Der für Donnerstag, den 25.4.2024 angesetzte Gerichtstermin fällt aus. Grund dafür ist ein kurzfristiger Antrag des gegnerischen Anwalts, welcher an diesem Termin angeblich verhindert sei.
Das Gericht hat diesem Antrag eben stattgegeben. Der Termin wurde verlegt auf: Donnerstag, den 11.07.2024, 13:30 Uhr, Sitzungssaal A 265, 2. Etage, Sievekingplatz 1 (Ziviljustizgebäude) in Hamburg.
Ich bedauere diese Verzögerung und habe irgendwie das Gefühl, dass LAION e.V. vielleicht lieber noch ungestört, ach, lassen wir die Spekulationen…
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt. Da LAION auf meine Abmahnung nicht zu unserer Zufriedenheit reagieren wollte, blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
15.04.2024: Stellungnahme des Gegenanwalts zu unserem Schriftsatz
19.04.2024: Antrag der Gegenseite auf Terminverschiebung (ursprünglich angesetzter Termin war am 25.04.2024)
11.07.2024: Neuer Gerichtstermin vor dem Landgericht Hamburg um 13:30 Uhr
Das Verfahren ist öffentlich.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Vor ziemlich genau zehn Jahren habe ich diesen ausführlichen Artikel über das Problem mit „Copycats“ in der Stockfotografie geschrieben.
Darin beschreibe ich die unfairen Vorteile, welche sich Mitbewerber verschaffen, wenn sie systematisch Besteller-Bilder anderer Fotografen kopieren und wie schwer es ist, dagegen vorzugehen:
„Rechtlich gesehen ist es leider schwer, gegen solche Kopien anzugehen, weil „nachgestellte Fotos“ im Gegensatz zu „identischen Fotos“ nicht automatisch einen Urheberrechtsverstoß bedeuten. Da kommt es darauf an, wie ähnlich sich Kopie und Original sehen und ist meist eine Auslegungssache des Gerichts.“
(Auszug aus dem zitierten Blogartikel)
Die Grenzen zwischen Inspiration und Plagiat sind auch schwer zu greifen, weshalb sich in der Stockfotografie-Szene meist der Gedanke durchgesetzt hat, dass wir alle irgendwo irgendwann von jemandem kopieren und ebenso kopiert werden. Das gehöre irgendwie dazu, vor allem, weil sich die gut verkaufenden Themen kaum ändern und so wenig Spielraum für Ausweichmöglichkeiten bleibt, wenn mensch diese Motive abdecken möchte („Business-Handshake“, anyone?).
So muss ich als durch meinen Blog und meine Publikationen besonders in der Öffentlichkeit stehender Stockproduzent meist zähneknirschend hinnehmen, wenn sich andere aus meinem großen Bilderfundus mehr oder weniger detailgenau bedienen als Inspirationsquelle.
Das Bild und die Kopie
Manchmal gibt es aber Motive, auf die unser Team besonders stolz ist, weil sie eben noch nicht hundertfach vorhanden sind, vor allem, wenn diese sich dann auch noch sehr gut verkaufen.
Als Beispiel hier dieses 3D-Rendering meines 3D-Grafikers von einem schwebenden Sofa, seit November 2015 im Adobe Stock Portfolio (damals noch Fotolia):
Unser Original-3D-Rendering…
Ich rieb mir nicht schlecht die Augen, als ich im Februar 2020 im Adobe Stock Portfolio des Fotografen Rafael Classen dieses Bild sah:
…und das Bild von Classen
Es ist das gleiche Sofa, die gleiche Topfpflanze, der gleiche Beistelltisch, und die gleiche Korkenlampe. Selbst die Kissen, welche beim Sofa (ein 3D-Modell der Firma Evermotion, u.a. aus diesem Set) brav auf dem Sofa platziert waren, wurden in fast identischer Kombination genutzt. Auch die Farbwahl ist sehr ähnlich, die Gemeinsamkeiten beider Bilder sind auf den ersten Blick größer als die Unterschiede.
