 11.07.2024, 13:30 Uhr, Sitzungssaal A 265, 2. Etage, Sievekingplatz 1 (Ziviljustizgebäude) in Hamburg.
Ich bedauere diese Verzögerung und habe irgendwie das Gefühl, dass LAION e.V. vielleicht lieber noch ungestört, ach, lassen wir die Spekulationen…
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt. Da LAION auf meine Abmahnung nicht zu unserer Zufriedenheit reagieren wollte, blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
15.04.2024: Stellungnahme des Gegenanwalts zu unserem Schriftsatz
19.04.2024: Antrag der Gegenseite auf Terminverschiebung (ursprünglich angesetzter Termin war am 25.04.2024)
11.07.2024: Neuer Gerichtstermin vor dem Landgericht Hamburg um 13:30 Uhr
Das Verfahren ist öffentlich.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Seit Tagen ist in der KI-Welt kaum von etwas anderem die Rede als den beeindruckenden Ergebnissen von Sora.
Sora ist der Name des kürzlich hier vorgestellten Text2Video-Generators der Firma OpenAI, welche auch schon den Text2Bild-Generator Dall‑E und das Text2Text-Generator ChatGPT veröffentlicht hat.
Standbild aus einem Sora-Video [Montage]
Mit Sora können durch simple Texteingaben hochauflösende Videos von bis zu einer Minute Länge generiert werden.
Einen Überblick über die Ergebnisse findet ihr haufenweise, entweder auf der Sora-Seite direkt oder bei YouTube, zum Beispiel in diesem Video:
Ki-Videos, mittels Sora von OpenAI generiert
Auf der offiziellen Webseite wird lang und breit über die Sicherheit des Tools geredet und gerne erwähnt, dass geplant sei, den C2PA-Metadaten-Standard zur Erkennung von KI-generierten Inhalten zu unterstützen. Auffällig ist aber, dass andere Informationen fehlen.
Das Geheimnis der Trainingsdaten
Auffällig ist, dass an keiner Stelle der Vorstellung von Sora darauf eingegangen wird, wie genau das KI-Tool trainiert wurde. Welche Daten wurden dafür verwendet?
Im technischen Report findet sich nur der lapidare Satz: “[…] we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios.“
Ach? Ja, das war uns allen klar, aber welche Videos und Bilder habt ihr dafür nun genau benutzt?
In der Vergangenheit hat sich OpenAI nicht mit Ruhm bekleckert, wenn es um Rücksicht auf Urheberrechte bei Trainingsdaten ging.
Auch beim zweiten Produkt von OpenAI, ChatGPT, liegt die Sache ähnlich. OpenAI wird gerade von der Zeitung New York Times verklagt, weil urheberrechtlich geschützte Trainingsdaten der Zeitung für das KI-Training von ChatGPT benutzt worden seien.
Bei einer Zeugenanhörung von OpenAI durch das Oberhaus des britischen Parlaments fiel seitens OpenAI auch der folgenschwere Satz:
„Because copyright today covers virtually every sort of human expression–including blog posts, photographs, forum posts, scraps of software code, and government documents–it would be impossible to train today’s leading AI models without using copyrighted materials. Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today’s citizens“
Frei übersetzt: Ohne den Zugriff auf urheberrechtlich geschützte Trainingsdaten könnten wir unsere Tools nicht anbieten.
Genau wegen diesem bisher schon bekannten rücksichtslosen Umgang mit Urheberrechten muss eine Frage viel lauter gestellt werden:
Welche Videos und Bilder wurden für das Training der Sora-KI verwendet?
Die Wahrscheinlichkeit ist sehr hoch, dass auch hier – ähnlich wie beim Training von Dall‑E und ChatGPT urheberrechtlich geschützte Videos (und Bilder) zum Einsatz kamen.
Selbst Wasserzeichen in Videos sind für KI-Entwickler schon lange kein Hindernis mehr. Schon 2017 hat Google selbst eine Technik vorgestellt, mit der Wasserzeichen aus Bildern entfernt werden können.
