Der für Donnerstag, den 25.4.2024 angesetzte Gerichtstermin fällt aus. Grund dafür ist ein kurzfristiger Antrag des gegnerischen Anwalts, welcher an diesem Termin angeblich verhindert sei.
Das Gericht hat diesem Antrag eben stattgegeben. Der Termin wurde verlegt auf: Donnerstag, den 11.07.2024, 13:30 Uhr, Sitzungssaal A 265, 2. Etage, Sievekingplatz 1 (Ziviljustizgebäude) in Hamburg.
Ich bedauere diese Verzögerung und habe irgendwie das Gefühl, dass LAION e.V. vielleicht lieber noch ungestört, ach, lassen wir die Spekulationen…
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt. Da LAION auf meine Abmahnung nicht zu unserer Zufriedenheit reagieren wollte, blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
15.04.2024: Stellungnahme des Gegenanwalts zu unserem Schriftsatz
19.04.2024: Antrag der Gegenseite auf Terminverschiebung (ursprünglich angesetzter Termin war am 25.04.2024)
11.07.2024: Neuer Gerichtstermin vor dem Landgericht Hamburg um 13:30 Uhr
Das Verfahren ist öffentlich.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Seit Tagen ist in der KI-Welt kaum von etwas anderem die Rede als den beeindruckenden Ergebnissen von Sora.
Sora ist der Name des kürzlich hier vorgestellten Text2Video-Generators der Firma OpenAI, welche auch schon den Text2Bild-Generator Dall‑E und das Text2Text-Generator ChatGPT veröffentlicht hat.
Standbild aus einem Sora-Video [Montage]
Mit Sora können durch simple Texteingaben hochauflösende Videos von bis zu einer Minute Länge generiert werden.
Einen Überblick über die Ergebnisse findet ihr haufenweise, entweder auf der Sora-Seite direkt oder bei YouTube, zum Beispiel in diesem Video:
Ki-Videos, mittels Sora von OpenAI generiert
Auf der offiziellen Webseite wird lang und breit über die Sicherheit des Tools geredet und gerne erwähnt, dass geplant sei, den C2PA-Metadaten-Standard zur Erkennung von KI-generierten Inhalten zu unterstützen. Auffällig ist aber, dass andere Informationen fehlen.
Das Geheimnis der Trainingsdaten
Auffällig ist, dass an keiner Stelle der Vorstellung von Sora darauf eingegangen wird, wie genau das KI-Tool trainiert wurde. Welche Daten wurden dafür verwendet?
Im technischen Report findet sich nur der lapidare Satz: “[…] we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios.“
Ach? Ja, das war uns allen klar, aber welche Videos und Bilder habt ihr dafür nun genau benutzt?
In der Vergangenheit hat sich OpenAI nicht mit Ruhm bekleckert, wenn es um Rücksicht auf Urheberrechte bei Trainingsdaten ging.
Auch beim zweiten Produkt von OpenAI, ChatGPT, liegt die Sache ähnlich. OpenAI wird gerade von der Zeitung New York Times verklagt, weil urheberrechtlich geschützte Trainingsdaten der Zeitung für das KI-Training von ChatGPT benutzt worden seien.
Bei einer Zeugenanhörung von OpenAI durch das Oberhaus des britischen Parlaments fiel seitens OpenAI auch der folgenschwere Satz:
„Because copyright today covers virtually every sort of human expression–including blog posts, photographs, forum posts, scraps of software code, and government documents–it would be impossible to train today’s leading AI models without using copyrighted materials. Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today’s citizens“
Frei übersetzt: Ohne den Zugriff auf urheberrechtlich geschützte Trainingsdaten könnten wir unsere Tools nicht anbieten.
Genau wegen diesem bisher schon bekannten rücksichtslosen Umgang mit Urheberrechten muss eine Frage viel lauter gestellt werden:
Welche Videos und Bilder wurden für das Training der Sora-KI verwendet?
Die Wahrscheinlichkeit ist sehr hoch, dass auch hier – ähnlich wie beim Training von Dall‑E und ChatGPT urheberrechtlich geschützte Videos (und Bilder) zum Einsatz kamen.
Selbst Wasserzeichen in Videos sind für KI-Entwickler schon lange kein Hindernis mehr. Schon 2017 hat Google selbst eine Technik vorgestellt, mit der Wasserzeichen aus Bildern entfernt werden können.
