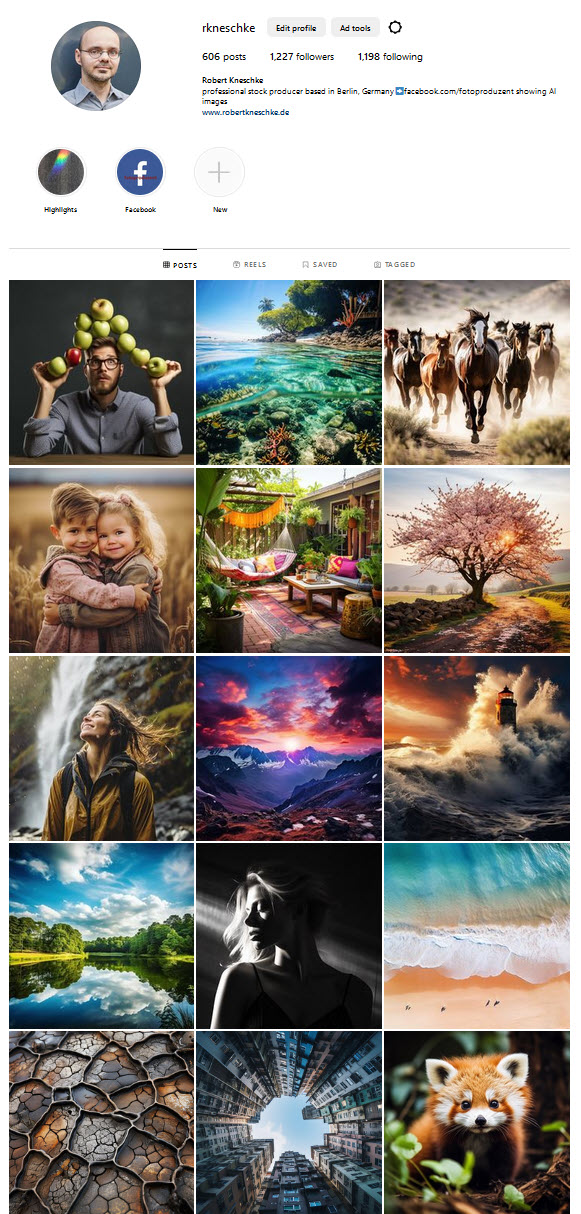
Mein Instagram-Account@rkneschke besteht seit über zehn Jahren, aber bisher habe ich ihn eher stiefmütterlich behandelt.
Zu sehen gab es dort auch fast nie Auszüge meiner professionellen Arbeit, sondern eher Bilder, die privat enstanden sind, ein Sammelsurium aus abstraktem Minimalismus, Food, Landschaften, Konzertfotos und Drohnenaufnahmen (bis ich diese geschrottet habe).
Aktueller Screenshot von meinem Instagram-Account
Seit ich mich vor einem Jahr stark auf die Bilderstellung mittels generativer KI fokussiert habe, stand die Frage im Raum, ob diese beeindruckenden KI-Bilder sich eignen würden, um damit – mehr oder weniger automatisiert – Social-Media-Accounts zu betreiben.
Da mein Instagram-Kanal sowieso nur sporadisch gefüllt wurde von mir, habe ich vor drei Monaten ein Experiment gestartet.
Der Aufbau vom Instagram-KI-Experiment
Ich habe meinen Instagram-Kanal seit dem 16.4.2023 ausschließlich mit komplett KI-generierten Inhalten gefüllt. Das Ganze sollte möglichst zeitsparend vonstatten gehen, mein Ablauf war daher:
Die Text-KI ChatGPT nach einem Haufen trendiger Instagram-Motive fragen.
Diese Motive automatisiert per Bild-KI Midjourney in Bilder umwandeln lassen.
Die schönsten Bilder raussuchen und unbearbeitet zu Instagram hochladen.
Die Bildbeschreibung und Hashtags automatisiert durch ChatGPT generieren lassen basierend auf der Bildbeschreibung, die in Schritt 1 generiert wurde.
Optional: Um noch mehr Zeit zu sparen, ab und zu einige Instagram-Beiträge im Voraus mit der Instagram-App planen.
Alle KI-Bilder wurden in den Hashtags und der Bildbeschreibung als solche ausgewiesen.
Das Ziel vom Experiment
Ich wollte mit dem Experiment testen, was mit meinem Instagram-Account passiert, wenn ich diesen komplett auf KI-basierte Bilder umstelle.
Werde ich Follower gewinnen oder verlieren?
Wird sich meine Reichweite erhöhen oder verringern?
Spare ich Zeit mit dieser Art der Content-Erstellung?
Wie reagieren meine bisherigen Follower?