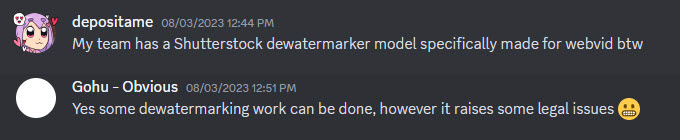
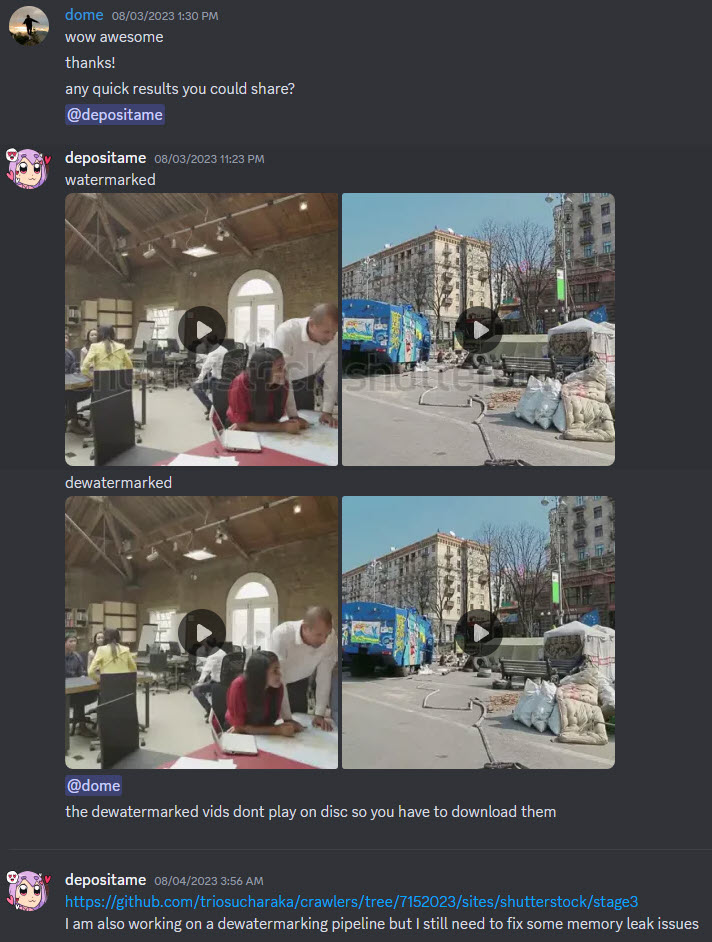
Auch der LAION-Verein bietet auf GitHub ein kostenloses Tool für die „Wasserzeichen-Erkennung“ an. Von der Erkennung zur Entfernung ist es für geübte Programmierer dann nur noch ein kleiner Schritt, über den aus rechtlichen Gründen nicht so gerne öffentlich geredet wird. Manchmal aber doch:
Aus dem #video-generation Kanal des Discord-Servers von LAION
Aus dem #video-generation Kanal des Discord-Servers von LAION
Bei LAION wird zwar an einem eigenen Text2Video-Generator namens phenaki gearbeitet, die technischen Details des Trainings sind denen von Sora aber sehr ähnlich, soweit ich das beurteilen kann.
Die Wahrscheinlichkeit, dass OpenAI daher mit der gleichen Rücksichtslosigkeit wie LAION gegenüber Urhebern beim KI-Training vorgeht, halte ich für hoch, zumal die bisherigen Aussagen und Handlungen von OpenAI leider nicht geeignet sind, Zweifel zu zerstreuen.
Beim ganzen Hype vom SORA und dem Staunen über die tollen Ergebnisse sollte nicht vergessen werden zu fragen, welche (Video-)Künstler beim Training beteiligt waren.
Meine Klage gegen den deutschen Verein LAION e.V., welcher unter anderem Trainingsdatensätze für KI-Anwendungen bereitstellt, hat weltweit für viel Aufmerksamkeit gesorgt.
Da es auch regelmäßig viele Anfragen zum aktuellen Stand des Verfahren gibt, hier ein kurzes Update.
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt.
