Letzten Monat hatte ich in diesem Artikel erklärt, wie die Künstliche Intelligenz am Beispiel von Stable Diffusion funktioniert.
Darin kam der Verein LAION e.V. zur Sprache, welcher etliche riesige Datenpakete anbietet, mit welchen KIs trainiert werden. Eines dieser Pakete heißt z.B. LAION 5B, weil es ca. 5,85 Millarden („5,85 Billions“ im Englischen, daher 5B) Datensätze umfasst.
Ein Datensatz besteht zum Beispiel aus der URL zu einer Bilddatei, der dazugehörigen Bildbeschreibung, den Bildmaßen in Pixeln, der verwendeten Sprache sowie einiger anderer Faktoren.
Anfangs war wenigen Leuten bekannt, welche Bilder genau im Datenset enthalten waren. Aber die Künstler Mat Dryhurst, Holly Herndon und Jordan Meyer gründeten die Firma Spawning, welche wiederum die Webseite „Have I Been Trained?“ ins Leben riefen.
Dort können Leute – vereinfacht erklärt – die oben genannten Bildbeschreibungen durchsuchen, um zu sehen, welche Bilder in den KI-Trainingssets enthalten sind.
Viele Urheber nutzten die Webseite und fanden wenig überraschend viele Treffer. Auch aus meinem Portfolio konnte ich nach einer kurzen Stichprobe haufenweise Bilder finden, hauptsächlich mit Wasserzeichen aus den Bildagentur-Portfolios, aber auch von Kundenseiten oder Webseiten, die selbst illegal Bildersammlungen anbieten:
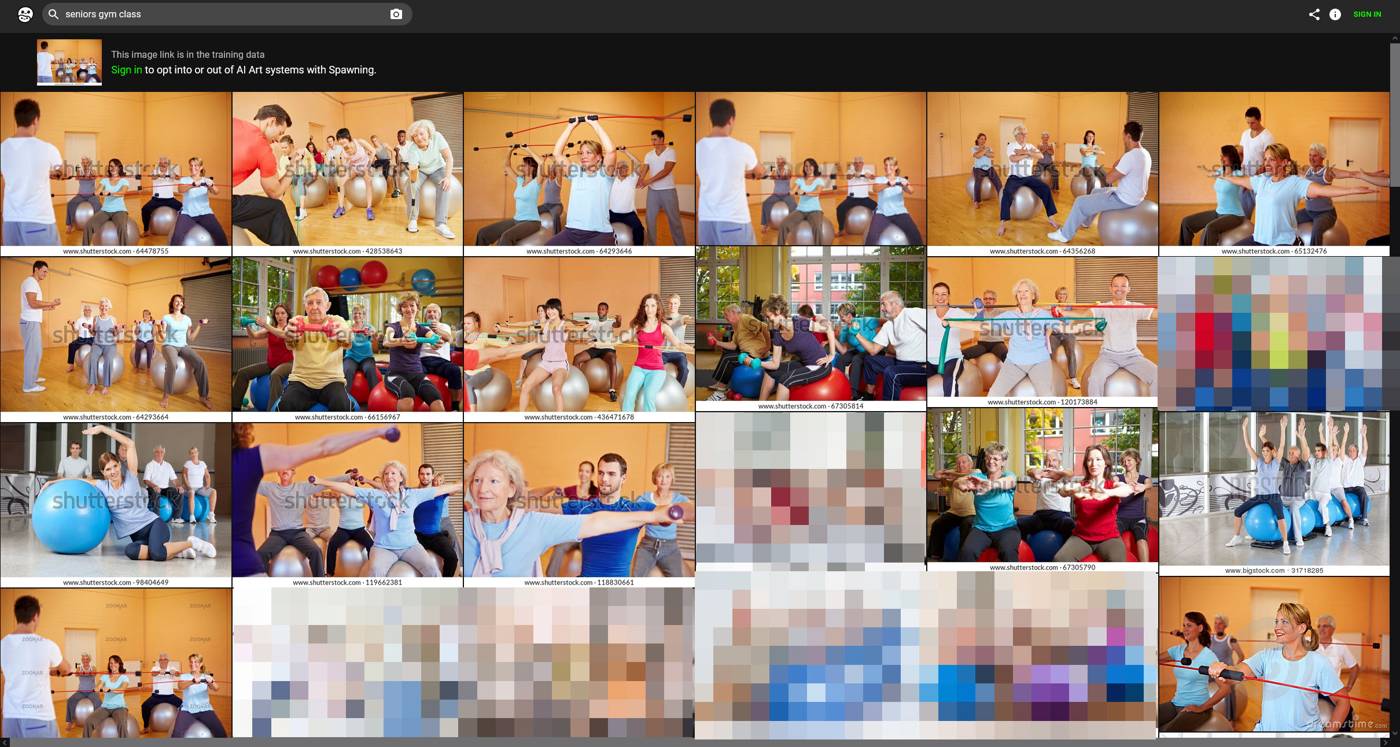
In den Kommentaren eines meiner Social Media-Profile las ich den Hinweis eines Fotografen, dass der den Verein LAION gebeten hatte, seine Werke aus den Trainingsdaten zu nehmen und als Antwort mit Schadensersatzansprüchen bedroht wurde, sollte er auf seinem Anliegen beharren.
Das kam mir wie eine wilde Geschichte vor, bis ich die Fakten überprüfte. Ich nahm Einsicht in den Schriftsatz der Anwaltskanzlei und schickte am 13.02.2023 selbst eine Anfrage an LAION e.V. per Email mit der Bitte, meine Werke aus dem Trainingssatz zu entfernen.
