Der für Donnerstag, den 25.4.2024 angesetzte Gerichtstermin fällt aus. Grund dafür ist ein kurzfristiger Antrag des gegnerischen Anwalts, welcher an diesem Termin angeblich verhindert sei.
Das Gericht hat diesem Antrag eben stattgegeben. Der Termin wurde verlegt auf: Donnerstag, den 11.07.2024, 13:30 Uhr, Sitzungssaal A 265, 2. Etage, Sievekingplatz 1 (Ziviljustizgebäude) in Hamburg.
Ich bedauere diese Verzögerung und habe irgendwie das Gefühl, dass LAION e.V. vielleicht lieber noch ungestört, ach, lassen wir die Spekulationen…
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt. Da LAION auf meine Abmahnung nicht zu unserer Zufriedenheit reagieren wollte, blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
15.04.2024: Stellungnahme des Gegenanwalts zu unserem Schriftsatz
19.04.2024: Antrag der Gegenseite auf Terminverschiebung (ursprünglich angesetzter Termin war am 25.04.2024)
11.07.2024: Neuer Gerichtstermin vor dem Landgericht Hamburg um 13:30 Uhr
Das Verfahren ist öffentlich.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Meine Klage gegen den deutschen Verein LAION e.V., welcher unter anderem Trainingsdatensätze für KI-Anwendungen bereitstellt, hat weltweit für viel Aufmerksamkeit gesorgt.
Da es auch regelmäßig viele Anfragen zum aktuellen Stand des Verfahren gibt, hier ein kurzes Update.
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt.
Der Verein LAION e.V. sieht das naturgemäß anders, wie in den beiden zitierten Blogartikeln gut erkennbar ist. Daher blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
25.04.2024 um 13:00 Uhr: Gerichtstermin vor dem Landgericht Hamburg (Update 12.4.2024: Die Uhrzeit wurde geändert)
Das Landgericht Hamburg hat also in ca. einem halben Jahr den Gerichtstermin angesetzt, in dem dann mündlich weiter über die Klage verhandelt werden wird. Das Verfahren ist öffentlich. Hier die aktuelle Zusammenfassung des Falls durch die mich vertretende Kanzlei SLD.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Schon drei Mal haben Silke Güldner und ich zusammen in Hamburg einen ganztätigen Praxis-Workshop zum Thema „KI in der Berufsfotografie“ gegeben.
Jedes Mal war der Workshop schnell ausgebucht und über unsere Social-Media-Kanäle erreichte uns oft der Wunsch, ob wir das Ganze auch online anbieten würden.
Deshalb wird der vierte Workshop nun online stattfinden am Freitag, den 26.01.2024.
Seit anderthalb Jahren beschäftige ich mich nun schon intensiv mit der Bilderstellung durch Künstliche Intelligenz. Zusammen mit meinem Team habe ich mittlerweile ein Portfolio von über 7000 KI-Bildern, welche ich bei Bildagenturen anbiete.
„Hintergründe & Möglichkeiten der KI-Tools in der fotografischen Praxis mit KI-Experte & Fotograf Robert Kneschke und Fotografenberaterin Silke Güldner
Der Workshop bietet eine einzigartige Gelegenheit, um tiefer in die Welt der künstlichen Intelligenz einzutauchen und ihre Anwendungsmöglichkeiten in der Fotografie zu entdecken. Hier lernen Profi- und Nachwuchsfotografen die Funktionsweise und verschiedenen KI-Tools kennen, können diese im praktischen Teil selbst ausprobieren und diese für ihre eigene Positionierung im Markt reflektieren. Durch Diskussionen und den Austausch mit der Gruppe und den Referenten erhalten sie darüber hinaus auch Feedback und Inspirationen für ihre künftige Arbeit und die Kommunikation mit ihren Kunden. Am Ende des Workshops sind die Teilnehmer bestens vorbereitet, um die Entwicklungen und Herausforderungen im Kontext von KI und Fotografie zu verstehen und zukünftige Möglichkeiten zu nutzen.