Das Bild von Classen unterscheidet sich in marginalen Details: Der Fußboden ist zum Beispiel dunkler mit anderem Muster, die Fernbedienung ist ein anderes Modell und das Bild hat weniger Vignettierung und ein anderes Seitenverhältnis.
Herr Classen hatte schon vorher einige Bilder in seinem Portfolio, welche meinen Bildern (und denen anderer Kollegen) meiner Ansicht nach auffällig ähnlich sahen, aber hier wollte ich doch eine Grenze ziehen.
Ich meldete die Kopie via DMCA-Formular an Adobe Stock, welche diese daraufhin sperrte, bis der Anbieter Widerspruch einlegte. Nach den Regeln von Adobe müsste ich nun nachweisen, dass meine Meldung rechtlich nachvollziehbar sei, sonst würde die Kopie wieder in den Verkauf kommen.
Also forderte ich durch meinen Anwalt in einer Abmahnung die Abgabe einer Unterlassungserklärung, was Classen ablehnte. Daraufhin reichten wir im April 2020 Klage wegen Urheberrechtsverletzung ein.
Kurz darauf reichte Classen eine Widerklage gegen mich wegen Urheberrechtsverletzung ein, weil er der Ansicht war, ich hätte fünf seiner Bilder kopiert.
Die Gerichtsentscheidungen: 1. LG München
Vor dem Landgericht München wurde unsere Klage (und auch die Widerklage) im Dezember 2021 abgewiesen. Hauptsächlich mit der Begründung, alle Werke seien nicht durch das Urheberrecht geschützt, weil es nach §72 UrhG weder ein Lichtbild (aka „Foto) noch ein Werk nach §2 UrhG sei:
„Inwiefern ein lichtbildähnlicher Schutz auch für Computerbilder bzw. Computeranimationen sowie mit Hilfe der Digitaltechnik veränderte oder neukomponierte Bilder gewährt wird, ist umstritten (Dreier/Schulze, UrhG, 6. Aufl., § 72, Rn. 7, 8 m.w.N.; verneinend KG, GRUR 2020, 280). Ausgangspunkt der vorzunehmenden Auslegung des § 72 UrhG ist der Wortlaut der Norm, wonach maßgeblich auf den Schaffensvorgang und nicht auf das Ergebnis des Schaffensprozesses abgestellt wird. Dementsprechend kann für die Beantwortung der Frage, was unter „Erzeugnissen, die ähnlich wie Lichtbilder hergestellt werden“ zu verstehen ist. allein das Ergebnis des Herstellungsverfahrens letztlich nicht maßgeblich sein. Erforderlich ist nach dem Wortlaut der Norm vielmehr, dass ein ähnliches Herstellungsverfahren wie bei der Erstellung von Lichtbildern angewandt wird. Insoweit kommt es jedoch nicht entscheidend auf den Schaffensvorgang aus Sicht des Anwenders der Technik, sondern auf die Vergleichbarkeit der technischen Prozesse an. Für die Ähnlichkeit der Prozesse spricht, dass bei der Erstellung einer Computergrafik auch Gegenstände zunächst räumlich in ganz bestimmter Weise zueinander angeordnet, eine bestimmte Farbwahl getroffen und sodann gegebenenfalls über Art, Anzahl und Position der Lichtquellen entschieden wird. Dies genügt jedoch nicht, um von einem lichtbildähnlichen Erzeugnis auszugehen. Zentrales Argument für die Privilegierung der Lichtbilder war der Einsatz der Technik der Fotografie. Im Fokus steht dabei die technische und nicht die schöpferische Leistung. Charakteristische Merkmale der Fotografie sind aber zum einen der Einsatz von strahlender Energie und zum anderen die Abbildung eines im Moment der Bilderschaffung vorhandenen, körperlichen Gegenstands (OLG Köln, GRUR-RR 2010, 141, 142; KG, GRUR 2020, 280, 284; BeckOK UrhR/Lauber-Rönsberg, 32. Ed. 15.9.2021 , UrhG, § 72, Rn. 33).