Nur einen Tag später erhielt ich am 14.02.2023 tatsächlich Post („vorab per Email“) von der Hannover Anwaltskanzlei „Heidrich Rechtsanwälte“ im Auftrag von LAION e.V., übrigens fast wortgleich mit dem Schreiben, welches ich von dem anderen Fotografen weitergeleitet bekommen habe.
In dem Schreiben heißt es:
„Sehr geehrter Herr Kneschke,
hiermit zeigen wir an, dass wir die rechtlichen Interessen des LAION e.V., Herman-Lange-Weg 6, 21035 Hamburg, vertreten. Die ordnungsgemäße Bevollmächtigung wird anwaltlich versichert.
Grund unseres Schreibens ist Ihre E‑Mail vom 13. Februar 2023 an unsere Mandantin, welche uns diese zur Beantwortung vorgelegt hat.
- Bei unserer Mandantin handelt es sich um einen im Vereinsregister eingetragenen, nicht-gewinnorientierten Verein, der es sich zur Aufgabe gemacht hat, selbstlernende Algorithmen im Sinne künstlicher Intelligenz fortzuentwickeln und der breiten Öffentlichkeit zur Verfügung zu stellen. Die Vereinsmitglieder sowie der Vorstand sind im Rahmen der Vereinsarbeit ehrenamtlich forschend tätig.
Unsere Mandantin hat bereits im Sommer 2022 umfangreich Rechtsrat zu verschiedenen Problemstellungen – insbesondere urheberrechtlichen Implikationen – im Zusammenhang mit ihrer Tätigkeit auf dem Gebiet der Erforschung von Kl-gestützten Bildgenerierungsmodellen eingeholt. Unserer Mandantin war es von Anfang an wichtig, dass im Rahmen ihrer Tätigkeit keine Rechte Dritter verletzt werden. Unsere Mandantin hält sich ausnahmslos an die bestehenden gesetzlichen Vorgaben, insbesondere aus dem Urheber- und Datenschutzrecht.- Unsere Mandantin unterhält lediglich eine Datenbank, die Links zu im Internet öffentlich abrufbaren Bilddateien enthält. Sie kann zwar nicht ausschließen, dass in der Datenbank auch Links zu Bildern enthalten sind, deren Urheber Sie sind. Da unsere Mandantin aber jedenfalls keine der von Ihnen monierten Fotografien speichert, besteht Ihrerseits auch kein Anspruch auf Löschung. Es existieren bei unserer Mandantin schlicht keine Bilder, die gelöscht werden könnten.