Inhalte
Einführung KI
Wie funktioniert KI-Bilderstellung
Vorstellung der Tools Stable Diffusion, Dall‑E 3, Midjourney, Firefly
Anwendungsmöglichkeiten, Unterschiede und Motivbeispiele
Praxis Teil 1
Anhand der Teilnehmer-Portfolios sprechen wir über Möglichkeiten, die KI für die eigenen Ziele bieten kann und wann konventionelle Fotografie der bessere Weg ist
Portfolio Vorstellung der Teilnehmenden
Vorteile und Nutzen von konventioneller Fotografie gegenüber KI-Lösungen in der Kundenberatung
Praxis Teil 2
Hands On & Live Demos
Testen der KI-Tools am Beispiel von Midjourney
Erläuterung von Prompt-Engineering, In- and Outpainting
Tools für den KI Workflow
Überblick der Nutzungsmöglichkeiten & Best Practice Beispiele
Meta Themen
Rechtliche & moralische Probleme der KI-Nutzung
Veränderung der Berufsfotografie & Einfluss auf die Preisfindung
Ausblick & Kooperationsmöglichkeiten“
Der Workshop wird am Freitag, den 26.01.2025 online stattfinden, mehr Informationen zur Veranstaltung findet ihr hier auf der Webseite des Veranstalters Photo+Medienforum Kiel.
Die Teilnehmer*innen ist begrenzt, also zögert nicht, euch bei Interesse rechtzeitig euren Platz zu sichern.
Konferenzen und Messen versuchen in der Regel, aktuelle Trends und Entwicklungen abzubilden, damit die Besucher*innen wertvolle Informationen und Einsichten für ihr (nicht nur Fotografie-)Business mitnehmen können.
Nach dem Ende der Photokina in Köln arbeitet die PHOTOPIA in Hamburg seit einigen Jahren daran, immer mehr zu einem gleichwertigen Ersatz zu werden.
Ganz groß steht das Thema „Künstliche Intelligenz“ dieses Jahr vom 21.–24. September 2023 auf der Photopia im Fokus mit einem eigenen „AI Center“ und haufenweise hochkarätigen und spannenden Experten-Vorträgen und ‑Diskussionsrunden.
Ich habe die Ehre, an gleich zwei Events auf deren Creative Content Conference dabei sein zu dürfen:
Am Freitag, den 22. September 2023 von 14:30 bis 15:30 Uhr halte ich im Konferenzbereich der Halle A1 meinen Vortrag „Vom Fotografen zum KI-Prompter“. Dabei blicke ich auf über ein Jahr intensiver KI-Nutzung zurück und teile wertvolle Erfahrungen zum Einsatz von KI-Tools.
Ebenfalls am Freitag, den 22. September 2023 bin ich später dann ab 17 Uhr an gleicher Stelle Gast bei der Diskussionsrunde „Q&A – Mensch oder Maschine: Wie sieht die Fotoproduktion von morgen aus?“ Neben mir sprechen dort Claudia Bußjaeger, Sandramaria Schweda aka Tweda und Peter Hytrek über die vielfältigen Herausforderungen, vor die KI-generierte Bilder die professionelle Fotografie stellen.
Am 01. September 2023 schon findet zusammen mit Fotografie-Coach Silke Güldner unserer zweiter Praxis-Workshop zur „KI in der Berufsfotografie“ in Hamburg statt (schon ausgebucht!).
Ebenfalls in Hamburg gibt am 25. Oktober 2023 den dritten Praxis-Workshop „KI in der Berufsfotografie“ zusammen mit Silke Güldner. Dafür sind noch wenige Plätze frei.
Weitere Workshops, Vorträge und Webinare sind in Vorbereitung. Solltest Du auch Interesse daran haben, mich für eine Veranstaltung zu buchen, kannst Du mich hier kontaktieren.
Ich freue mich schon auf euren Besuch und rege Diskussionen!