Die Ergebnisse in Zahlen
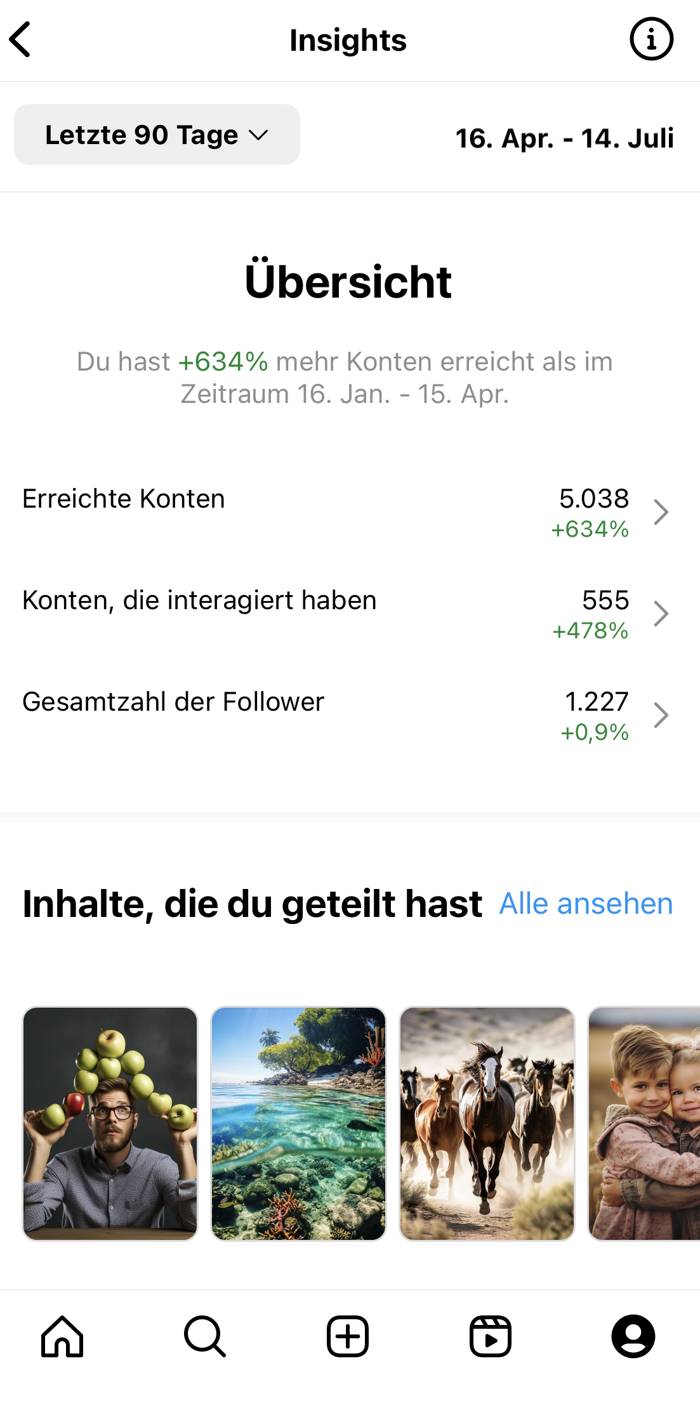
Das Wichtigste zuerst. Wie ihr an der Übersicht in den Instagram-Insights sehen könnt, liegen alle Messwerte im grünen Bereich.
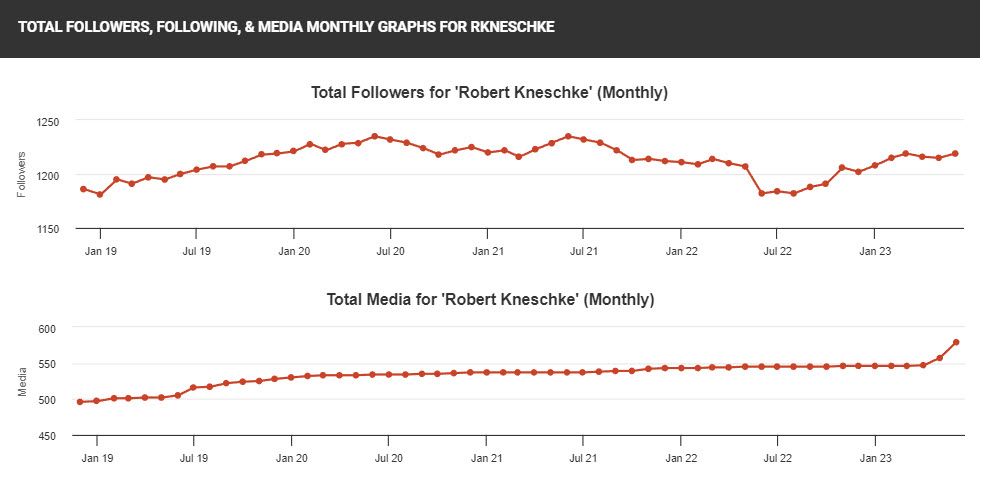
Begonnen habe ich das Experiment Mitte April 2023 mit 1216 Followern, aktuell liege ich bei 1227, das entspricht einem Plus von 0,9%. Nicht viel, aber immerhin kein Verlust.
Ich konnte 634% mehr Konten erreichen und 478% mehr Konten haben mit meinem Kanal interagiert. Dazu muss ich jedoch fairerweise sagen, dass ich im Vergleichszeitraum der drei Monate vorher (also Januar bis April 2023) nur ein Bild gepostet hatte, diese Werte also viel höher als normal ausfallen.