Das Bereitstellen von Links stellt nach der höchstrichterlichen Rechtsprechung auch keine Verletzung von Urheberrechten dar. Das Bereitstellen eines Links dient lediglich dem Auffinden eines ohnehin im Internet abrufbaren Inhalts. Der hinter einem Link stehende Inhalt kann auch nur an der verlinkten Stelle und nicht andernorts abgerufen werden, sodass insbesondere keine Vervielfältigung im Sinne des Urheberrechts vorliegt. Unsere Mandantin trägt keine Verantwortung für die Inhalte auf anderen Websites.- Auf Nutzungen Ihrer Werke durch Dritte hat unsere Mandantin naturgemäß keinen Einfluss. Eine Nutzung durch Dritte wird aber ohnehin auch nicht erst durch unsere Mandantin ermöglicht. Die von unserer Mandantin verlinkten Bildinhalte sind frei im Internet abrufbar. Sofern Sie eine rechtsverletzende Nutzung durch Dritte feststellen, müssen Sie sich an diese Personen wenden.
- Ihre Fristsetzung betrachten wir daher als gegenstandslos. Wir weisen außerdem darauf hin, dass unsere Mandantin gemäߧ 97a Abs. 4 UrhG Schadenersatzansprüche geltend machen kann, wenn diese unberechtigt urheberechtlich in Anspruch genommen wird.
Wir hoffen, dass wir Ihre Bedenken mit unseren Ausführungen ausräumen konnten und stehen Ihnen für Rückfragen gern zur Verfügung.“
Ja, ihr lest das vollkommen richtig. Urhebern, die nicht wollen, dass ihr Werke für Trainingszwecke benutzt werden, werden Schadensersatzansprüche angedroht.
Die restlichen Aussagen im Schreiben lassen einen ebenfalls etwas verwundert zurück. Die angebliche Gemeinnützigkeit eines Vereins, welcher unter anderem von einer Firma wie Stability AI mitfinanziert wird, welche wiederum von den Ergebnissen des Vereins kommerziell profitiert, hat mindestens ein „Geschmäckle“, was meiner Meinung nach danach riecht, hier absichtlich eine Konstruktion zu bauen, welche Haftungsfragen auslagern soll.