Beide Merkmale erfüllt das streitgegenständliche Rendering indes nicht. Es handelt sich hierbei gerade nicht um eine unter Einsatz strahlender Energie erzeugte selbstständige Abbildung der Wirklichkeit, sondern vielmehr um eine mittels elektronischer Befehle erzeugte Abbildung von virtuellen Gegenständen.“
aus dem Urteil des LG München vom 3.12.2021
Angesichts der modernen Technik, die schon jahrzehntelang Einzug in die Bildproduktion gehalten hatte, wollten wir nicht so recht glauben, dass wir keine Urheberrechte an unserem Bild hätten, nur weil es kein Foto, sondern ein 3D-Rendering sei.
Deshalb legten wir Berufung gegen das Urteil ein. Auch Rafael Classen legte Berufung wegen seiner abgewiesenen Widerklage ein.
2. OLG München
Wie wir gehofft hatten, betrachtete das Oberlandgericht München den Fall differenzierter und fällte am 29.6.2023 ein Urteil zu unseren Gunsten (OLG München, Aktenzeichen 29 U 256/22).
Erstens wurde anerkannt, dass auch 3D-Renderings Urheberschutz genießen können, wenn sie eine gewisse künstlerische Leistung erkennen lassen. Ausführlicher wird dieser Aspekt in diesem Blogpost auf der Webseite meines Anwalts zitiert.
Zweitens legt das OLG München ausführlich dar, unter welchen Bedingungen nicht nur direkte Kopien eines Originals, sondern auch Varianten davon schutzfähig sein können:
„[…] Ist die Veränderung der benutzten Vorlage indessen so weitreichend, dass die Nachbildung über eine eigene schöpferische Ausdruckskraft verfügt und die entlehnten eigenpersönlichen Züge des Originals angesichts der Eigenart der Nachbildung verblassen, liegt keine Bearbeitung oder andere Umgestaltung i.S.d. § 23 Abs. 1 Satz 1 UrhG […], sondern ein selbstständiges Werk vor, das in freier Benutzung des Werks eines anderen geschaffen worden ist und das […] ohne Zustimmung des Urhebers des benutzten Werks veröffentlicht und verwertet werden darf.“
Genau diese Bedingung sei in unserem Fall aber nicht erfüllt worden:
„Bei einem Vergleich des Gesamteindrucks der beiden Gestaltungen zeigt sich, dass dieser auch im Rendering des Beklagten durch ebendiese Elemente, das impulsbedingte Abheben, die Wellenform, den Hintergrundkontrast und – in etwas geringerem Maße – durch den Schattenwurf bestimmt werden. Gerade die wellenförmige Ausrichtung der Einzelelemente mit ihren einzelnen Drehrichtungen und Neigungswinkeln ist praktisch identisch zum klägerischen Rendering und erzeugt in gleicher Weise den Eindruck eines kurz nach dem Abheben der Dinge erfolgten Schnappschusses, wobei auch der Kontrast der größtenteils hellen Elemente vor einem ähnlichen Blauton im Hintergrund die Wirkung verstärkt. Die Unterschiede der Gestaltungen, die vor allem durch einen dunkleren Boden mit stärkerer Zeichnung der Bohlen sowie den sich stärker auf der Wand als auf dem Boden abzeichnenden Schattenwurf bestimmt werden, prägen den Gesamteindruck beim Rendering der Beklagten dagegen nicht so nachdrücklich, dass die sich aufdrängenden und ins Auge stechenden Übereinstimmungen in ihrer Gesamtwirkung verblassen würden. Da durch den stark übereinstimmenden Gesamteindruck beider Renderings die ursprüngliche klägerische Gestaltung beim Rendering des Beklagten deutlich wiederzuerkennen ist, greift dessen Gestaltung in den Schutzbereich des älteren klägerischen Werkes ein.“
3. Die Widerklage
Rafael Classen behauptet in seiner Widerklage, ich hätte mit diesen fünf Werken seine Urheberrechte verletzt, weil er fast identische Bilder vorher erstellt hätte:
Großes weißes Fragezeichen vor gelber Wand mit Textfreiraum als FAQ Konzept
Kontakt und Kommunikation Symbole vor gelber Wand als Hintergrund
Leute auf Messe unter einem leeren Werbeplakat oder Werbebanner
Viele anonyme verschwommene Leute gehen im Einkaufszentrum einkaufen
Anonyme unscharfe Menschenmenge unterwegs auf einer Business Messe
Bei den beiden gelben 3D-Renderings mit den Icons an der Wand lehnte das Oberlandgericht München die Berufung der Widerklage mit Verweis auf die zu geringe Schöpfungshöhe ab:
„Bezüglich der Renderings des Beklagten […] ist dem Landgericht darin zu folgen, dass diese nicht die nötige Gestaltungshöhe im Sinne von § 2 Abs. 2 UrhG aufweisen und daher keinen Werkschutz im Sinne von § 2 Abs. 1 Nr. 4 oder Nr. 5 UrhG genießen.
