Einer meiner meistgelesenen Artikel im Blog dieses Jahr ist „Rafael Classen verschickt „Abmahnungen“ an Bildkäufer wegen Social Media Nutzung“ sowie der Folgeartikel „Zwickmühlen-Falle: Neue „Abmahnungen“ durch Rafael Classen (RC Photostock) gegen Bildkäufer“.
Da mich weiterhin regelmäßig Kontaktanfragen betroffener Bildkäufer erreichen und sich bei dem Thema einiges getan hat, gibt es heute ein kurzes Update.

Fehlende oder gelöschte IPTC-Metadaten
Betrafen die ersten „Abmahnungen“ von Rafael Classen hauptsächlich angebliche unpassende Social-Media-Nutzungen, ist er nun umgeschwenkt auf angeblich gelöschte IPTC-Metadaten.
Als Nachweis für die angeblich gelöschten IPTC-Metadaten führt er zwei Links bei Spiegel Online und dem Bundesumweltministerium an, die Bilder von Herr Classen nutzen. Diese Bilder enthalten zwar tatsächlich Urhebernachweise in den IPTC-Daten, jedoch sind diese laut IPTC-Daten bei EyemEm/Getty Images bzw. iStock gekauft worden. Daraus lässt sich nicht ableiten, dass seine Bilder bei Adobe Stock oder Fotolia Urhebernachweise enthielten.
Classen verweist in seinen Emails gerne ausführlich darauf, dass Adobe Stock in deren Lizenzbestimmungen „eine Entfernung der urheberrechtlich geschützten Schutzrechtshinweise in den IPTC-Metadaten in keiner Lizenz erlaubt“.
Er vergisst jedoch zu erwähnen, dass die Anbieter bei Adobe Stock spätestens seit Juli 2016 beim Upload von Bildern den Nutzungsbedingungen zugestimmt haben, in denen unter anderem steht:
„5.2 […] Des Weiteren dürfen Metadaten ohne Haftung durch uns, unsere Vertriebshändler oder unsere Benutzer geändert, entfernt oder erweitert werden.“
Am 1. März 2022 gab es eine Aktualisierung dieser Nutzungsbedingungen, in denen nun konkreter steht:
„7.1. […] Sie sind insbesondere damit einverstanden, dass Unternehmen der Adobe-Gruppe Urheberangaben, die in Metadaten enthalten sind, entfernen oder modifizieren und dies auch ihren Nutzern gestatten. Diese Befugnis ist beschränkt auf solche Fälle, in denen Metadaten infolge einer vertragsgemäßen Wahrnehmung von Nutzungs- und Bearbeitungsrechten durch Unternehmen der Adobe-Gruppe oder seine Nutzer (etwa bei Bearbeitung, Übertragung, Ergänzung, Kürzung, Kompilierung, Werkverbindung und Collagierung), z.B. infolge der Verwendung marktüblicher Bearbeitungssoftware, automatisiert entfernt werden.“
Ich vermute, dass die Aktivitäten von Herr Classen ein Grund für die Konkretisierung der Nutzungsbedingungen waren.
Die „marktübliche Bearbeitungssoftware“ agiert aktuell nämlich leider nicht so konsistent, wie normale Benutzer annehmen könnten. Werden Bilder im CMS WordPress für Webseiten mittels einem dort integrierten Bildgrößen-Preset verkleinert, bleiben die IPTC-Metadaten enthalten. Wird ein Bild dort jedoch mit einem manuell vergebenen Wert verkleinert, verschwinden die Metadaten. Da muss mensch erst mal drauf kommen…
Das ist relevant, weil der §95c UrhG eine wissentliche Handlung voraussetzt, die vermutlich nicht gegeben ist, wenn das CMS-Verhalten sich undokumentiert je nach Detaileinstellung unterscheidet.
Rückkehr zu Adobe Stock durch die Hintertür Wirestock
In seinen wirren Emails erklärt Herr Classen lang und breit, dass Adobe Stock ihm die Zusammenarbeit gekündigt habe. Darüber hinaus schreibt er:
„Es besteht keinerlei vertragliche Verbindung mehr zwischen mir und Adobe Stock/ Fotolia, die Firma Adobe Stock/ Fotolia ist hier auch nicht zuständig. Der guten Ordnung halber weise ich nochmals darauf hin, dass die Firma Adobe Stock/ Fotolia seit geraumer Zeit nicht mehr berechtigt ist, Nutzungsrechte an meinen Werken zu gewähren.“
[Update 10.11.2022: Satz aufgrund einer Einstweiligen Verfügung entfernt.] Wirestock ist ein Dienstleister, der es Fotografen erlaubt, die dort hochgeladenen Bilder im Namen von Wirestock an mehrere Microstock-Agenturen gleichzeitig zu verteilen; darunter auch Adobe Stock.