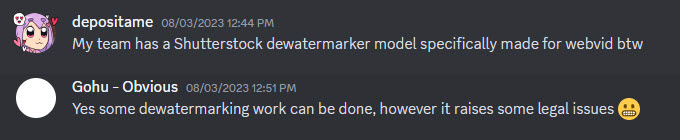
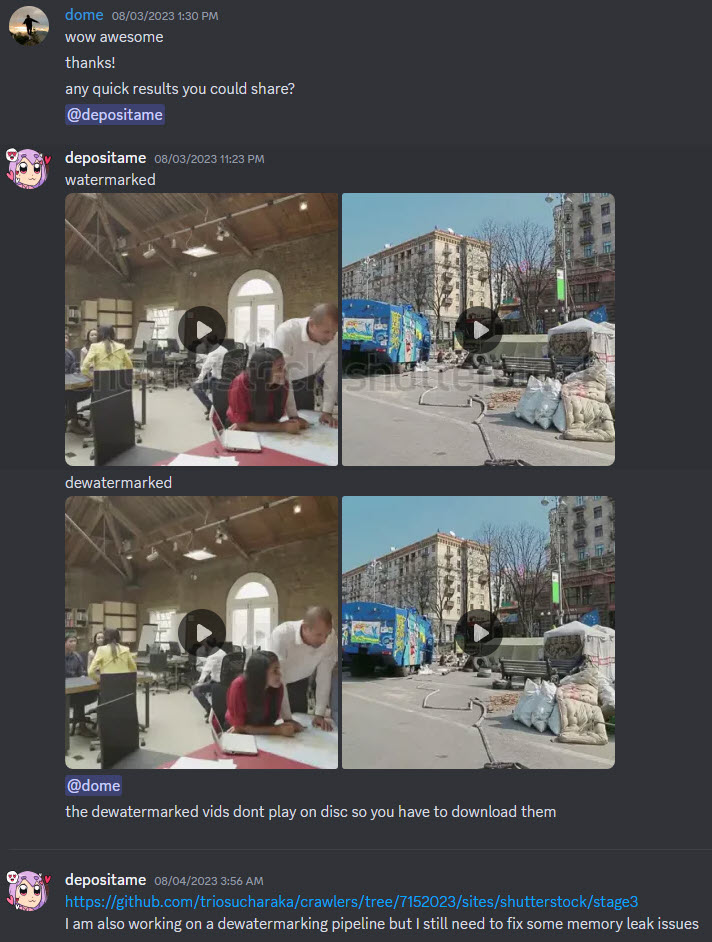
Auch der LAION-Verein bietet auf GitHub ein kostenloses Tool für die „Wasserzeichen-Erkennung“ an. Von der Erkennung zur Entfernung ist es für geübte Programmierer dann nur noch ein kleiner Schritt, über den aus rechtlichen Gründen nicht so gerne öffentlich geredet wird. Manchmal aber doch:
Aus dem #video-generation Kanal des Discord-Servers von LAION
Aus dem #video-generation Kanal des Discord-Servers von LAION
Bei LAION wird zwar an einem eigenen Text2Video-Generator namens phenaki gearbeitet, die technischen Details des Trainings sind denen von Sora aber sehr ähnlich, soweit ich das beurteilen kann.
Die Wahrscheinlichkeit, dass OpenAI daher mit der gleichen Rücksichtslosigkeit wie LAION gegenüber Urhebern beim KI-Training vorgeht, halte ich für hoch, zumal die bisherigen Aussagen und Handlungen von OpenAI leider nicht geeignet sind, Zweifel zu zerstreuen.
Beim ganzen Hype vom SORA und dem Staunen über die tollen Ergebnisse sollte nicht vergessen werden zu fragen, welche (Video-)Künstler beim Training beteiligt waren.
Auf meiner Facebook-Seite hatte ich hier kürzlich gefragt, wie groß das Interesse sei, die Erstellung von solchen interaktiven 360°-Bildern zu lernen:
Da der Andrang groß war, gibt es heute das komplette Tutorial, wie ihr diese 360-Grad-Bilder selbst erstellen und anzeigen lassen könnt. Klickt gerne mit der Maus auf das Bild, um die Ansicht zu ändern oder unten rechts auf das „VR“-Symbol, um das Gleiche im Vollbild-Modus zu machen.