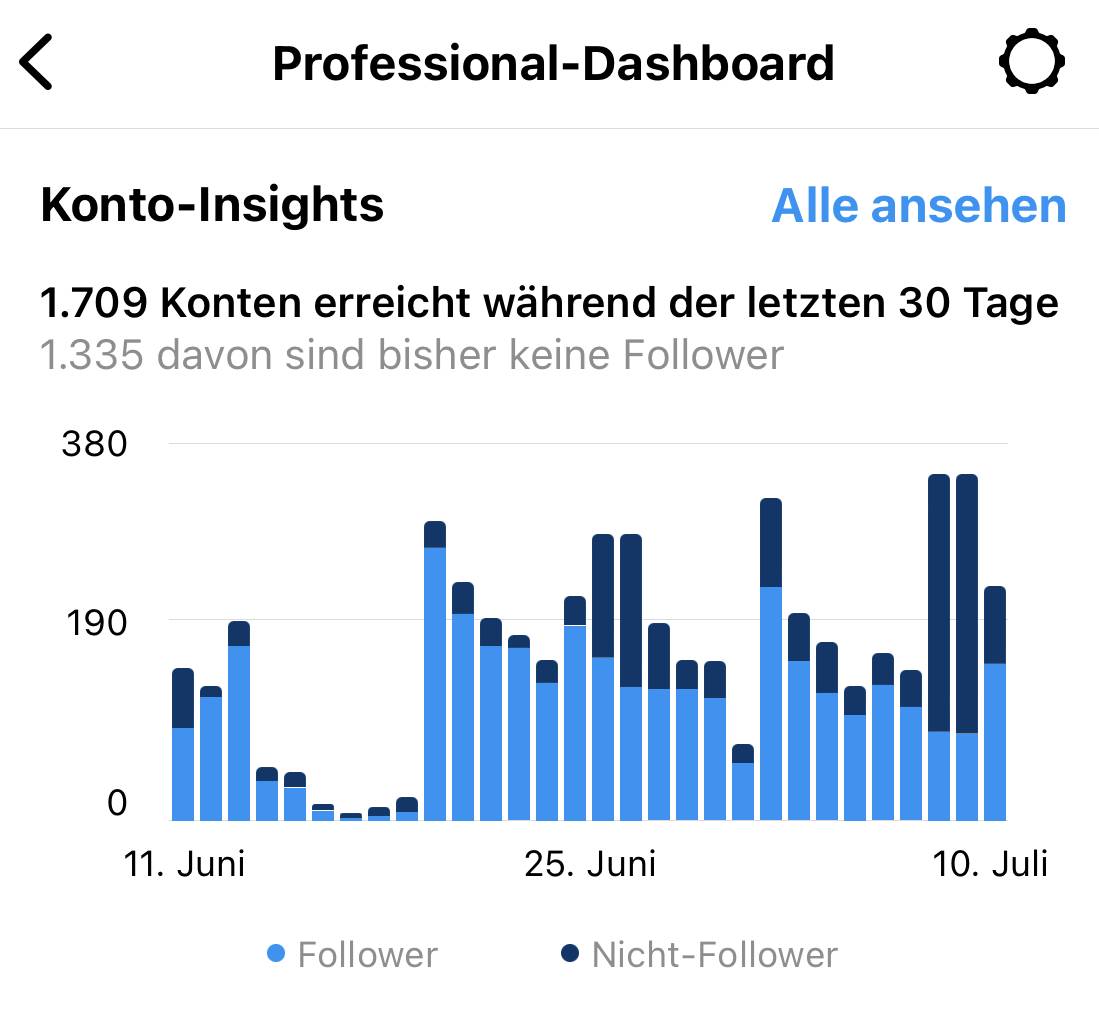
Wie ihr am obigen Diagramm sehen könnt, ist auch die Zahl der Nicht-Follower relativ hoch, auf jeden Fall deutlich höher als vor dem Experiment. Das liegt vermutlich daran, dass ich durch die vielen neuen verschiedenen Motive auch ganz unterschiedliche Hashtags anbringen konnte, die außerhalb meiner „Instagram-Follower-Bubble“ lagen.
Was jedoch auf jeden Fall stark gefallen ist, ist die Zeit, die ich zur Erstellung eines Posts benötigte. In den 10 Jahren zuvor, habe ich ca. 55 Bilder pro Jahr hochgeladen, also gut ein Bild pro Woche. Im Experimentzeitraum habe ich allein fast 60 Bilder hochgeladen, also ca. 5 pro Woche.
Die Kommentare zu den Bildern waren gemischt. Einige positiv, einige kritisch, aber insgesamt alles im Rahmen. Ich vermute, dass die radikalen KI-Gegner schnell ihr Abo gekündigt haben, dafür jedoch einige neue Fans dazu gekommen sind.
Wer an der genaueren Entwicklung des Kanals interessiert ist, kann sich die Statistiken hier bei Social Blade anschauen:
Persönliche Anmerkungen und Fazit
Ich hatte ehrlich gesagt schlimmere Ergebnisse befürchtet und dachte, dass vielleicht viele meiner Fans, die eher aus dem Fotografie-Lager kommen, angesichts dieser KI-Bilder-Flut frustriert sind und davonlaufen.
Das hat sich zum Glück nicht bewahrheitet und die leichten Verluste konnten durch neue KI-Fans mehr als ausgeglichen werden.
Insgesamt ist das Experiment natürlich wissenschaftlich gesehen kaum haltbar, da zum Beispiel der Vergleichszeitraum vorher nicht repräsentativ ist. Da hatte ich fast nichts gepostet, weshalb die Engagement-Rate logischerweise auf einem sehr niedrigen Level lag.