Der Verein LAION e.V. sieht das naturgemäß anders, wie in den beiden zitierten Blogartikeln gut erkennbar ist. Daher blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
25.04.2024 um 13:00 Uhr: Gerichtstermin vor dem Landgericht Hamburg (Update 12.4.2024: Die Uhrzeit wurde geändert)
Das Landgericht Hamburg hat also in ca. einem halben Jahr den Gerichtstermin angesetzt, in dem dann mündlich weiter über die Klage verhandelt werden wird. Das Verfahren ist öffentlich. Hier die aktuelle Zusammenfassung des Falls durch die mich vertretende Kanzlei SLD.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Was passiert eigentlich, wenn Urheber ihre Bilder aus den Trainingsdaten für die großen KI-Systeme entfernen wollen? Ich habe es ausprobiert und das Ergebnis gleicht einem Kafka-Roman.
Der deutsche Verein LAION e.V. hat verschiedene KI-Trainingssätze kostenlos ins Internet gestellt mit Links und Bildbeschreibungen und anderen Informationen zu teilweise über 5.8 Milliarden (größtenteils urheberrechtlich geschützten) Bildern.
Diese Trainingsdaten wurden u.a. von kommerziell agierenden Firmen wie Stability AI genutzt, um ihre Bildgenerierende KI „Stable Diffusion“ zu trainieren. Ein Schelm, wer Böses dabei denkt, dass zufällig einer der Gründungsmitglieder des Vereins, Richard Vencu, bei der Firma Stability AI arbeitet. Das übrigens genau seit Februar 2022, also dem Zeitpunkt, als der Verein gegründet wurde.
Im Februar hatte ich hier berichtet, dass ich LAION e.V. darum gebeten hatte, meine urheberrechtlich geschützten Bilder aus den Trainingsdaten zu entfernen. Als Antwort kam ein arroganter Brief, der mit der Drohung endete, dass ich mit Schadensersatzansprüchen zu rechnen habe, sollte ich auf meiner angeblich unbegründeten Forderung bestehen.
Davon lasse ich mich natürlich nicht abschrecken und verschickte mit Hilfe meines Anwalts Ende März eine Unterlassungsforderung sowie eine Auskunftsanfrage, welche mit nach §§101 UrhG, 242 BGB zusteht.
Also im Klartext: Ich habe den Verein ausgefordert, meine Bilder aus dem Trainingssatz zu nehmen und mir Auskunft zu erteilen, in welchem Umfang genau meine Werke verwendet wurden, wie lange, woher sie die Inhalte hatten und so weiter.
Das fand der Verein gar nicht lustig und antwortete am 11. April 2023:
„Eine Urheberrechtsverletzung liegt nicht vor. Die einzige Vervielfältigungshandlung die unsere Mandantin vorgenommen haben könnte, war vorübergehender Natur und ist von den Schrankenregelungen sowohl des § 44b UrhG als auch des noch weitergehenden § 60d UrhG gedeckt. Wie bereits gegenüber Ihrem Mandanten ausgeführt, speichert unsere Mandantin keine Vervielfältigungsstücke der Werke Ihres Mandanten, die gelöscht werden könnten oder über die Auskunft erteilt werden könnte. Unsere Mandantin hat lediglich zum initialen Trainieren eines selbstlernenden Algorithmus, unter Einsatz sog. Crawler, Bilddateien im Internet ausfindig gemacht und zur Informationsgewinnung kurzzeitig erfasst und ausgewertet.“
Interessant ist, dass hier ausdrücklich der Einsatz von Crawlern erwähnt wird, welcher in den Nutzungsbedingungen der meisten Bildagenturen ausdrücklich verboten ist. So auch bei den Bildern, welche ich beanstandet hatte.
Mal ganz abgesehen, dass wir auch sehr gespannt sind, wie LAION e.V. erklären will, woher der Verein Links zu Bild-Thumbnails haben will, deren Bilder schon vor der Vereinsgründung bei den Bildagenturen gelöscht worden waren.
Weiter heißt es dann im Text:
„Unsere Mandantin wird daher insbesondere keine Unterlassungserklärung gegenüber Ihrem Mandanten abgeben. Daneben hat Ihr Mandat selbstredend auch keinen Anspruch auf Auskunft durch unsere Mandantin. Selbst bei Bejahung einer rechtsverletzenden Vervielfältigungshandlung bestünde mangels eines Handelns im gewerblichen Ausmaß kein Auskunftsanspruch.“
Das heißt, salopp verkürzt formuliert: Wir werden die urheberrechtlich geschützten Werke weiterhin nutzen, auch wenn der Urheber dagegen ist. Außerdem verweigern wir die Auskunft, wo wir die Bilder genau herhaben und was wir damit gemacht haben und wie lange genau wir sie gespeichert haben. So selbstverständlich finden wir das nicht.