1. Die Bilderstellung
Zuerst braucht ihr dafür natürlich Zugang zu einem Generativen KI-Programm. Ich arbeite bevorzugt mit Midjourney, aber getestet habe ich es auch mit Dall‑E 3 und prinzipiell sollte es – je nach Qualität des KI-Generators – auch mit anderen Tools wie Adobe Firefly oder Stable Diffusion funktionieren.
Als Prompt habe ich bei Midjourney diesen hier verwendet (die eckige Klammer sollte weggelassen werden, mehr dazu unten):
/imagine 360° equirectangular photograph of [an empty futuristic spaceship commando room interior] –ar 2:1 –v 6.0–style raw
Wichtig sind hier vor allem die ersten beiden Begriffe 360° und die gleichwinklige Projektion (equirectangular projection) sowie das Seitenverhältnis von 2:1, welches im Midjourney-Prompt durch das Parameter-Kürzel –ar definiert wird.
Bei der gleichwinkligen Projektion wird diese aus einem einzigen Bild zusammengesetzt, wobei der horizontale Winkel 360° und der vertikale 180° beträgt. Daher sollte das Seitenverhältnis 2:1 sein, um unnötige Verzerrungen zu vermeiden. Adobe Firefly kommt z.B. nur bis zum Seitenverhältnis 16:9, weshalb die Ergebnisse weniger überzeugend aussehen.
Die Versionsnummer (v6) und der Style (raw) sind Geschmackssache und können variiert werden. Ich habe diese gewählt, weil sie aktuell die beste Renderqualität (v6) liefern bei realistisch anmutendem Ergebnis (raw).
Statt des Raumschiff-Prompts in der eckigen Klammer könnt ihr natürlich eurer Fantasie freien Lauf lassen. Beim oben verlinkten Facebook-Post lautete der Prompt zum Beispiel:
/imagine 360° equirectangular photograph of the rainforest –v 6.0 –ar 2:1 –style raw
Ihr könnt aber auch deutlich elaborierter in eurer Beschreibung werden, wenn ihr wollt.
Midjourney zeigt euch dann vier Auswahlmöglichkeiten an. Hier solltet ihr bei der Wahl eures Favoriten schon darauf achten, ob die linke und rechte Bildkante sich halbwegs dazu eignen, miteinander verbunden zu werden.
Die vier Ergebnisse des ersten Prompts
Im obigen Beispiel habe ich mit einem roten Pfeil markiert, wo die KI einen Lichteinfall gerendert hat, der sich nicht auf der rechten Kante wiederfindet. Das würde die optische Illusion zerstören. Beim oberen linken Bild sind oben und unten schwarze Balken, die ebenfalls störend sind. Daher habe ich mich für das Bild links unten entschieden.
Hinweis: Es gibt in Midjourney auch den Parameter „–tile“, der dafür sorgen soll, dass die Bilder nahtlos kachelbar sind, was für unsere Zwecke erst mal prinzipiell gut klingt. Manchmal funktioniert es auch gut, aber leider achtet Midjourney dann auch darauf, dass die obere und untere Kante zusammenpassen, was bei Außenaufnahme, wo oben Himmel und unten Erde ist, selten gute Ergebnisse bringt. Bei Innenaufnahmen ist die Trefferquote höher. Daher: Einfach mal testen.
Das fertige Bild wird mit „U3“ vergrößert (upscaling) und dann noch mal „Upscale (Subtle)“ vergrößert. Damit haben wir schon eine Auflösung von 1536x3072 Pixeln. Wer will, kann diese Auflösung mit einer der hier aufgezählten Upscale-Methoden noch weiter erhöhen. Das Raumschiff-Bild habe ich mit Topaz Photo AI auf 3072x6144 Pixel vergrößert.