Auch die Bildauswahl ist eher zufällig. Ich habe viele atemberaubende Naturbilder, einige Menschenbilder und niedliche Tiermotive gepostet. Alles quer durch den Gemüsegarten. Vermutlich ist das für den Aufbau einer speziellen Zielgruppe eher unpassend, aber da ich auch vorher eher motivisch gesehen Querbeet unterwegs war, passt das hier.
Interessant fand ich die Möglichkeit, mittels neuer Motive und die entsprechenden Hashtags ganz andere Zielgruppen ansprechen zu können, welche mir bisher noch nicht folgen.
Das ist sicher für Accounts, welche professionelle Ziele verfolgen und ihre Reichweite erhöhen wollen, ein sehr spannender Aspekt.
Beeindruckend war und ist aber auch das Zusammenspiel von ChatGPT und Midjourney, welches die Zeit für die Content-Erstellung stark reduziert hat, was natürlich die Motivation erhöht, überhaupt mehr zu posten.
Wie geht es weiter?
Ich werde auf meinem Instagram-Kanal weiter KI-Inhalte posten. Ob ich inhaltlich mich mehr auf bestimmte Motive konzentriere oder einfach die Bilder zeige, die mir gefallen, muss ich noch entscheiden. Wer es direkt wissen will, folgt bitte am besten einfach meinem Instagram-Account @rkneschke hier.
In der Zwischenzeit habe ich heute für mein Seitenprojekt „www.eis-machen.de“ ebenfalls einen Instagram-Account gestartet. Unter @eiscremeparty werde ich nur KI-Bilder zum Thema Eiscreme posten. Wer daran Interesse hat, kann dem Kanal ebenfalls gerne folgen.
Seit über einem Jahr wird gefühlt in unserer Branche kaum noch über etwas anderes als über Künstliche Intelligenz (KI) geredet. Da passt es bestens, dass auch die neuste Podcast-Folge nach so langer Funkstille sich direkt diesem heißen Thema widmet.
Zu Gast habe ich diesmal Claudia Bußjaeger, welche die – vielleicht sogar erste – Repräsentanz für KI-Künstler namens yesweprompt ins Leben gerufen hat.
Was das genau ist, was sie vorher gemacht hat und über vieles mehr reden wir in der heutigen Folge vom „Podcast eines Fotoproduzenten“:
Nur gut zwei Wochen nach der Bekanntgabe von Adobe, dass Adobe Stock nun durch Künstliche Intelligenz erzeugte Bilder akzeptiere, hat auch die Bildagentur Panthermedia bekannt gegeben, dass sie nun KI-Material annehmen.
Der Newsletter von Panthermedia im Wortlaut
Die Voraussetzungen lesen sich im Grunde fast identisch wie die von Adobe Stock, mit der Ausnahme, dass die Bilder im Titel statt des Hinweises „Generative AI“ nun „AI generated image“ enthalten sollen.
Da drängt sich etwas der Verdacht auf, dass hier einfach die Entscheidung von Adobe Stock nachgeahmt wurde, was ich aber inhaltlich begrüßenswert finde.
Unter dem Reiter „KI-Bilder“ finden sich auf der Startseite von Panthermedia jedoch bisher nur knapp 2.500 künstlich erzeugte Portraits, welche vor ungefähr einem Jahr vorgestellt wurden. Das kann sich natürlich bald ändern.
Das Jahr 2022 war der Durchbruch der Bilderstellung durch Künstliche Intelligenz (KI), weil Projekte wie Dall‑E, Stable Diffusion oder Midjourney der breiten Öffentlichkeit zugänglich wurden.
Auch ich habe hier im Blog schon einige Beiträge über KI-Bilder geschrieben, aber bisher noch nicht von Grund auf erklärt, wie die KI-Bildgenerierung funktioniert.
Das Thema „Artificial Intelligence“ interpretiert von der KI-Engine Stable Diffusion
Das ist aber essential für das Verständnis der aktuellen Debatten um Urheberrechte, Bilderdiebstahl und die ethischen Auswirkungen der neuen Technik.
Daher hier ein kurzer Exkurs in die Geschichte der KI-Bilderstellung.
Bild-zu-Text-Erkennung
Um 2015 herum lernten maschinell trainierte Algorithmen, Objekte in vorhandenen Bildern zu benennen. Das kennen Fotografen sicher von Lightroom, Google Images oder Facebook, wo die Software oder Webseite automatisch erkennt, welche Dinge grob auf einem Bild sichtbar sind. Zusätzlich lernten die Algorithmen schnell, die beschriebenen Objekte in einen lesbaren Satz umzuwandeln. Aus „Frau, Handy, lachen“ wurde also „Eine lachende Frau am Handy“.
Text-zu-Bild-Erkennung
Findige Forscher dachten nun, dass dieser Prozess auch umkehrbar sein müsste. Sie kombinierten hier – sehr vereinfacht gesprochen – die obige Technologie mit einem Entrauschungsverfahren, welches wiederum mit obiger Technologie auf Genauigkeit getestet wurde.