Dann heißt es:
„Unsere Mandantin hat grundsätzlich Verständnis dafür, dass Ihr Mandant ggf. auch eine vorübergehende Vervielfältigung seiner Werke nicht gern sieht. Nur ist diese eben ausdrücklich vom europäischen Gesetzgeber gestattet worden. Daher müssen wir Ihren Mandanten dazu auffordern, dass er erklärt, von den mit Schreiben vom 29.03.2023 geltend gemachten Ansprüchen Abstand zu nehmen.“
Um dem Ganzen dann die Krone aufzusetzen, fordert LAION e.V. dann Geld von mir:
„Mit Schreiben vom 14.02.2023 hatten wir Ihren Mandanten bereits darauf aufmerksam gemacht, dass unserer Mandantin im Falle einer unberechtigten Inanspruchnahme Schadenersatzansprüche gemäß § 97a Abs. 4 UrhG zustehen. Unsere Mandantin hatte seinerzeit noch davon abgesehen diesen Anspruch durchzusetzen, sieht sich nun aber außer Stande hier weiter Nachsicht walten zu lassen. Für die Verteidigung gegen die durch Sie ausgesprochene, offenkundig unberechtigte Abmahnung sind ihr Rechtsanwaltskosten entstanden, die unsere Mandantin nicht selbst tragen wird.“
Den Gegenstandswert beziffert die gegnerische Anwaltskanzlei auf 9.000 Euro, der geforderte Betrag beläuft sich auf 887,03 € (Aufschlüsselung siehe Bild oben).
Also noch mal das Ganze runtergebrochen: Der Verein nutzt massenhaft urheberrechtlich geschützte Werke, damit kommerziell agierende Firmen damit Profit machen können und wenn ich als Urheber darum bitte, meine Bilder aus den Trainingsdaten zu entfernen sowie mir den rechtlich zustehenden Auskunftsanspruch zu erfüllen, soll ich dem Verein Schadensersatz zahlen.
Da passt es ganz gut, dass die Kanzlei schon mal androht, dass sie „geneigt seien, die Angelegenheit einer gerichtlichen Klärung zuzuführen“. Wir sind genauso „geneigt“ und arbeiten schon an der Anspruchsbegründung für das Gericht.
Update 27.04.2023, 16:25 Uhr: Wir haben eben die Klage gegen LAION e.V. vor dem Landgericht Hamburg eingereicht.
Letzten Monat hatte ich in diesem Artikel erklärt, wie die Künstliche Intelligenz am Beispiel von Stable Diffusion funktioniert.
Darin kam der Verein LAION e.V. zur Sprache, welcher etliche riesige Datenpakete anbietet, mit welchen KIs trainiert werden. Eines dieser Pakete heißt z.B. LAION 5B, weil es ca. 5,85 Millarden („5,85 Billions“ im Englischen, daher 5B) Datensätze umfasst.
Ein Datensatz besteht zum Beispiel aus der URL zu einer Bilddatei, der dazugehörigen Bildbeschreibung, den Bildmaßen in Pixeln, der verwendeten Sprache sowie einiger anderer Faktoren.
Anfangs war wenigen Leuten bekannt, welche Bilder genau im Datenset enthalten waren. Aber die Künstler Mat Dryhurst, Holly Herndon und Jordan Meyer gründeten die Firma Spawning, welche wiederum die Webseite „Have I Been Trained?“ ins Leben riefen.
Dort können Leute – vereinfacht erklärt – die oben genannten Bildbeschreibungen durchsuchen, um zu sehen, welche Bilder in den KI-Trainingssets enthalten sind.