Auch das „ledigliche Unterhalten einer Datenbank“ ist hier meiner Meinung nach etwas zu kurz gegriffen, da neben den oben genannten Datenpunkten auch Daten wie „similarity“, „pwatermark“ oder „punsafe“ enthalten, welche nicht einfach ausgelesen, sondern erstellt werden müssen, was vermutlich zumindest eine temporare Speicherung der Bilddaten erfordert haben wird. Das legt auch diese Infografik nahe, in der erklärt wird, das die Bilder und Daten „heruntergeladen“ wurden:
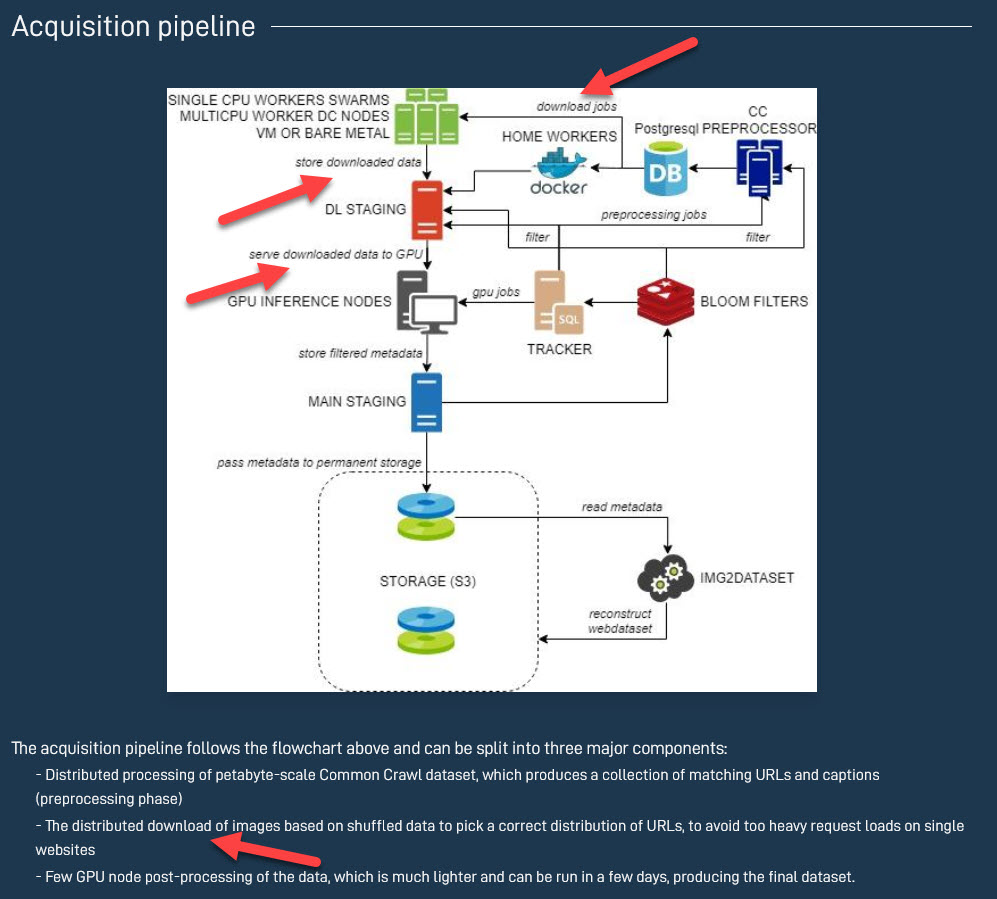
Das sind im Detail aber auch Vermutungen, welche wahrscheinlich bei einem Gerichtsprozess geklärt werden müssen.
Genau so einen Prozess werde ich nun anstreben, um die Frage richterlich klären zu lassen, ob das Vorgehen tatsächlich rechtlich so einwandfrei ist, wie die Anwaltskanzlei behauptet.
Falls ihr als Urheber ebenfalls einige eurer Werke im Datensatz von LAION findet und vielleicht auch Post von obiger Anwaltskanzlei erhalten wollt, findet ihr die Emailadresse für eure Anfrage zur Datenlöschung hier im Impressum von LAION e.V..

Hallo Robert,
ist ja spannend was du da ausgegraben hast – aber willst du deine Energie (die ich im Einzelfall echt bewundere, bei Imagebroker etc.) als Einzelkämpfer da wirklich einsetzen ?
Denke das ist ne grössere Nummer die man besser ausgestatteten Verbänden wie der VG Bild überlassen kann.
LG, Andreas
@Andreas: Ich sehe aktuell leider nicht, dass unsere Branchenverbände da allzu motiviert sind, etwas zu unternehmen.
Sollte sich das ändern, bin ich gerne bereit, mit denen zusammenzuarbeiten oder denen ganz die Arbeit zu überlassen.
Bislang scheinen sich die Verbände noch nicht sehr für diese Entwicklung zu interessieren. Ich habe einige angeschrieben und bislang von KEINEM eine Antwort erhalten.
Was mich jetzt schon etwas wundert, greift diese Entwicklung nicht nur in den Bereich der Werbefotografie ein.