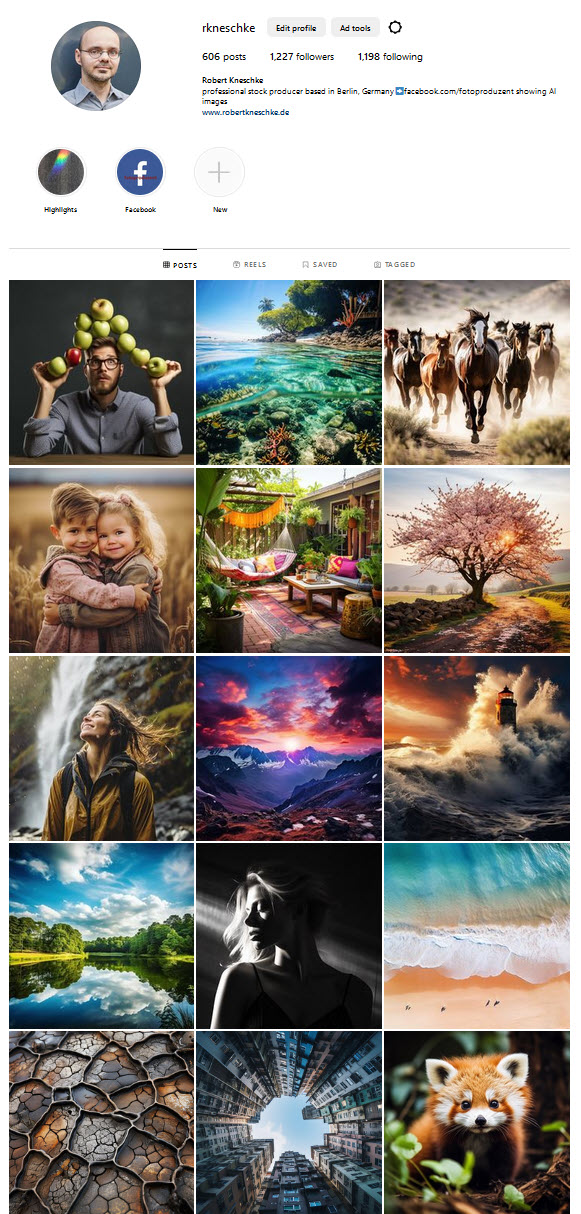
Mein Instagram-Account@rkneschke besteht seit über zehn Jahren, aber bisher habe ich ihn eher stiefmütterlich behandelt.
Zu sehen gab es dort auch fast nie Auszüge meiner professionellen Arbeit, sondern eher Bilder, die privat enstanden sind, ein Sammelsurium aus abstraktem Minimalismus, Food, Landschaften, Konzertfotos und Drohnenaufnahmen (bis ich diese geschrottet habe).
Aktueller Screenshot von meinem Instagram-Account
Seit ich mich vor einem Jahr stark auf die Bilderstellung mittels generativer KI fokussiert habe, stand die Frage im Raum, ob diese beeindruckenden KI-Bilder sich eignen würden, um damit – mehr oder weniger automatisiert – Social-Media-Accounts zu betreiben.
Da mein Instagram-Kanal sowieso nur sporadisch gefüllt wurde von mir, habe ich vor drei Monaten ein Experiment gestartet.
Der Aufbau vom Instagram-KI-Experiment
Ich habe meinen Instagram-Kanal seit dem 16.4.2023 ausschließlich mit komplett KI-generierten Inhalten gefüllt. Das Ganze sollte möglichst zeitsparend vonstatten gehen, mein Ablauf war daher:
Die Text-KI ChatGPT nach einem Haufen trendiger Instagram-Motive fragen.
Diese Motive automatisiert per Bild-KI Midjourney in Bilder umwandeln lassen.
Die schönsten Bilder raussuchen und unbearbeitet zu Instagram hochladen.
Die Bildbeschreibung und Hashtags automatisiert durch ChatGPT generieren lassen basierend auf der Bildbeschreibung, die in Schritt 1 generiert wurde.
Optional: Um noch mehr Zeit zu sparen, ab und zu einige Instagram-Beiträge im Voraus mit der Instagram-App planen.
Alle KI-Bilder wurden in den Hashtags und der Bildbeschreibung als solche ausgewiesen.
Das Ziel vom Experiment
Ich wollte mit dem Experiment testen, was mit meinem Instagram-Account passiert, wenn ich diesen komplett auf KI-basierte Bilder umstelle.
Werde ich Follower gewinnen oder verlieren?
Wird sich meine Reichweite erhöhen oder verringern?
Spare ich Zeit mit dieser Art der Content-Erstellung?
Wie reagieren meine bisherigen Follower?