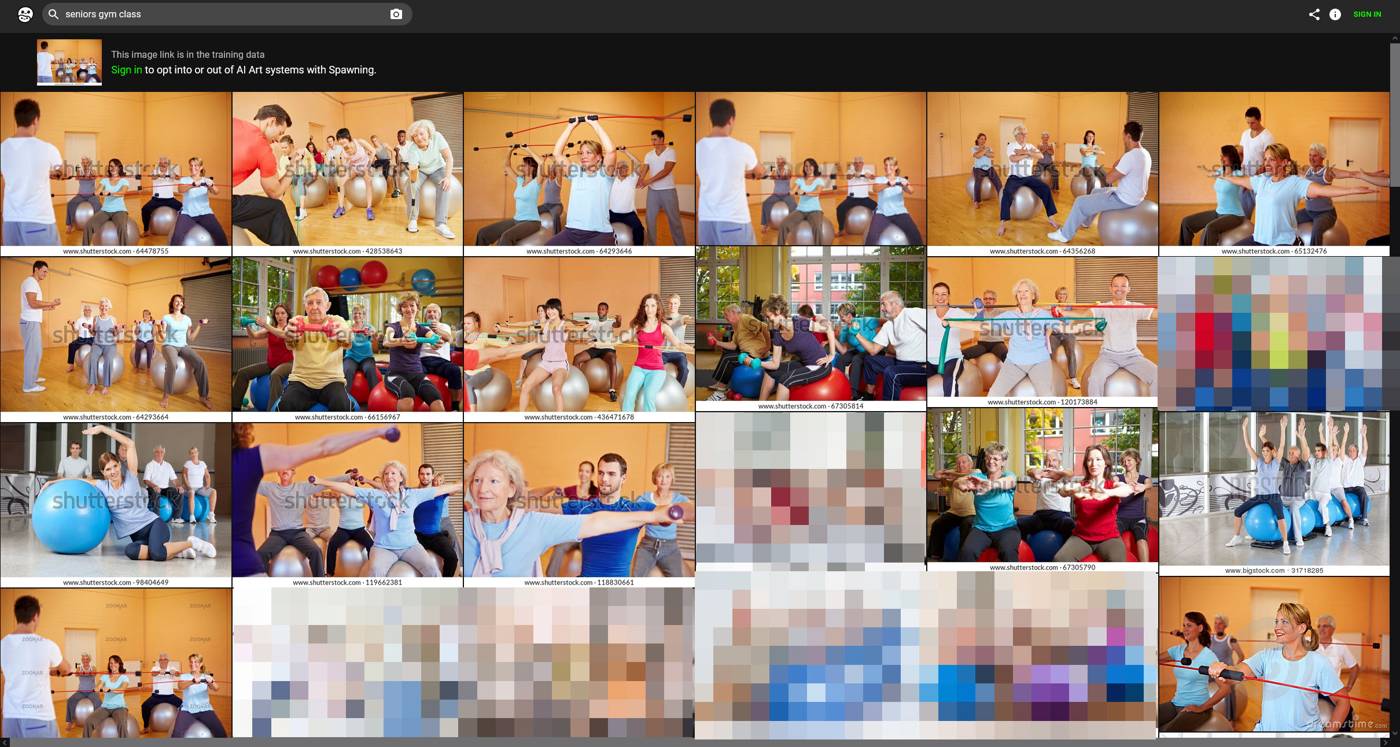
Viele Urheber nutzten die Webseite und fanden wenig überraschend viele Treffer. Auch aus meinem Portfolio konnte ich nach einer kurzen Stichprobe haufenweise Bilder finden, hauptsächlich mit Wasserzeichen aus den Bildagentur-Portfolios, aber auch von Kundenseiten oder Webseiten, die selbst illegal Bildersammlungen anbieten:
Haufenweise Links zu meinen Fotos aus meinem Shutterstock-Portfolio im LAION-Datensatz
In den Kommentaren eines meiner Social Media-Profile las ich den Hinweis eines Fotografen, dass der den Verein LAION gebeten hatte, seine Werke aus den Trainingsdaten zu nehmen und als Antwort mit Schadensersatzansprüchen bedroht wurde, sollte er auf seinem Anliegen beharren.
Das kam mir wie eine wilde Geschichte vor, bis ich die Fakten überprüfte. Ich nahm Einsicht in den Schriftsatz der Anwaltskanzlei und schickte am 13.02.2023 selbst eine Anfrage an LAION e.V. per Email mit der Bitte, meine Werke aus dem Trainingssatz zu entfernen.
Nur einen Tag später erhielt ich am 14.02.2023 tatsächlich Post („vorab per Email“) von der Hannover Anwaltskanzlei „Heidrich Rechtsanwälte“ im Auftrag von LAION e.V., übrigens fast wortgleich mit dem Schreiben, welches ich von dem anderen Fotografen weitergeleitet bekommen habe.