Ebenfalls habe ich auch bis heute keine Rückmeldung von den (staatlichen!) Forschungsinstituten erhalten, die entweder an der Schaffung von Laion-5b samt Software beteiligt sind oder waren bzw. entsprechende Fachpublikationen zum Urheberrecht in der Wissenschaft veröffentlicht haben.
Der §60d, der ohnehin schon das Urheberrecht sehr zu Gunsten der Wissenschaft verschiebt, wird hier zum Schaden aller Gestalter gedehnt.
Hier auch ein inetressanter Artikel wie man Kunstwerke schützen kann.
Der hier genannte Datensatz wird auch dort erwähnt.
https://www.slashcam.de/news/single/Kuenstler-vs-KIs–Neues-Tool-macht-Kunstwerke-fuer-K-17741.html
@Christian: Das Problem bei diesen Lösungen ist ähnlich wie bei Opt-Out-Möglichkeiten: Hier wird die Verantwortung auf die Seite der Urheber gelegt, nach dem Motto: „Wenn der Urheber seine Werke nicht in einem zusätzlichen Arbeitsschritt mit einem Tool schützt, kann die KI das einfach zum Trainieren nutzen…“
Sowas höre ich ständig, wenn Leute meine Bilder klauen: „Da stand ja kein Name dran, deshalb bin ich davon ausgegangen, dass ich das kostenlos nutzen dürfe“…
robert, danke für deine arbeit. diese ist einfach wichtig. habe mich auch schon gefragt ob lion sauber arbeitet, bzw. was dort betrieben wird in deutschland überhaupt zulässig ist. sollte man ggf. auch an die jeweiligen bundestagsabgeordneten zukommen lassen, mit der bitte um stellungnahme.
wie siehts mit adobe aus? sind doch verdammt viele fotos von dennen drin? wollen die nichts unternehmen?? (viele hundert bilder von mir sind dort drin – hätte die dort lieber gestern als heute entfernt.)
Das ist ja ganz nett von den Wissenschaftlern sich hier Arbeit zu machen .. aber:
a) ist das Kind bereits schon im Brunnen
b) ist es einigermaßen unverfroren, wenn man sich gegen die Aneignung der eigenen Arbeitsleistung nur wehren kann, in dem man einen durchaus hohen Aufwand betreibt.
Es gibt ja durchaus Leute, die müssen mehr als ein Werk pro Monat erstellen …
c) derjenige, der sich schlicht und ergreifend in den Niederungen der bildlichen Darstellung bewegt, der hat da mal gar nichts von.
Es ist viel zu kurz betrachtet, die Leistung nur im Kunstmarkt anzusiedeln. Die wesentliche Markt liegt nicht darin daß jetzt jeder sich einen van Gogh Sonnenaufgang auf die Kaffeetasse kleben kann, der Markt liegt in der gesamten professionellen Fotografie – von Presse über Hochzeit bis zur Werbung – und der ist lukrativ.
Hallo Henrik – Adobe hat 2 Geschäftsfelder – die Creative Cloud und den Stock. KI greift zweifellos beide Geschäftsfelder an – will Adobe nicht den Weg von Kodak gehen, werden Sie sich selber dahin entwickeln müssen.
Das käme aber bei den Kunden der Cloud ziemlich sicher nicht gut an und wäre ein katastrophaler Vertrauensverlust wenn sich dann heraus stellen würde: das geht so nicht mit dem Data Mining.
Also warten sie mal und lehnen sich nicht aus dem Fenster.
Aber logge Dich mal in Deinem CC-Account ein – unter „Konto und Sicherheit / Datenschutz“ gab es bei irgendeinem Update eine Erweiterung:
„Adobe erlauben, meine Inhalte zum Zweck der Produktverbesserung und ‑entwicklung zu analysieren“.
Der ist standartmäßig auf „ja, suppi gerne“ gestellt gewesen… .