Die Ergebnisse in Zahlen
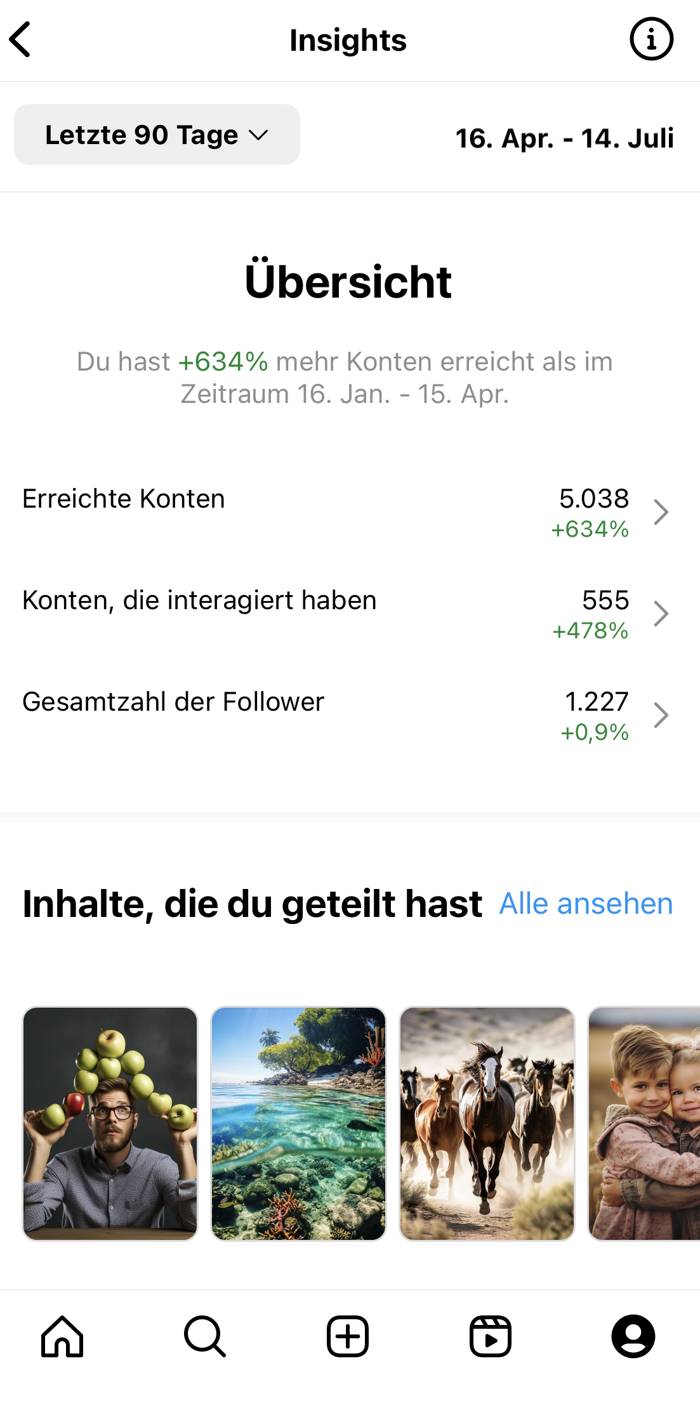
Das Wichtigste zuerst. Wie ihr an der Übersicht in den Instagram-Insights sehen könnt, liegen alle Messwerte im grünen Bereich.
Begonnen habe ich das Experiment Mitte April 2023 mit 1216 Followern, aktuell liege ich bei 1227, das entspricht einem Plus von 0,9%. Nicht viel, aber immerhin kein Verlust.
Ich konnte 634% mehr Konten erreichen und 478% mehr Konten haben mit meinem Kanal interagiert. Dazu muss ich jedoch fairerweise sagen, dass ich im Vergleichszeitraum der drei Monate vorher (also Januar bis April 2023) nur ein Bild gepostet hatte, diese Werte also viel höher als normal ausfallen.