Im Grunde trainierten sich zwei verschiedene KIs gegenseitig. Die erste KI nahm zufällig erzeugtes Bildrauschen und versuchte, aus der Texteingabe ein Bild zu erzeugen. Die zweite KI versuchte, aus dem erzeugten Bild zu erraten, was darauf erkennbar ist. Wenn die zweite KI der ersten bestätigte, dass sie „die lachende Frau am Handy“ erkannt hat, speicherte sich die erste KI einen Pluspunkt für das Entrauschungsmuster und schlug ein neues vor. Nach vielen Millionen Trainingsrunden wurde die erste KI durch diese Tests immer treffsicherer bei der Umwandlung von Texten zu Bildern.
Massenhafte Text-zu-Bild-Erkennung
Die obere Methode funktioniert zwar prinzipiell, hat aber einen Haken. Sie ist langsam und setzt natürlich irgendwie voraus, dass irgendjemand massenhaft Texteingaben der KI zum Trainieren vorsetzt, damit sie später weiß, welche Begriffe wie bildlich umgesetzt werden.
Forscher nutzten deshalb einen Trick, der heute einer der Grundprobleme bei der Akzeptanz von KI-Bilder-Tools ist: Sie gründeten das „Large-scale Artificial Intelligence Open Network“ (Groß angelegtes offenes Netz für künstliche Intelligenz), kurz LAION.
LAION ist ein gemeinnütziger Verein, welcher massenhaft Daten aus dem Internet sammelt, um damit KIs zu trainieren. Diese Daten werden nach Typ und Qualität sortiert. So gibt es zum Beispiel das „LAION-5B“-Set, welches 5,85 Milliarden Text-Bild-Kombinationen in allen möglichen Sprachen zusammengefasst hat, das „LAION-400M“-Set mit 400 Millionen Text-Bild-Kombinationen in englischer Sprache oder das „LAION-Aesthetics“-Set, welches eine Untergruppe von „LAION-5B“ ist, welches nur ästhetisch ansprechende Bilder enthalten soll.
In der Praxis wurden neben der Bild-URL und der Beschreibung noch andere Kriterien gespeichert, welche ebenfalls durch eine KI erzeugt wurden, wie Qualität der Beschreibung oder wie wahrscheinlich das Bild „NSFW“ (not safe for work) ist, also nicht jugendfrei.
Der Knackpunkt ist hier, dass der Verein also haufenweise Bilder gespeichert hat, um sie der Forschung zugänglich zu machen. Wie soll die KI aber genau wissen, was auf den Bildern zu sehen ist? Dafür nutzten die Forscher die häufig vorhandenen Metadaten, welche Fotografen, Künstler oder SEO-Firmen an die Bilder angehängt hatten, damit Suchmaschinen die Bilder besser einordnen konnten.
Stockfotografen kennen das von der Bildbeschreibung, mit der sie ein Bild zusätzlich mit dessen Text-Äquivalent versehen, damit Bildkunden es über die Suchfunktion der Bildagentur finden können.
Besonderen Wert hatten also die sorgfältig beschrifteten Bilder, die als Futter für das KI-Training genutzt wurden und weiterhin werden.
Die Erstellung vom latenten Raum
Wenn jetzt jemand einen Befehl in eine Bild-KI eingibt, kopiert die KI nicht einfach stumpf Teile existierender Bilder, sondern die Informationen kommen aus dem sogenannten „latenten Raum“ (latent space). Dieser heißt so, weil die Objekte und Konzepte dort „latent“ vorhanden sind. Der Computer weiß, wie etwas generiert wird, macht es aber erst, wenn eine bestimmte Kombination abgerufen wird.
Das KI-Training kann mensch sich ähnlich vorstellen wie Kleinkinder ihre Welt entdecken. Woher wissen Kleinkinder, wenn sie ein Bilderbuch ansehen, dass die gezeichneten Figuren ein Elefant, eine Giraffe und ein Ball sind?
Sie wissen es erst, wenn sie genug verschiedene Versionen dieser Dinge gesehen haben, um die Gemeinsamkeiten abstrahieren zu können. Ein Elefant ist zum Beispiel meist grau und groß, eine Giraffe gelb-gescheckt mit einem langen Hals und ein Ball rund und bunt.
Die KI hat das ebenfalls so gelernt, nur eben an Millionen Bild-Text-Kombinationen. So ruft sie beispielsweise alle Bilder auf, die mit dem Wort „Giraffe“ beschriftet sind, und versucht, die Gemeinsamkeiten zu erkennen. Beim Wort „Ball“ genauso. Am Anfang rät sie einfach, aber je öfter sie es macht, desto mehr erkennt sich bestimmte Muster.
Die KI merkt jedoch, dass beispielsweise Farbe oder Form kein ausreichendes Kriterium für bestimmte Objekte oder Konzepte sind, weil sich diese ändern können. Bälle können zum Beispiel verschiedene Farben haben, Elefanten verschiedene Formen und so weiter. Daher versucht die KI, möglichst viele verschiedene Variablen zu kreieren und die Begriffe in so einem Koordinatensystem zu verorten. Dieses System hat deutlich mehr als drei Dimensionen und wird als der „latente Raum“ bezeichnet.
Er enthält hunderte Variablen und deren Beziehungen zueinander. So entsteht ein multidimensionales Netzwerk aus Beziehungen, ähnlich wie eine „soziale Netzwerkanalyse“. Die Variablen für „Spaghettieis“ würden da zum Beispiel irgendwo zwischen denen für „Eiscreme“ und „Pasta“ liegen, in der Nähe von anderen kalten Objekten wie „Antarktis“ oder „Winter“, fernab von Objekten, welche mit „Härte“ assoziiert sind. Das ist für den menschlichen Geist schwer verständlich, für moderne Computer aber kein Problem.