Wie schon oben erwähnt, funktioniert es prinzipiell auch mit ChatGPT, wenn auch das Seitenverhältnis nicht korrekt als 2:1 ausgegeben wurde und die fertige Auflösung geringer ist:
2. Die Bildbearbeitung
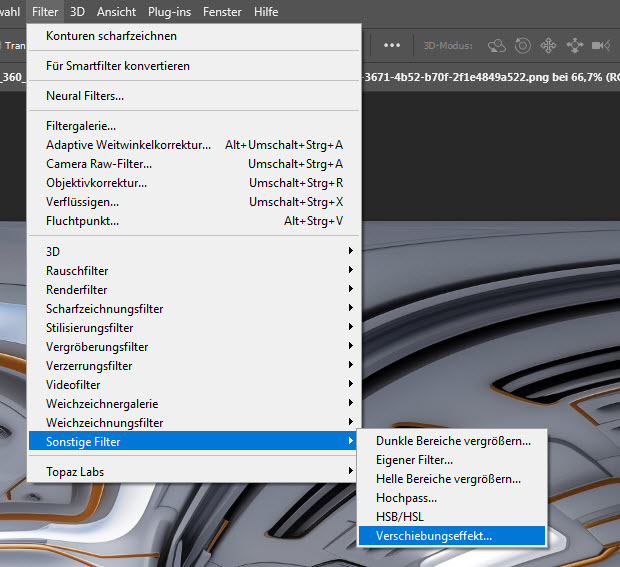
Das fertige PNG-Bild öffne ich nun in Photoshop und wähle den Befehl „Verschiebungseffekt“ (unter Filter/Sonstige Filter):
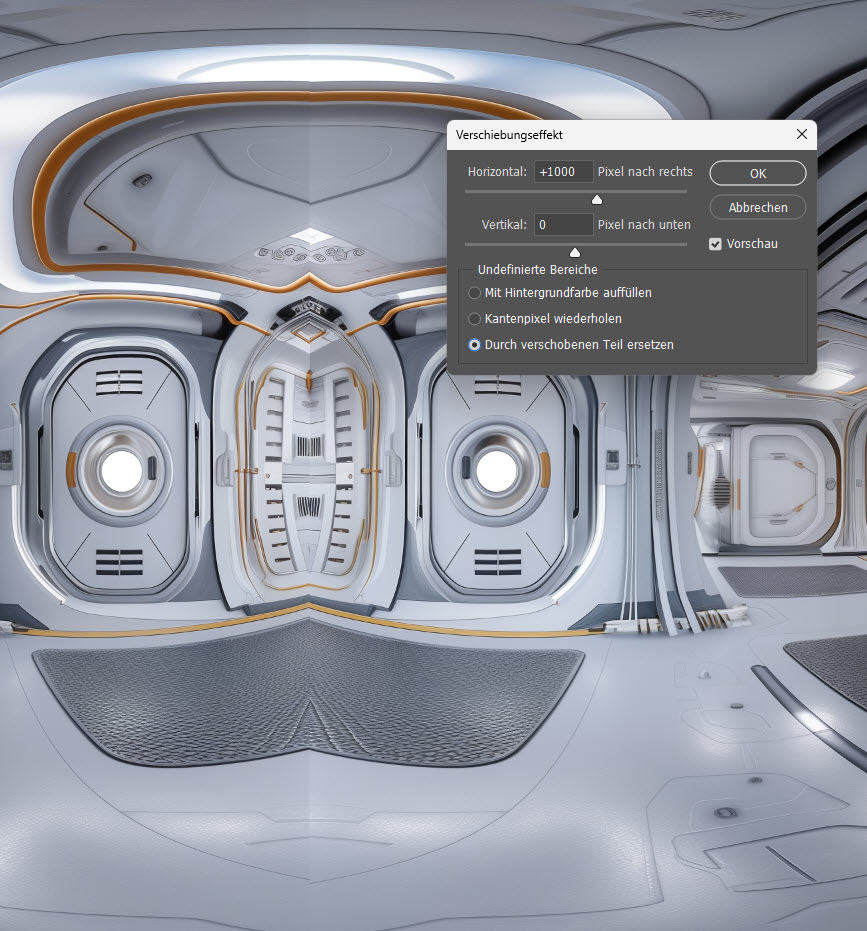
Im sich öffnenen Menüfenster gebe ich nun „horionzal +1000 Pixel nach rechts“ ein. Wichtig ist, dass unten die Option „Durch verschobenen Teil ersetzen“ aktiv ist.
Damit verschiebt sich das Bild um eintausend Pixel nach rechts und wir sehen auch im Screenshot schon, wo die Nahtkante unseres Bildes ist. Diese können wir mit den Photop-Bordmitteln wie „generatives Entfernen“, „generatives Füllen“ und den altbekannten Stempel-Werkzeugen bearbeiten, bis die Kante nicht mehr so stark erkennbar ist. Tipp: Einfach den Übergang komplett mit dem rechteckigen Auswahlwerkzeug markieren und „Generatives Füllen“ anklicken, wirkt oft wahre Wunder.