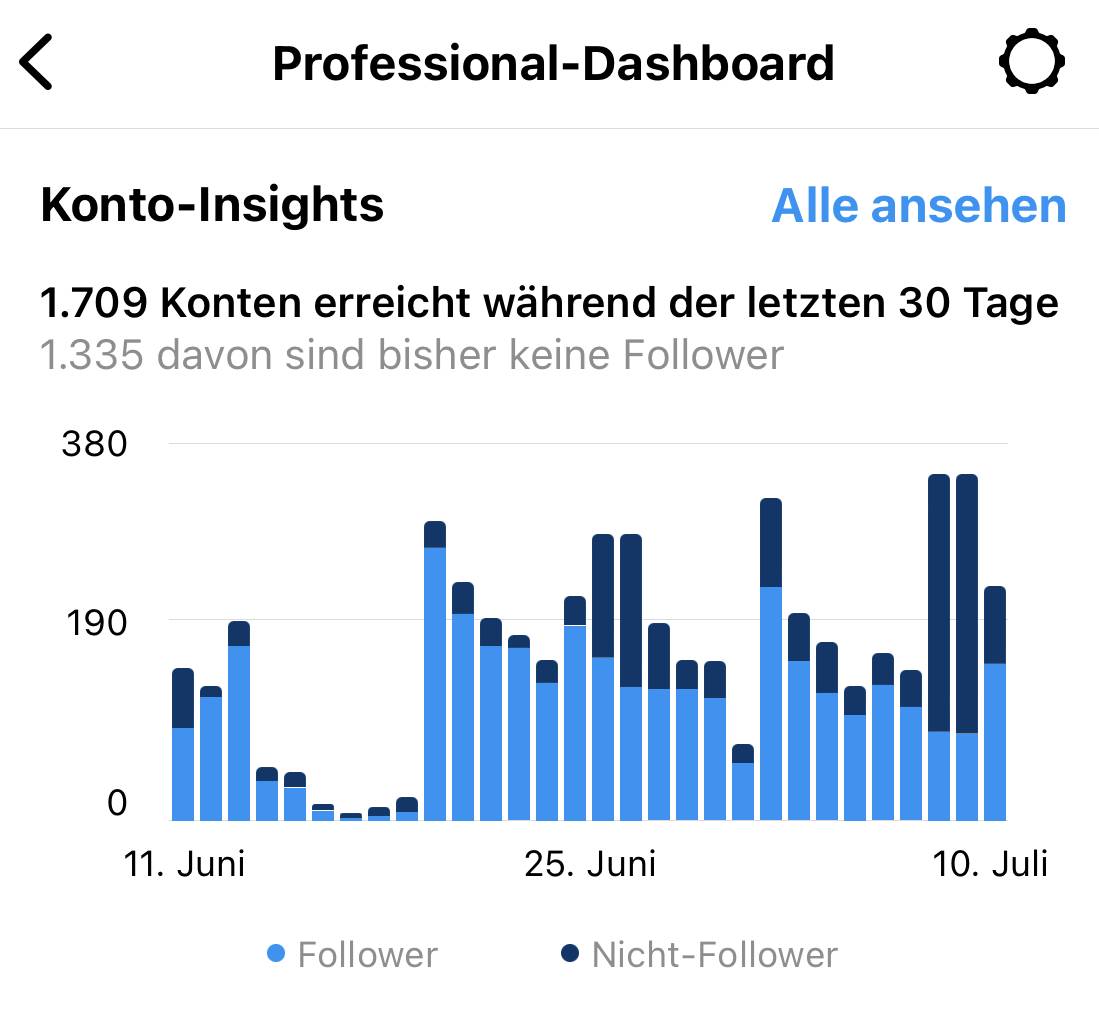
Wie ihr am obigen Diagramm sehen könnt, ist auch die Zahl der Nicht-Follower relativ hoch, auf jeden Fall deutlich höher als vor dem Experiment. Das liegt vermutlich daran, dass ich durch die vielen neuen verschiedenen Motive auch ganz unterschiedliche Hashtags anbringen konnte, die außerhalb meiner „Instagram-Follower-Bubble“ lagen.
Was jedoch auf jeden Fall stark gefallen ist, ist die Zeit, die ich zur Erstellung eines Posts benötigte. In den 10 Jahren zuvor, habe ich ca. 55 Bilder pro Jahr hochgeladen, also gut ein Bild pro Woche. Im Experimentzeitraum habe ich allein fast 60 Bilder hochgeladen, also ca. 5 pro Woche.
Die Kommentare zu den Bildern waren gemischt. Einige positiv, einige kritisch, aber insgesamt alles im Rahmen. Ich vermute, dass die radikalen KI-Gegner schnell ihr Abo gekündigt haben, dafür jedoch einige neue Fans dazu gekommen sind.