Vom latenten Raum zur stabilen Diffusion
Wie kriegt mensch aber nun neue Bilder aus diesem latenten Raum? Durch die Texteingabe navigiert der Mensch den Computer zu einer Stelle im multidimensionalen Raumen, wo die Wahrscheinlichkeit am höchsten ist, dass die dortigen Variablen die Begriffe gut abdecken.
Nun kommt wieder das obige Entrauschungsverfahren zum Einsatz. Aus einem zufälligen Bildrauschen schärft der Computer in sehr vielen Durchgängen das Chaos zu einer Anordnung, in welcher Menschen die gewünschten Begriffe erkennen können sollen. Da dieser Prozess zufallsbasiert ist, wird auch mit der gleichen Texteingabe niemals exakt das gleiche Bild entstehen.
Diese zufallsbasierte Pixelstreuung heißt im Lateinischen „Diffusion“ und da das System stabil zwar keine gleichen, aber ähnliche Ergebnisse erzielen kann, nennt sich dieses Verfahren der KI-Bilderstellung „Stable Diffusion“.
Auch wenn die gleiche Texteingabe in ein anderes KI-Modell gegeben wird, werden sich die Ergebnisse unterscheiden, weil das Bild dann durch andere Trainingsdaten in einem anderen „latenten Raum“ erzeugt wurde.
Es gibt einige KI-Gegner, welche die KI-Bilder ablehnen, weil sie fälschlicherweise annehmen, dass die KI-Tools nur eine Art intelligente Bildmontagen-Maschine sind, welche Versatzstücke aus bestehenden Bildschnipseln neu zusammensetzt.
Als „Beweis“ werden hier gerne die manchmal sichtbaren Wasserzeichen genannt, welche erkennbar bestimmten Bildagenturen zugeordnet werden können. Diese ergeben sich jedoch aus der oben genannten Trainingsmethode. Die Agenturbilder sind für LAION besonders wertvoll gewesen, weil diese besonders häufig besonders hochqualitative Beschreibungen zu den Bildern hatten. Stockfotografen waren ja auf treffende Bildbeschreiben angewiesen für häufige Verkäufe. Das erklärt, warum Bilder mit Agenturwasserzeichen besonders häufig für KI-Trainingszwecke genutzt wurden.
Bei besonders „stocklastigen“ Motiven (denke an den „Business-Handshake“) war also die Wahrscheinlichkeit hoch, dass die KI lernte, dass solche Wasserzeichen irgendwie normal seien für das Motiv und dementsprechend „dazugehörten“. Also versucht die KI, diese Wasserzeichen mit zu reproduzieren.
Die rechtlichen Implikationen dieser Methode
Aber auch ohne das obige Missverständnis gibt es genug berechtigte Kritik. So werfen Kritiker der LAION vor, millionenfach die urheberrechtlich geschützten Werke zu Trainingszwecken genutzt zu haben, ohne dass die Künstler dafür irgendwie entschädigt wurden. LAION beruft sich zur Verteidigung darauf, dass sie eine gemeinnützige Organisation (eingetragener deutscher Verein) sei, welche nur zu Forschungszwecken arbeite.
Angesichts der Finanzierung dieses gemeinnützigen Vereins durch kommerzielle Firmen wie u.a. Stability AI, welche die Entstehung des LAION-5B“-Datensets finanziert haben und es letztendlich in ihrer KI „Stable Diffusion“ nutzen, ist das ein wackliges Argument.
KI-Befürworter weisen darauf hin, dass die KI bei ihrem Training im Grunde vergleichbar sei mit dem Vorgehen von Google. Google hatte jahrelang massenhaft urheberrechtlich geschützte Bücher und andere Texte eingescannt, um Ausschnitte davon in deren Dienst „Google Books“ zu nutzen. 2015 urteilte der us-amerikanische oberste Gerichtshof, dass dieses Vorgehen legal und von der „Fair Use“-Klausel gedeckt sei.
Auch die Frage, wie der rechtliche Status der durch die KI erstellten Bilder zu bewerten ist, ist noch völlig offen und wird vermutlich bald von einigen Gerichten geklärt werden müssen.
Die moralischen Probleme vom latenten Raum
Da das KI-Training im latenten Raum quasi ohne menschliche Eingriffe geschah, hat die KI einige Erkenntnisse gewonnen, die wir Menschen problematisch halten könnten.
Bestehende Vorurteile, Fehler oder diskriminierende Praktiken werden von de KI ungefiltert einfach übernommen und danach wiedergegeben. Wer sich bei den KI-Tools beispielsweise Bilder von einem „CEO“ generieren lässt, wird hauptsächlich ältere weiße Männer erhalten, Bilder von „Krankenpflegern“ hingegen werden vor allem weiblich sein. Auch der Fokus auf die englische Sprache schließt viele anderssprachige Kulturen und Traditionen stark aus. Versucht beispielsweise mal ein „Sankt Martin“-Bild durch die KI erzeugen zu lassen…
Stable Diffusion versucht sich an der Darstellung eines „CEO“…
…und einer Krankenschwester („nurse“)
Die KI scheitert an der Darstellung des Begriffs „Sankt Martin“
Branchen im Wandel
Ungeachtet der noch ungelösten rechtlichen und moralischen Probleme der KI-Bilderzeugung hat die Technologie jedoch das Potential, gesamte Branchen auf den Kopf zu stellen, vergleichbar mit der Erfindung des Fotoapparats.