Hier meine bearbeitete Version:
Zusätzlich könnt ihr natürlich je nach Belieben das Bild vom Farbton, Kontrast etc. anpassen oder andere Bildbereiche verbessern, entfernen oder austauschen.
Wenn ihr fertig seid, könnt ihr den „Verschiebungseffekt“ in die andere Richtung (also ‑1000) anwenden, damit das Bild wieder in seine Ausgangsposition verschoben wird.
Das ist nicht unbedingt notwendig, aber die meisten 360°-Anzeigen nutzen die Bildmitte als Startpunkt, welcher dadurch von uns beeinflusst werden kann.
Das fertige Bild sollte als JPG abgespeichert werden.
3. Die Bild-Metadaten
Damit Tools unser Bild nun auch als „echtes“ 360°-Bild erkennen, müssen wir manuell Metadaten hinzufügen, welche durch 360°-Kameras erzeugt werden. Wir täuschen damit quasi vor, unser KI-Bild sei mit einer richtigen Kamera aufgenommen worden.
Die Pixelwerte können (und sollten) natürlich abweichen, wenn euer Bild andere Pixelmaße aufweist.
Damit ihr nicht wie der letzte Höhlenmensch in eure EXIF-Daten eingreifen müsst, gibt es verschiedene Offline- und Online-Tools, welche das für euch übernehmen.
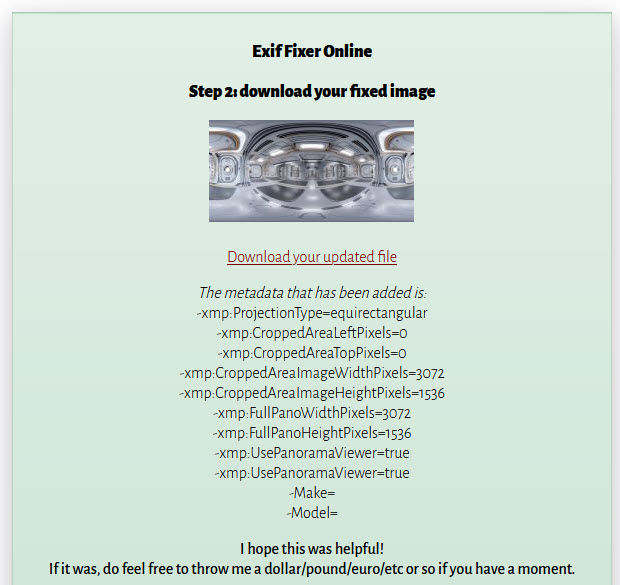
Ich nutze selbst gerne den „Exif Fixer Online“. Dieser unterstützt JPG-Bilder bis zu 15 MB. Nach dem Hochladen des Bildes erhaltet ihr einen Link, wo ihr die „gefixte“ Version mit den korrekten Metadaten runterladen könnt:
WICHTIG: Damit die Datei als 360°-Bild ausgelesen werden kann, müssen diese Metadaten intakt bleiben. Das Versenden der Datei mit Whatsapp oder Email etc. kann dazu führen, dass diese Metadaten wieder gelöscht werden und das Bild nicht interaktiv angezeigt werden kann.
4. Die Anzeige
Kommen wir zur Belohnung für unsere Mühen. Damit wir das 360°-Bild anzeigen lassen können, müssen wir es irgendwo hochladen, wo diese Art der Anzeige unterstützt wird.
Hier im Blog habe ich auf die Schnelle das kostenlose Plugin „Algori 360 Image“ installiert, es gibt aber auch etliche andere.
Eine andere Möglichkeit ist das Hochladen des Bildes bei Facebook oder Google Photos. Zusätzlich gibt es hier eine Liste von weiteren Apps, welche diese 360°-Anzeige unterstützen.
5. Galerie und Material zum Testen
Wer sehen will, dass das oben kein Glückgriff war, sondern auch mehrmals funktioniert, kann sich hier meine „360° KI-Bilder“-Galerie auf Facebook ansehen.
Wer gerade keinen Zugriff auf einen KI-Generator hat, kann sich die Rohdaten für die Galerie-Bilder hier runterladen, direkt ohne Bildbearbeitung aus Midjourney exportiert. Die jeweiligen Prompts findet ihr in den Metadaten in der Bildbeschreibung oder in der Facebook-Galerie.
Wichtiger Hinweis: Die Bilder sind die rohen Ausgangsbilder, es müssen also weiterhin die Schritte 2–4 durchlaufen werden, wenn die Bilder 360°-tauglich werden sollen. Alternativ könnt ihr die Bilder direkt in der Galerie ansehen.