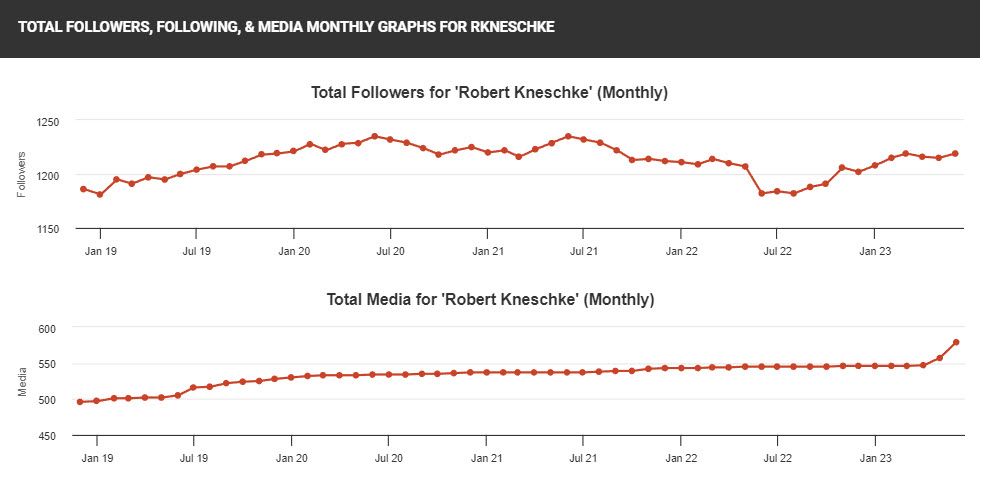
Wer an der genaueren Entwicklung des Kanals interessiert ist, kann sich die Statistiken hier bei Social Blade anschauen:
Persönliche Anmerkungen und Fazit
Ich hatte ehrlich gesagt schlimmere Ergebnisse befürchtet und dachte, dass vielleicht viele meiner Fans, die eher aus dem Fotografie-Lager kommen, angesichts dieser KI-Bilder-Flut frustriert sind und davonlaufen.
Das hat sich zum Glück nicht bewahrheitet und die leichten Verluste konnten durch neue KI-Fans mehr als ausgeglichen werden.
Insgesamt ist das Experiment natürlich wissenschaftlich gesehen kaum haltbar, da zum Beispiel der Vergleichszeitraum vorher nicht repräsentativ ist. Da hatte ich fast nichts gepostet, weshalb die Engagement-Rate logischerweise auf einem sehr niedrigen Level lag.
Auch die Bildauswahl ist eher zufällig. Ich habe viele atemberaubende Naturbilder, einige Menschenbilder und niedliche Tiermotive gepostet. Alles quer durch den Gemüsegarten. Vermutlich ist das für den Aufbau einer speziellen Zielgruppe eher unpassend, aber da ich auch vorher eher motivisch gesehen Querbeet unterwegs war, passt das hier.
Interessant fand ich die Möglichkeit, mittels neuer Motive und die entsprechenden Hashtags ganz andere Zielgruppen ansprechen zu können, welche mir bisher noch nicht folgen.
Das ist sicher für Accounts, welche professionelle Ziele verfolgen und ihre Reichweite erhöhen wollen, ein sehr spannender Aspekt.
Beeindruckend war und ist aber auch das Zusammenspiel von ChatGPT und Midjourney, welches die Zeit für die Content-Erstellung stark reduziert hat, was natürlich die Motivation erhöht, überhaupt mehr zu posten.
Wie geht es weiter?
Ich werde auf meinem Instagram-Kanal weiter KI-Inhalte posten. Ob ich inhaltlich mich mehr auf bestimmte Motive konzentriere oder einfach die Bilder zeige, die mir gefallen, muss ich noch entscheiden. Wer es direkt wissen will, folgt bitte am besten einfach meinem Instagram-Account @rkneschke hier.
In der Zwischenzeit habe ich heute für mein Seitenprojekt „www.eis-machen.de“ ebenfalls einen Instagram-Account gestartet. Unter @eiscremeparty werde ich nur KI-Bilder zum Thema Eiscreme posten. Wer daran Interesse hat, kann dem Kanal ebenfalls gerne folgen.