Auch hören die Forscher längst nicht bei der Bilderzeugung auf. Mit „ChatGPT“ gibt es von den DALL-E-Machern schon eine funktionsfähige Chat-KI welche auf Zuruf längere Texte schreibt. Andere Firmen arbeiten an Text-zu-Video-Generatoren, Text-zu-3D-Objekt-Generatoren und so weiter. Werden einige der bestehenden Technologien kombiniert, beispielsweise die Chat-KI mit einer Video-KI und einer Sprach-KI, so könnten auf Knopfdruck bald individualisierte Spielfilme erzeugt werden. Die Entwicklungen hier werden in einem atemberaubenden Tempo veröffentlicht.
Ist die Funktionsweise der generierenden KIs etwas klarer geworden? Was versteht ihr ggf. noch nicht?
Vor wenigen Tagen präsentierte die deutsche Bildagentur Panthermedia in Zusammenarbeit mit dem Unternehmen vAIsual die „synthetische Portrait Kollektion“, das heißt, eine Sammlung von Portraitbildern, welche durch einen Computer erzeugt wurden.
Aktuell umfasst die Kollektion ca. 400 Bilder, es sollen aber bei 1000 Bilder sein. Die Auswahl der durch eine KI (Künstliche Intelligenz) erzeugten Bilder muss noch manuell vorgenommen werden, „da nicht alle generierten Bilder marktfähig sind“, wie Panthermedia-Geschäftsführer Tomas Speight sagt. Wer durch die Kollektion stöbern will, kann auf der Panthermedia-Webseite in der Kopfzeile auf „Synths“ klicken.
Drei Beispiele der synthetisch erstellten Portraits bei Panthermedia
Die Portraits werden wahlweise vor einem weißen oder einem grünen Hintergrund angeboten. Später sollen auch Bilder aus anderen Themenbereichen folgen. Mit aktiv in der KI-Firma vAIsual sind übrigens die Stock-Veteranen und Branchenkenner Mark Milstein und Lee Torrens.
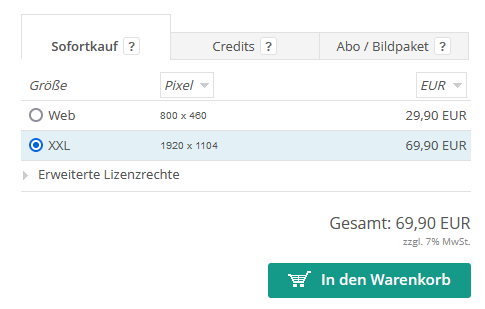
Die Bilder sind aktuell nicht in Abonnements oder Bildpaketen erhältlich. Sie sind in zwei Größen erhältlich, die Web-Größe kostet zur Zeit 29,90 Euro, die Größe XXL 69,90 Euro, wobei XXL hier auch nur gut 2 Megapixel bedeutet, was die Nutzungen im Print-Bereich noch etwas einschränkt.
Das Hauptkriterium für die Entscheidung, ein künstliches Bild zu nutzen, soll laut Panthermedia der nicht mehr notwendige Modelvertrag sein:
„Neben dem faszinierenden Kunstaspekt ist der Hauptvorteil von KI-generierten Bilder, dass keine Model-Releases erforderlich sind. Die gezeigten Personen existieren in der Realität gar nicht. Die Fotos haben somit keine der Einschränkungen wie sie in Bezug auf die Abbildung von realen menschlichen Modellen bestehen. Dies eröffnet ganz neue Möglichkeiten für eine sichere Nutzung bei sensiblen Inhalten, beispielsweise aus den Bereichen Pharma, Medizin und andere sensitiven Themen, die traditionell nicht von Model-Release-Bildern abgedeckt werden. Auch bei redaktionellen Themen ist dies ein großer Vorteil im Hinblick auf die Rechte abgebildeten Personen nach der DSGVO. Ein weiterer wichtiger Punkt in diesem Zusammenhang ist, dass diese KI-generierten Bilder als Set für das Training anderer KI-Anwendungen lizenziert werden können.“
Daher gelten für die Bildnutzung auch die aktuellen Panthermedia-Nutzungsbedingungen mit der Ausnahme, dass eine Bandbreite an „Sensitive Issues“ zugelassen ist.
Offene Fragen
Mit diesem Quantensprung tauchen nun auch neue rechtliche und moralische Fragen auf, die sich vermutlich erst nach einer Weile klären lassen werden.
Wie schon in meinem Artikel von vor zwei Jahren erwähnt, sind hier vor allem das Persönlichkeitsrecht und das Missbrauchspotential zu erwähnen.
Selbst wenn die Portraits digital erstellt wurden, können sie trotzdem Bilder generieren, die echten, real existierenden Personen sehr ähnlich sehen. Auch wird es mit solchen Bildern für Betrüger und Scammer leichter, sich einen persönlichen Anstrich zu geben, aber trotzdem anonym zu bleiben.