Meine Klage gegen den deutschen Verein LAION e.V., welcher unter anderem Trainingsdatensätze für KI-Anwendungen bereitstellt, hat weltweit für viel Aufmerksamkeit gesorgt.
Da es auch regelmäßig viele Anfragen zum aktuellen Stand des Verfahren gibt, hier ein kurzes Update.
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt.
Der Verein LAION e.V. sieht das naturgemäß anders, wie in den beiden zitierten Blogartikeln gut erkennbar ist. Daher blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
25.04.2024 um 13:00 Uhr: Gerichtstermin vor dem Landgericht Hamburg (Update 12.4.2024: Die Uhrzeit wurde geändert)
Das Landgericht Hamburg hat also in ca. einem halben Jahr den Gerichtstermin angesetzt, in dem dann mündlich weiter über die Klage verhandelt werden wird. Das Verfahren ist öffentlich. Hier die aktuelle Zusammenfassung des Falls durch die mich vertretende Kanzlei SLD.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Schon drei Mal haben Silke Güldner und ich zusammen in Hamburg einen ganztätigen Praxis-Workshop zum Thema „KI in der Berufsfotografie“ gegeben.
Jedes Mal war der Workshop schnell ausgebucht und über unsere Social-Media-Kanäle erreichte uns oft der Wunsch, ob wir das Ganze auch online anbieten würden.
Deshalb wird der vierte Workshop nun online stattfinden am Freitag, den 26.01.2024.
Seit anderthalb Jahren beschäftige ich mich nun schon intensiv mit der Bilderstellung durch Künstliche Intelligenz. Zusammen mit meinem Team habe ich mittlerweile ein Portfolio von über 7000 KI-Bildern, welche ich bei Bildagenturen anbiete.
„Hintergründe & Möglichkeiten der KI-Tools in der fotografischen Praxis mit KI-Experte & Fotograf Robert Kneschke und Fotografenberaterin Silke Güldner
Der Workshop bietet eine einzigartige Gelegenheit, um tiefer in die Welt der künstlichen Intelligenz einzutauchen und ihre Anwendungsmöglichkeiten in der Fotografie zu entdecken. Hier lernen Profi- und Nachwuchsfotografen die Funktionsweise und verschiedenen KI-Tools kennen, können diese im praktischen Teil selbst ausprobieren und diese für ihre eigene Positionierung im Markt reflektieren. Durch Diskussionen und den Austausch mit der Gruppe und den Referenten erhalten sie darüber hinaus auch Feedback und Inspirationen für ihre künftige Arbeit und die Kommunikation mit ihren Kunden. Am Ende des Workshops sind die Teilnehmer bestens vorbereitet, um die Entwicklungen und Herausforderungen im Kontext von KI und Fotografie zu verstehen und zukünftige Möglichkeiten zu nutzen.
Inhalte
Einführung KI
Wie funktioniert KI-Bilderstellung
Vorstellung der Tools Stable Diffusion, Dall‑E 3, Midjourney, Firefly
Anwendungsmöglichkeiten, Unterschiede und Motivbeispiele
Praxis Teil 1
Anhand der Teilnehmer-Portfolios sprechen wir über Möglichkeiten, die KI für die eigenen Ziele bieten kann und wann konventionelle Fotografie der bessere Weg ist
Portfolio Vorstellung der Teilnehmenden
Vorteile und Nutzen von konventioneller Fotografie gegenüber KI-Lösungen in der Kundenberatung
Praxis Teil 2
Hands On & Live Demos
Testen der KI-Tools am Beispiel von Midjourney
Erläuterung von Prompt-Engineering, In- and Outpainting
Tools für den KI Workflow
Überblick der Nutzungsmöglichkeiten & Best Practice Beispiele
Meta Themen
Rechtliche & moralische Probleme der KI-Nutzung
Veränderung der Berufsfotografie & Einfluss auf die Preisfindung
Ausblick & Kooperationsmöglichkeiten“
Der Workshop wird am Freitag, den 26.01.2025 online stattfinden, mehr Informationen zur Veranstaltung findet ihr hier auf der Webseite des Veranstalters Photo+Medienforum Kiel.
Die Teilnehmer*innen ist begrenzt, also zögert nicht, euch bei Interesse rechtzeitig euren Platz zu sichern.