In dem Schreiben heißt es:
„Sehr geehrter Herr Kneschke,
hiermit zeigen wir an, dass wir die rechtlichen Interessen des LAION e.V., Herman-Lange-Weg 6, 21035 Hamburg, vertreten. Die ordnungsgemäße Bevollmächtigung wird anwaltlich versichert.
Grund unseres Schreibens ist Ihre E‑Mail vom 13. Februar 2023 an unsere Mandantin, welche uns diese zur Beantwortung vorgelegt hat.
Bei unserer Mandantin handelt es sich um einen im Vereinsregister eingetragenen, nicht-gewinnorientierten Verein, der es sich zur Aufgabe gemacht hat, selbstlernende Algorithmen im Sinne künstlicher Intelligenz fortzuentwickeln und der breiten Öffentlichkeit zur Verfügung zu stellen. Die Vereinsmitglieder sowie der Vorstand sind im Rahmen der Vereinsarbeit ehrenamtlich forschend tätig.
Unsere Mandantin hat bereits im Sommer 2022 umfangreich Rechtsrat zu verschiedenen Problemstellungen – insbesondere urheberrechtlichen Implikationen – im Zusammenhang mit ihrer Tätigkeit auf dem Gebiet der Erforschung von Kl-gestützten Bildgenerierungsmodellen eingeholt. Unserer Mandantin war es von Anfang an wichtig, dass im Rahmen ihrer Tätigkeit keine Rechte Dritter verletzt werden. Unsere Mandantin hält sich ausnahmslos an die bestehenden gesetzlichen Vorgaben, insbesondere aus dem Urheber- und Datenschutzrecht.
Unsere Mandantin unterhält lediglich eine Datenbank, die Links zu im Internet öffentlich abrufbaren Bilddateien enthält. Sie kann zwar nicht ausschließen, dass in der Datenbank auch Links zu Bildern enthalten sind, deren Urheber Sie sind. Da unsere Mandantin aber jedenfalls keine der von Ihnen monierten Fotografien speichert, besteht Ihrerseits auch kein Anspruch auf Löschung. Es existieren bei unserer Mandantin schlicht keine Bilder, die gelöscht werden könnten.
Das Bereitstellen von Links stellt nach der höchstrichterlichen Rechtsprechung auch keine Verletzung von Urheberrechten dar. Das Bereitstellen eines Links dient lediglich dem Auffinden eines ohnehin im Internet abrufbaren Inhalts. Der hinter einem Link stehende Inhalt kann auch nur an der verlinkten Stelle und nicht andernorts abgerufen werden, sodass insbesondere keine Vervielfältigung im Sinne des Urheberrechts vorliegt. Unsere Mandantin trägt keine Verantwortung für die Inhalte auf anderen Websites.
Auf Nutzungen Ihrer Werke durch Dritte hat unsere Mandantin naturgemäß keinen Einfluss. Eine Nutzung durch Dritte wird aber ohnehin auch nicht erst durch unsere Mandantin ermöglicht. Die von unserer Mandantin verlinkten Bildinhalte sind frei im Internet abrufbar. Sofern Sie eine rechtsverletzende Nutzung durch Dritte feststellen, müssen Sie sich an diese Personen wenden.
Ihre Fristsetzung betrachten wir daher als gegenstandslos. Wir weisen außerdem darauf hin, dass unsere Mandantin gemäߧ 97a Abs. 4 UrhG Schadenersatzansprüche geltend machen kann, wenn diese unberechtigt urheberechtlich in Anspruch genommen wird.
Wir hoffen, dass wir Ihre Bedenken mit unseren Ausführungen ausräumen konnten und stehen Ihnen für Rückfragen gern zur Verfügung.“
Ja, ihr lest das vollkommen richtig. Urhebern, die nicht wollen, dass ihr Werke für Trainingszwecke benutzt werden, werden Schadensersatzansprüche angedroht.
Die restlichen Aussagen im Schreiben lassen einen ebenfalls etwas verwundert zurück. Die angebliche Gemeinnützigkeit eines Vereins, welcher unter anderem von einer Firma wie Stability AI mitfinanziert wird, welche wiederum von den Ergebnissen des Vereins kommerziell profitiert, hat mindestens ein „Geschmäckle“, was meiner Meinung nach danach riecht, hier absichtlich eine Konstruktion zu bauen, welche Haftungsfragen auslagern soll.