Und wer hat das Urheberrecht, wenn die Bilder digital von einer Maschine erzeugt wurden? Was passiert also, wenn jemand diese Bilder ohne Bezahlung benutzen würde? Kann die Agentur Nutzungshonorare einklagen?
Gefahr für Fotografen?
Vor zwei Jahren war ich entspannt, dass der aktuelle Stand der Technik Stockfotografen nicht gefährlich wäre. Das gilt mittlerweile nur noch mit Einschränkungen. Zum einen hat sich die Bildauflösung von 1 auf 2 Megapixel verdoppelt. Das ist absolut gesehen zwar immer noch recht wenig, aber schon eine deutliche Steigerung.
Weggefallen ist nun jedoch offensichtlich die Einschränkung, dass die generierten Portraits nicht kommerziell genutzt werden dürfen, was die Bedrohung für Portraitfotografen massiv steigert.
Für Stockfotografen bleiben auch im Portraitbereich zwar noch sehr viele Bereiche, welche die KI aktuell nicht abdecken kann, aber ich vermute, dass diese Bereiche im Laufe der Zeit weiter schrumpfen werden.
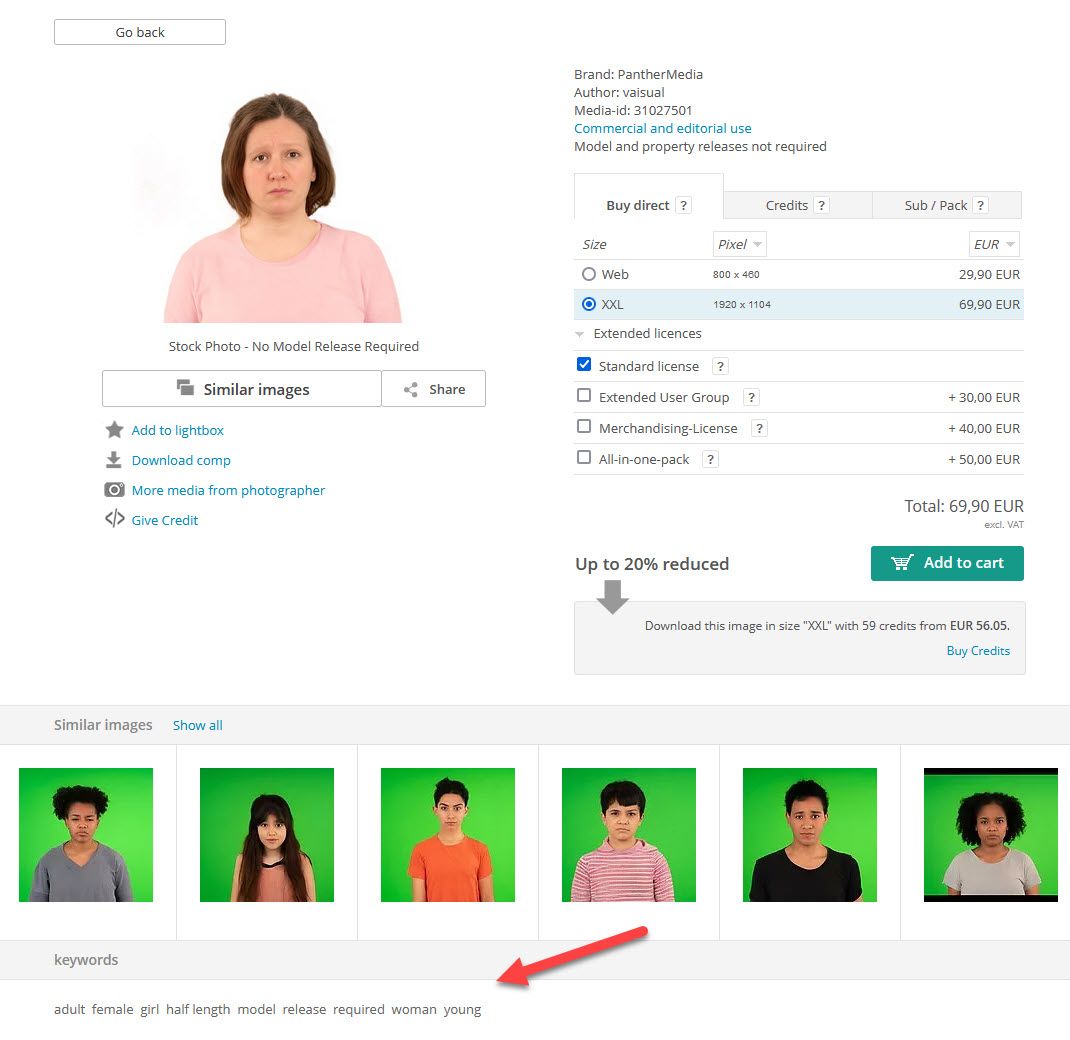
Ein kleiner Hoffnungsschimmer ist aktuell, dass die Verschlagwortung momentan mehr als dürftig ist: So enthält das obige Bild nur die neun Suchbegriffe:
Diese widersprechen sich einerseits (girl/adult) und sind auch nicht sehr akkurat (young) und wichtige andere Schlagwörter wie die Ethnie, der Gefühlsausdruck und so weiter fehlen völlig. Das kann sich mit etwas Motivation seitens der Bildagentur jedoch schnell ändern.