Da die Fotografen diese Auswahl selbst treffen müssen, ist es komisch, dass er weiterhin behauptet, dass Adobe keine Nutzungsrechte an seinen Werken vergeben dürfe.

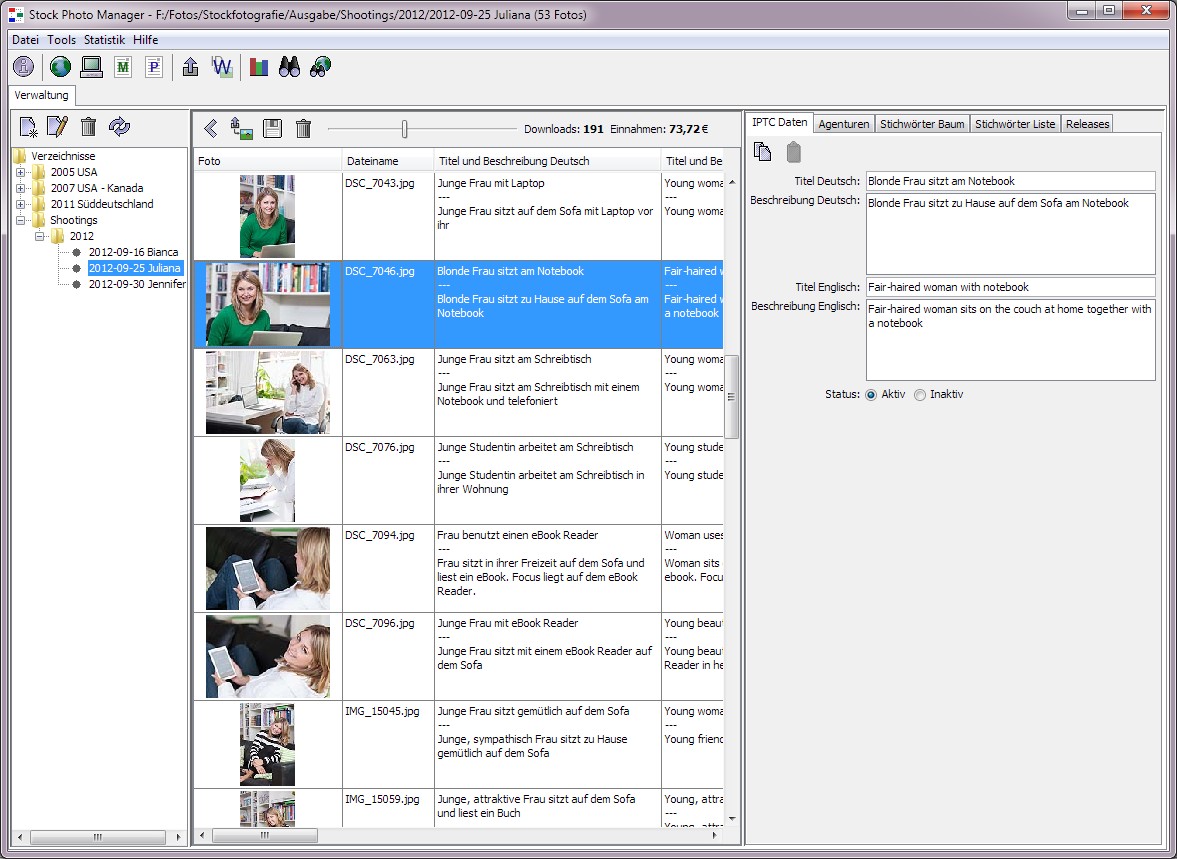
Da Rafael Classen bei Adobe Stock wegen seiner Aktivitäten zahlender Kunden gegenüber nicht gern gesehen ist, ist es sehr nützlich, dass die neuen Bilder von Rafael Classen nun nicht mehr unter seinem Namen dort angeboten werden, sondern im Namen von Wirestock (siehe Screenshot oben).
Woher ich dann weiß, dass obiges Foto tatsächlich von Herr Classen ist?