Ich bin mir nicht sicher ob dies zielführend ist. Am Ende des Tages wird man diese Entwicklung nicht aufhalten können und werden. Ich mag den Spruch, dass AI keine Jobs wegnehmen wird, sondern lediglich die Beschäftigung von denen, die keine AI benutzen, zu denen verschiebt, die es tun.
Dies ist das übliche Aufbäumen einer lukrativen Industrie, die potentiell durch Technologie reformiert bzw. revolutioniert wird. Die Gewinner sind – wie immer – die Resilienten mit der Fähigkeit zur Adaption.
Aus dem Stockfoto-Fotografen wird also perspektivisch der Algorithmen-Designer. Oder Input-Creator, der die bestmöglichen Prompts in die besten Algorithmen hackt.
Ich mag dein Blog und lese es schon viele Jahre. Heute bin ich das erste Mal so gar nicht deiner Meinung.
@M.B.: Das sind ja zwei verschiedene Themen. Ich stimme mir Dir überein, dass die KI-Entwicklung vermutlich nicht aufgehalten werden kann.
Das soll auch gar nicht das Ziel sein. Ich denke jedoch, dass es relevant ist, dass die Herkunft und Entwicklung der Trainingsdaten transparent und nachvollziehbar dargelegt werden kann, was aktuell leider nicht ganz der Fall zu sein scheint.
Allein die ganze Konstruktion mit dem Geflecht aus „gemeinnützigem“ Verein, staatlichen Forschungseinrichtungen sowie kommerziell agierenden Firmen riecht verdächtig nach dem Versuch, hier Urheberrechtsgesetze zu umschiffen.
Richtig Robert, das sehe ich ebenso. Ich kann ja auch nicht als Uber Fahrer durchstarten und dafür das Auto meines Nachbarn nehmen – nur weil es eben gerade so arg ungenutzt rumsteht.
Da ich noch aus der analogen Zeit stamme, schätze ich auch den Bedarf an „Prompt-Tipper“ eher gering ein (zu analogen Zeiten gab es relativ wenige Unternehmen, die ihren Bedarf an Fotografie selber gedeckt haben. Schlicht weil man auf seinen Ausschuss mindestens 2 Tage warten musste 😉 – also die Lernkurve war eher flach … )
Das hat sich mit der digitalen Fotografie spürbar geändert.
Von daher wird sich das Marketing (oder der private Auftraggeber) zukünftig bei Shutterstock einloggen, und entweder per Tipparbeit das Gewünschte erstellen oder es sich aus einer Auswahl an Referenzbildern „mixen“ lassen.
Das geht schon heute. So wurden die KI´s anfänglich trainiert und übrigens geschieht das heute noch so.
Und last not least, wieviel wird einem Kunden Deine „Prompt-Experience“ pro Stunde wert sein?
Hallo an die Runde,
und einen herzlichen Dank an Dich, Robert, für Deine Initiative.
Kurz zu den Verbänden, die das Thema KI angeblich nicht interessieren würde. Wir (die AGD) haben am 23.03.23 in Heidelberg eine ganztägige Veranstaltung zum Thema KI im Design. (https://agd.de/designer/szene/ki-design-vortraege). Im Verbund des Kulturrats wird an einer Positionierung gearbeitet, was mir persönlich etwas zu früh ist, wenn im (gefühlten) Wochenrhythmus neue Tools auf den Markt kommen und noch nicht klar ist, wer Freund und wer Feind ist. Zudem können wir es uns nicht erlauben, von den vielen Teilaspekten einfach nur ein Thema herauszupicken und alles andere links liegen lassen.
Ich muss aber gestehen, dass Danger-Robert sich mal wieder den interessantesten Bereich vorgenommen hat : Darf ein KI-Unternehmen sich bei anderen UrheberInnen bedienen? In Deutschland wird es wohl um die Anwendung des Text- und Dataminings gehen (§ 44b UrhG) und wahrscheinlich wird man die Framing-Rechtsprechung des EuGH heranziehen. Bei letzterer ist entscheidend ob man auf der eigenen Website das Framing unterbunden hat. Mich würde interssieren, ob man den Datenzugriff durch LAION unterbinden kann (zB. im HTML-Code der Website)?