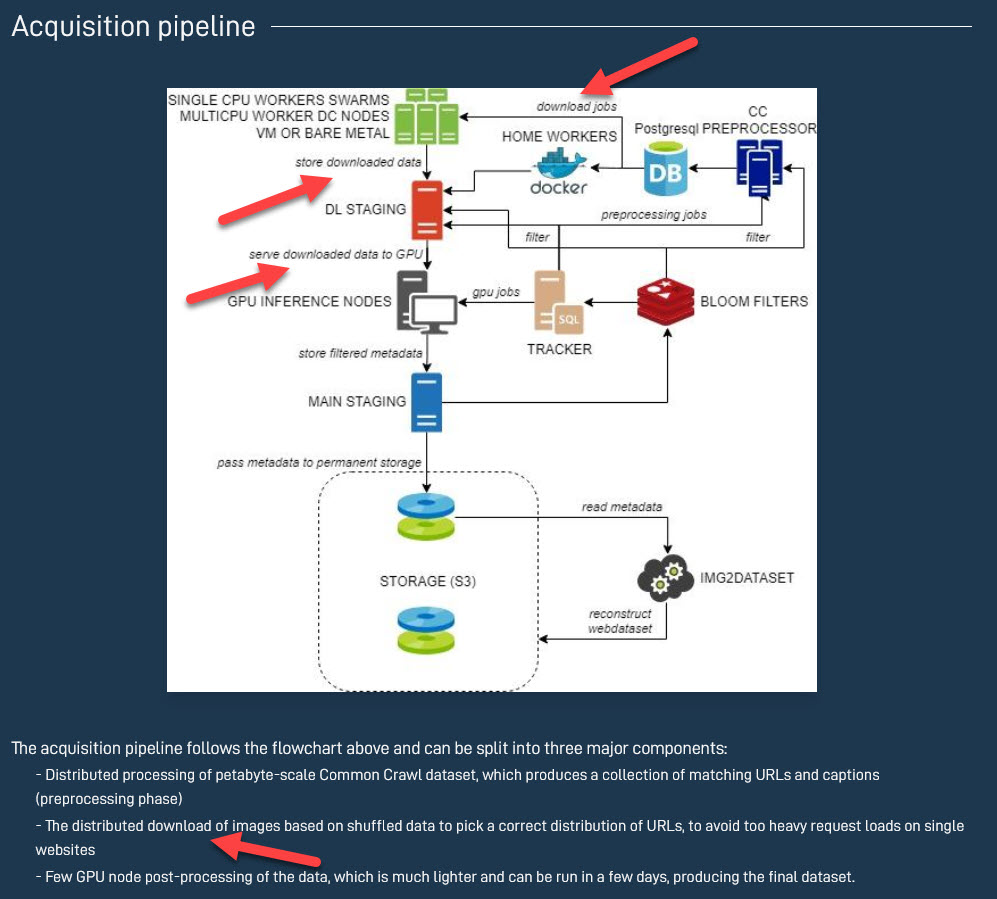
Auch das „ledigliche Unterhalten einer Datenbank“ ist hier meiner Meinung nach etwas zu kurz gegriffen, da neben den oben genannten Datenpunkten auch Daten wie „similarity“, „pwatermark“ oder „punsafe“ enthalten, welche nicht einfach ausgelesen, sondern erstellt werden müssen, was vermutlich zumindest eine temporare Speicherung der Bilddaten erfordert haben wird. Das legt auch diese Infografik nahe, in der erklärt wird, das die Bilder und Daten „heruntergeladen“ wurden:
Das sind im Detail aber auch Vermutungen, welche wahrscheinlich bei einem Gerichtsprozess geklärt werden müssen.
Genau so einen Prozess werde ich nun anstreben, um die Frage richterlich klären zu lassen, ob das Vorgehen tatsächlich rechtlich so einwandfrei ist, wie die Anwaltskanzlei behauptet.
Falls ihr als Urheber ebenfalls einige eurer Werke im Datensatz von LAION findet und vielleicht auch Post von obiger Anwaltskanzlei erhalten wollt, findet ihr die Emailadresse für eure Anfrage zur Datenlöschung hier im Impressum von LAION e.V..