Das gleiche Bild ist auch in seinem eigenen Webshop RC-Photo-Stock mit der Urheberangabe „rclassen“ erhältlich:
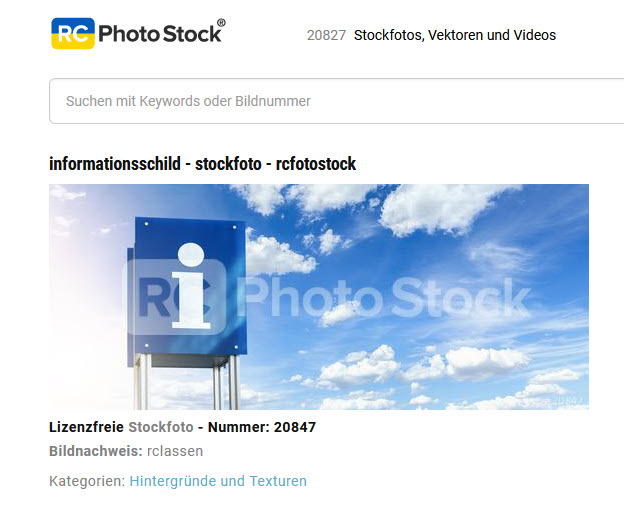
Das ist kein Einzelfall, denn es betrifft etliche Bilder, hier ein zweites Beispiel, diesmal aus dem „Wirestock Creators“-Account bei Adobe Stock:
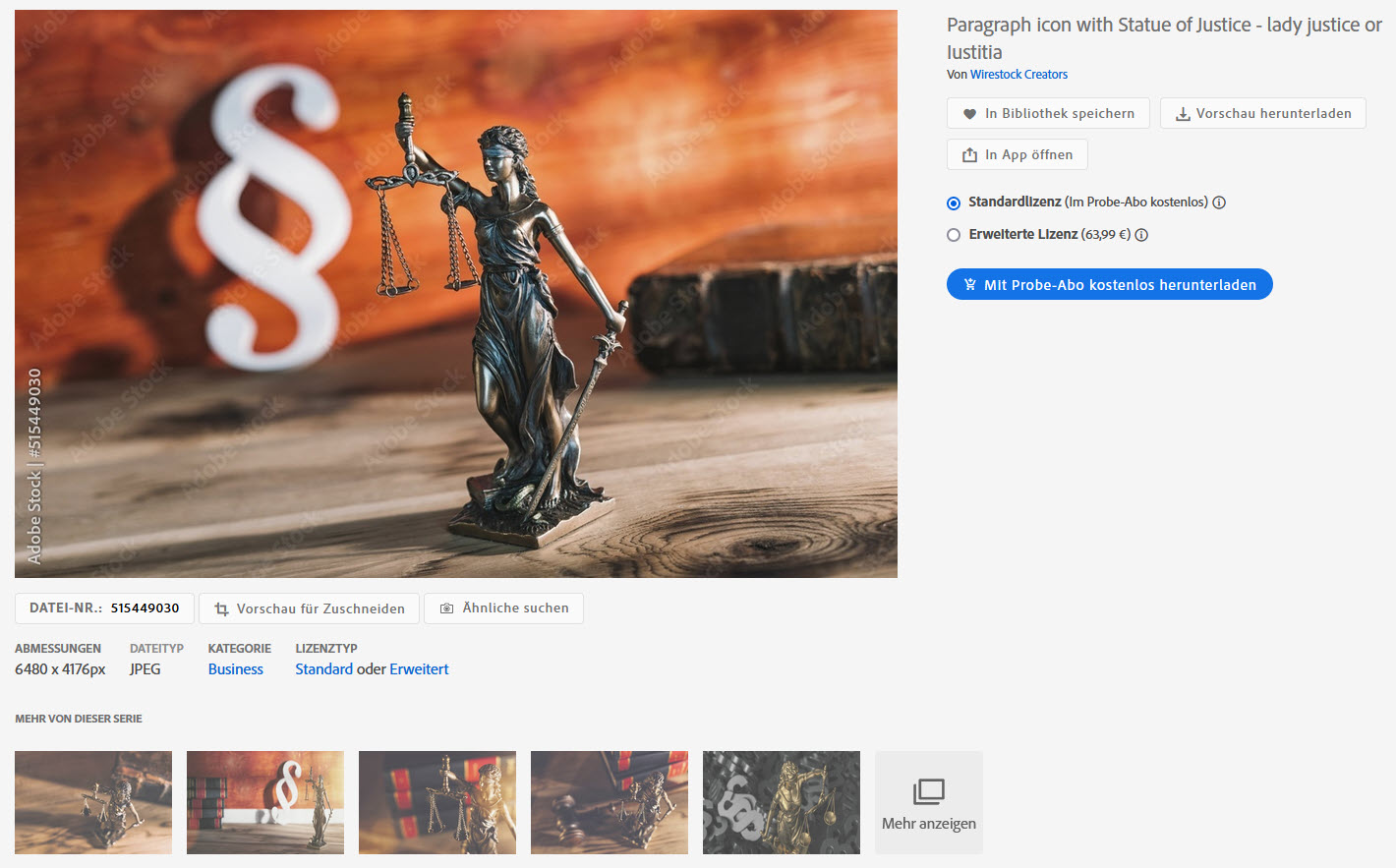
Als Nachweis wieder das gleiche Bild in seinem eigenen Bildershop:

Ironischerweise enthalten die Bilder von Rafael Classen, welche via Wirestock bei Adobe Stock angeboten werden, nur den Urheberhinweis „Wirestock – stock.adobe.com“ in den IPTC-Metadaten. [Update 10.11.2022: Satz aufgrund einer Einstweiligen Verfügung entfernt.]