So, das mal aus der Hüfte geschossen.
Hallo Alexander,
als AGD seid Ihr da ganz vorne dran 😉
Was die Framing-Rechtssprechung angeht:
Das Wesen des Internets bringt es mit sich, daß Bilder und Filme, die ein Kunde beauftragt und bezahlt hat, gerne kopiert werden. Mal steht der Kopierende in einem Geschäftsverhältnis mit dem Auftraggeber, mal wird schlicht geklaut. Mal gibt es ein robots.txt, oft gibt es den nicht.
Bei Laion-5b und seine Varianten sieht das nochmals anders aus. Mit wissenschaftlichem Recht (§60d) wurde gemint und dann an einen Verein übergeben, der keinerlei Kontrolle über den Kreis der Nutzer hat. Ob Forscher oder Konzern, ob Sozialdemokrat oder Faschist, jeder darf ran.
Fakt.
Grundsätzlich kann man aus §44b Abs.2 und Abs.3 folgern:
Während das Sammeln von Bienenschwärmen den Nachweis der „Herrenlosigkeit“ bedarf, ist es bei geistigem Eigentum nicht so. Und da muß man mal ganz viele Fragezeichen dahintersetzen. Demokratie und Gleichheit gehen anders.
Ich habe es Robert schon geschrieben, ich bin ein „alter Sack“, mich wird diese Entwicklung sehr wahrscheinlich nur hinsichtlich der Unternehmensübergabe treffen (was offen gestanden aber auch echt reicht).
Wir müssen uns definitiv bewußt sein, am Ende bleibt vielleicht eine Handvoll „Designer“ und „Handwerker“ übrig. Welche Wertschätzung Ihre Arbeit dann aber haben wird, darüber möchte ich nicht spekulieren. Aber optimistisch bin ich da nicht. Ich denke, da werden die Zahlen der KSK dann schon eher stimmen als heute.
Gruß Christian
Zur Deiner Frage noch:
Theoretisch kann man den Zugriff auf die Webseite durch einen entsprechende *.txt Datei unterbinden und hoffen daß der Crawler das ignoriert. Gibst Du Daten an einen Kunden weiter, hast Du viiiiielleicht noch Einfluß darauf daß er das tut, hier wird aber die Nachprüfbarkeit schon schwieriger. Gibt der Kunde jetzt Bilder an einen eigenen Kunden weiter … Ende Gelände. Du kennst ja nicht mal den Kunden.
Wenn Du Interesse hast: Geh mal auf „haveibeentrained.com“. Gib im Suchfeld „ROAMER watch“ ein. Alles was da kommt, stammt aus meinem Studio (ausser was auf dem Schreibtsich geknipst wurde). Das ist aber beileibe nicht alles, lade ich ein solches Bild zum Abgleich hoch, dann kommt noch sehr sehr viel mehr.
Wenn Du jetzt die Bilder anklickst, siehst Du woher sie kommen – das ist weder die Webseite von mir, noch die Webseite des Schweizer Auftraggebers.
Gruß Christian
es ist nicht so schwer zu recherchieren wie der LAION datensatz zustande kommt. vor allem besteht er aus dumps die von common crawl bereitgestellt werden.
da es sich um einen url harvester handelt werden keine metadaten zu den autorinnen abgespeichert. man muss sich also die muehe machen, die daten entsprechend auszuwerten und autoren und orginal-fotos zuordnen zu koennen, was die genannten kuenstler gemacht hatten.
die exif-tags und filenamen werden nicht in den trainingsdaten verwendet, also wirds schwierig in den „rohdaten“ nach namen zu suchen. sieht danach aus dass bei einem mindestmass an sachverstaendigenwissen vorausgesetzt, das urteil vorgezeichnet ist.