Es handelt sich jeweils um im Schriftverkehr übliche Zeichen in einer üblichen Schrifttype, die im weitesten Sinne mit Kommunikation zu tun haben, wofür wiederum die Wahl der Farbe Gelb und des konkreten Farbtons wegen der Assoziation zu Postdienstleistungen besonders naheliegend erscheint. Der durch das Anlehnen an einer Wand, den Schattenwurf und die Spiegelung auf dem Boden entstehende räumliche Eindruck ist ebenfalls im Bereich von Logos und in der Werbegrafik hinlänglich geläufig und hebt die beiden Gestaltungen nicht vom Alltäglichen und handwerklich Üblichen ab.“
Bei den drei Fotos der Kölner Messe sei zwar die Schöpfungshöhe erreicht, aber unberechtigte Kopien seien meine Fotos nicht:
„Auch sofern man in den Aufnahmen des Beklagten bloße Lichtbilder nach § 72 UrhG erblicken würde, fehlte es an einer Verletzung, da diese nach dem oben Gesagten keinen Motivschutz gegen nichtidentische oder nicht nahezu identische Gestaltungen genießen, so dass es sogar jedermann freisteht, das gleiche vorgegebene Motiv vom selben Standort und unter denselben Lichtverhältnissen noch einmal aufzunehmen.“
Richtungsweisende Entscheidung
Mit dem Urteil des OLG München haben wir nun die erste Entscheidung seit langem, die sich ausführlich mit dem Motivschutz von 3D-Renderings und Fotos befasst.
Ob Motive nachgestellt werden dürfen, hängt demnach von vielen Faktoren ab, die im Einzelfall geprüft werden müssen. Eine Urheberrechtsverletzung liegt in der Regel dann vor, wenn die den Gesamteindruck prägenden Gestaltungselemente des Originals auch in der Kopie vorliegen.
Weitere Termine
Auch wenn diese Klage erledigt ist, gibt es weitere Gerichtstermine mit Herr Classen. Am Mittwoch, den 8.5.2024 findet vor dem Landgericht Düsseldorf der Gütetermin und Verhandlungstermin wegen „Folgeansprüchen aus Wettbewerbsrechtsverletzung durch Veröffentlichungen eines Mitbewerbers und datenschutzrechtlicher Auskunft“. Die Einstweilige Verfügung in diesem Zusammenhang hat er bisher größtenteils verloren, insofern bin ich auch da zuversichtlich.
Seit Tagen ist in der KI-Welt kaum von etwas anderem die Rede als den beeindruckenden Ergebnissen von Sora.
Sora ist der Name des kürzlich hier vorgestellten Text2Video-Generators der Firma OpenAI, welche auch schon den Text2Bild-Generator Dall‑E und das Text2Text-Generator ChatGPT veröffentlicht hat.
Standbild aus einem Sora-Video [Montage]
Mit Sora können durch simple Texteingaben hochauflösende Videos von bis zu einer Minute Länge generiert werden.
Einen Überblick über die Ergebnisse findet ihr haufenweise, entweder auf der Sora-Seite direkt oder bei YouTube, zum Beispiel in diesem Video:
Ki-Videos, mittels Sora von OpenAI generiert
Auf der offiziellen Webseite wird lang und breit über die Sicherheit des Tools geredet und gerne erwähnt, dass geplant sei, den C2PA-Metadaten-Standard zur Erkennung von KI-generierten Inhalten zu unterstützen. Auffällig ist aber, dass andere Informationen fehlen.