Wer als zahlender Kunde Streit mit Rafael Classen vermeiden möchte, sollte also auch bei Bildern von Wirestock (und Wirestock Creators) sehr aufpassen, ob das Bild eventuell von Herr Classen sein könnte und Metadaten enthält.
Wie Herr Classen angesichts seiner aktiven Bilder bei Adobe Stock zu der Annahme kommt, dass die Bildagentur keine Nutzungsrechte an seinen Werken einräumen dürfe, ist mir leider schleierhaft. Eine diesbezügliche Anfrage an Herr Classen beantworte dieser leider nur mit einem Verweis auf seine Anwaltskanzlei. Diese schrieb dann:
„Wie Ihrer Presseanfrage inhaltlich zu entnehmen ist, sind Sie mit den Anforderungen der Rechtsprechung an die Gewährung einer hinreichend substantiierten Gelegenheit zur Stellungnahme nicht vertraut. Insofern kann eine Stellungnahme unseres Mandanten nicht erfolgen.“
Am besten wäre es aus Sicht von Herr Classens Anwälten jedoch, wenn ich diese Berichterstattung ganz unterlassen würde:
„Wir mahnen insofern dringend zur Zurückhaltung und zur Einhaltung der erforderlichen Sorgfalt, besser zur Abstandnahme von dem geplanten Vorhaben, dessen Intention zuvörderst unlautere Ziele zum Gegenstand zu haben scheint.“
Abmahnung wegen fehlender Abmahnung
Die Allianz deutscher Designer AGD hatte letztes Jahr den Artikel „Abmahnung wegen der Löschung von Metadaten“ veröffentlicht, um deren Mitglieder vor den Praktiken von Herr Classen zu warnen. Unter anderem wegen der berichteten Abmahnungen mahnte Herr Classen die AGD ab, weil er angeblich keine Abmahnungen, sondern nur „Berechtigungsanfragen“ versenden würde. Blöd ist nur, dass Herr Classen doch richtige Abmahnungen verschickt hatte. Der Fall endete in einem Vergleich, der unter anderem enthielt, dass Herr Classen auf der Webseite der AGD die Möglichkeit bekam, seine Sicht der Dinge darzulegen.
Das machte Herr Classen dann im Artikel „Rechteverfolgung wegen der Löschung von Foto-Metadaten“.
Disclaimer/Full Disclosure: Ich habe aktuell mit Herrn Classen ebenfalls eine juristische Auseinandersetzung in einer anderen Sache.
Update 5.8.2022:
Die Direktorin Kirsten Harris von Adobe Stock Content bat mich, folgendes zu aktualisieren: „Ich […] muss richtigstellen, dass Wirestock Content von Classen aus ihrem Adobe Stock Account entfernt hat. Die beiden Fotos, die Du als Beispiele angezeigt hast, gibt es nicht mehr auf Adobe Stock. Ich bitte Dich, Deinen Beitrag entsprechen upzudaten.“
Update 10.11.2022:
Aufgrund einer Einstweiligen Verfügung, welche Herr Rafael Classen gegen mich erwirkt hat, darf ich zwei Sätze in diesem Artikel nicht mehr veröffentlichen. Der Behauptung der Gegenseite, dass dieser Artikel eine „unwahre Gesamtaussage“ enthalte, konnte das Gericht aber nicht folgen.

 Was für Fotos schon lange gängiger Standard – besser bekannt als
Was für Fotos schon lange gängiger Standard – besser bekannt als