Das Geheimnis der Trainingsdaten
Auffällig ist, dass an keiner Stelle der Vorstellung von Sora darauf eingegangen wird, wie genau das KI-Tool trainiert wurde. Welche Daten wurden dafür verwendet?
Im technischen Report findet sich nur der lapidare Satz: “[…] we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios.“
Ach? Ja, das war uns allen klar, aber welche Videos und Bilder habt ihr dafür nun genau benutzt?
In der Vergangenheit hat sich OpenAI nicht mit Ruhm bekleckert, wenn es um Rücksicht auf Urheberrechte bei Trainingsdaten ging.
Auch beim zweiten Produkt von OpenAI, ChatGPT, liegt die Sache ähnlich. OpenAI wird gerade von der Zeitung New York Times verklagt, weil urheberrechtlich geschützte Trainingsdaten der Zeitung für das KI-Training von ChatGPT benutzt worden seien.
Bei einer Zeugenanhörung von OpenAI durch das Oberhaus des britischen Parlaments fiel seitens OpenAI auch der folgenschwere Satz:
„Because copyright today covers virtually every sort of human expression–including blog posts, photographs, forum posts, scraps of software code, and government documents–it would be impossible to train today’s leading AI models without using copyrighted materials. Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today’s citizens“
Frei übersetzt: Ohne den Zugriff auf urheberrechtlich geschützte Trainingsdaten könnten wir unsere Tools nicht anbieten.
Genau wegen diesem bisher schon bekannten rücksichtslosen Umgang mit Urheberrechten muss eine Frage viel lauter gestellt werden:
Welche Videos und Bilder wurden für das Training der Sora-KI verwendet?
Die Wahrscheinlichkeit ist sehr hoch, dass auch hier – ähnlich wie beim Training von Dall‑E und ChatGPT urheberrechtlich geschützte Videos (und Bilder) zum Einsatz kamen.
Selbst Wasserzeichen in Videos sind für KI-Entwickler schon lange kein Hindernis mehr. Schon 2017 hat Google selbst eine Technik vorgestellt, mit der Wasserzeichen aus Bildern entfernt werden können.
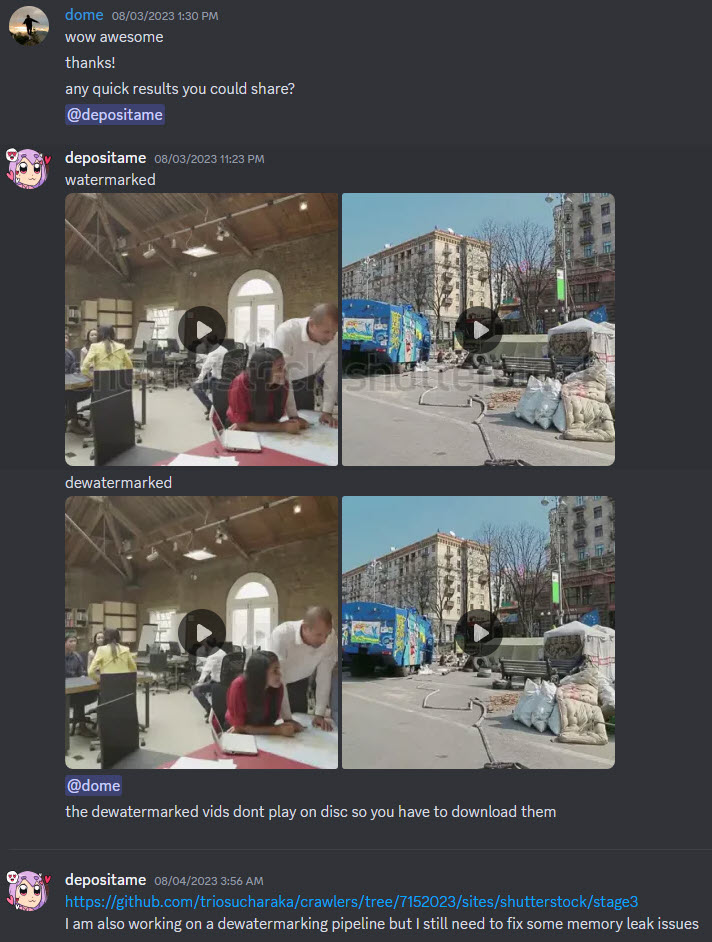
Auch der LAION-Verein bietet auf GitHub ein kostenloses Tool für die „Wasserzeichen-Erkennung“ an. Von der Erkennung zur Entfernung ist es für geübte Programmierer dann nur noch ein kleiner Schritt, über den aus rechtlichen Gründen nicht so gerne öffentlich geredet wird. Manchmal aber doch:
Aus dem #video-generation Kanal des Discord-Servers von LAION
Aus dem #video-generation Kanal des Discord-Servers von LAION
Bei LAION wird zwar an einem eigenen Text2Video-Generator namens phenaki gearbeitet, die technischen Details des Trainings sind denen von Sora aber sehr ähnlich, soweit ich das beurteilen kann.
Die Wahrscheinlichkeit, dass OpenAI daher mit der gleichen Rücksichtslosigkeit wie LAION gegenüber Urhebern beim KI-Training vorgeht, halte ich für hoch, zumal die bisherigen Aussagen und Handlungen von OpenAI leider nicht geeignet sind, Zweifel zu zerstreuen.
Beim ganzen Hype vom SORA und dem Staunen über die tollen Ergebnisse sollte nicht vergessen werden zu fragen, welche (Video-)Künstler beim Training beteiligt waren.
Meine Klage gegen den deutschen Verein LAION e.V., welcher unter anderem Trainingsdatensätze für KI-Anwendungen bereitstellt, hat weltweit für viel Aufmerksamkeit gesorgt.
Da es auch regelmäßig viele Anfragen zum aktuellen Stand des Verfahren gibt, hier ein kurzes Update.
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt.
Der Verein LAION e.V. sieht das naturgemäß anders, wie in den beiden zitierten Blogartikeln gut erkennbar ist. Daher blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
25.04.2024 um 13:00 Uhr: Gerichtstermin vor dem Landgericht Hamburg (Update 12.4.2024: Die Uhrzeit wurde geändert)
Das Landgericht Hamburg hat also in ca. einem halben Jahr den Gerichtstermin angesetzt, in dem dann mündlich weiter über die Klage verhandelt werden wird. Das Verfahren ist öffentlich. Hier die aktuelle Zusammenfassung des Falls durch die mich vertretende Kanzlei SLD.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Am Rande meiner Auftritte auf der diesjährigen Fotomesse Photopia habe ich die Chance genutzt, mich näher über den größten Fotografie-Berufsverband in Deutschland zu informieren: FREELENS.
Vertreten wurde der Verband im Interview durch die Geschäftsführerin Heike Ollertz, den Vorstandsvorsitzenden Marco Urban sowie Julia Laatsch aus dem Beirat und als FREELENS-Sprecherin im Deutschen Fotorat.
Fast eine Stunde lang sprachen wir zusammen über die Entstehung, die Aufgaben und Zielsetzung von FREELENS. Außerdem widmeten wir uns Themen wie der Nachwuchsförderung, der „Initative Urheberrecht“, Plattformlizenzen, Presseausweisen und das heiße Eisen Künstliche Intelligenz durfte natürlich auch nicht fehlen.
Das Gespräch fand in der Presse-Lounge der Messe Hamburg statt, wo im Hintergrund leider ab und zu Mittagsgeschirr abgeräumt wurde. Als Bonus haben wir im Hintergrund auch das Geburtstagsständchen für einen Journalismus-Kollegen versteckt, wer aufmerksam zuhört, wird es bestimmt entdecken in der heutigen Folge vom „Podcast eines Fotoproduzenten“:
PORTFOLIO: Statt eines Portfolios gibt es hier einen Auszug aus der Kampagne „#wirallesindfreelens“: