Letzten Monat hatte ich in diesem Artikel erklärt, wie die Künstliche Intelligenz am Beispiel von Stable Diffusion funktioniert.
Darin kam der Verein LAION e.V. zur Sprache, welcher etliche riesige Datenpakete anbietet, mit welchen KIs trainiert werden. Eines dieser Pakete heißt z.B. LAION 5B, weil es ca. 5,85 Millarden („5,85 Billions“ im Englischen, daher 5B) Datensätze umfasst.
Ein Datensatz besteht zum Beispiel aus der URL zu einer Bilddatei, der dazugehörigen Bildbeschreibung, den Bildmaßen in Pixeln, der verwendeten Sprache sowie einiger anderer Faktoren.
Anfangs war wenigen Leuten bekannt, welche Bilder genau im Datenset enthalten waren. Aber die Künstler Mat Dryhurst, Holly Herndon und Jordan Meyer gründeten die Firma Spawning, welche wiederum die Webseite „Have I Been Trained?“ ins Leben riefen.
Dort können Leute – vereinfacht erklärt – die oben genannten Bildbeschreibungen durchsuchen, um zu sehen, welche Bilder in den KI-Trainingssets enthalten sind.
Viele Urheber nutzten die Webseite und fanden wenig überraschend viele Treffer. Auch aus meinem Portfolio konnte ich nach einer kurzen Stichprobe haufenweise Bilder finden, hauptsächlich mit Wasserzeichen aus den Bildagentur-Portfolios, aber auch von Kundenseiten oder Webseiten, die selbst illegal Bildersammlungen anbieten:
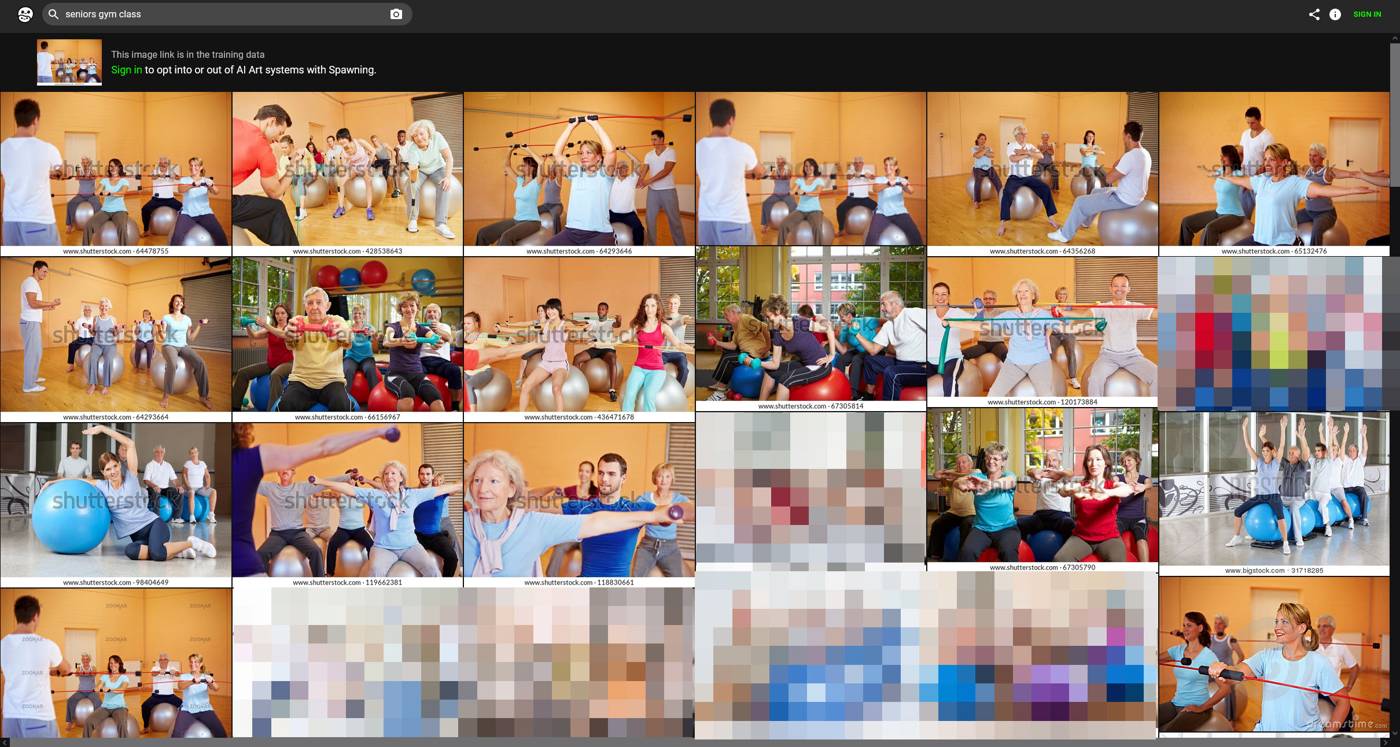
In den Kommentaren eines meiner Social Media-Profile las ich den Hinweis eines Fotografen, dass der den Verein LAION gebeten hatte, seine Werke aus den Trainingsdaten zu nehmen und als Antwort mit Schadensersatzansprüchen bedroht wurde, sollte er auf seinem Anliegen beharren.
Das kam mir wie eine wilde Geschichte vor, bis ich die Fakten überprüfte. Ich nahm Einsicht in den Schriftsatz der Anwaltskanzlei und schickte am 13.02.2023 selbst eine Anfrage an LAION e.V. per Email mit der Bitte, meine Werke aus dem Trainingssatz zu entfernen.
Nur einen Tag später erhielt ich am 14.02.2023 tatsächlich Post („vorab per Email“) von der Hannover Anwaltskanzlei „Heidrich Rechtsanwälte“ im Auftrag von LAION e.V., übrigens fast wortgleich mit dem Schreiben, welches ich von dem anderen Fotografen weitergeleitet bekommen habe.
In dem Schreiben heißt es:
„Sehr geehrter Herr Kneschke,
hiermit zeigen wir an, dass wir die rechtlichen Interessen des LAION e.V., Herman-Lange-Weg 6, 21035 Hamburg, vertreten. Die ordnungsgemäße Bevollmächtigung wird anwaltlich versichert.
Grund unseres Schreibens ist Ihre E‑Mail vom 13. Februar 2023 an unsere Mandantin, welche uns diese zur Beantwortung vorgelegt hat.
- Bei unserer Mandantin handelt es sich um einen im Vereinsregister eingetragenen, nicht-gewinnorientierten Verein, der es sich zur Aufgabe gemacht hat, selbstlernende Algorithmen im Sinne künstlicher Intelligenz fortzuentwickeln und der breiten Öffentlichkeit zur Verfügung zu stellen. Die Vereinsmitglieder sowie der Vorstand sind im Rahmen der Vereinsarbeit ehrenamtlich forschend tätig.
Unsere Mandantin hat bereits im Sommer 2022 umfangreich Rechtsrat zu verschiedenen Problemstellungen – insbesondere urheberrechtlichen Implikationen – im Zusammenhang mit ihrer Tätigkeit auf dem Gebiet der Erforschung von Kl-gestützten Bildgenerierungsmodellen eingeholt. Unserer Mandantin war es von Anfang an wichtig, dass im Rahmen ihrer Tätigkeit keine Rechte Dritter verletzt werden. Unsere Mandantin hält sich ausnahmslos an die bestehenden gesetzlichen Vorgaben, insbesondere aus dem Urheber- und Datenschutzrecht.- Unsere Mandantin unterhält lediglich eine Datenbank, die Links zu im Internet öffentlich abrufbaren Bilddateien enthält. Sie kann zwar nicht ausschließen, dass in der Datenbank auch Links zu Bildern enthalten sind, deren Urheber Sie sind. Da unsere Mandantin aber jedenfalls keine der von Ihnen monierten Fotografien speichert, besteht Ihrerseits auch kein Anspruch auf Löschung. Es existieren bei unserer Mandantin schlicht keine Bilder, die gelöscht werden könnten.
Das Bereitstellen von Links stellt nach der höchstrichterlichen Rechtsprechung auch keine Verletzung von Urheberrechten dar. Das Bereitstellen eines Links dient lediglich dem Auffinden eines ohnehin im Internet abrufbaren Inhalts. Der hinter einem Link stehende Inhalt kann auch nur an der verlinkten Stelle und nicht andernorts abgerufen werden, sodass insbesondere keine Vervielfältigung im Sinne des Urheberrechts vorliegt. Unsere Mandantin trägt keine Verantwortung für die Inhalte auf anderen Websites.- Auf Nutzungen Ihrer Werke durch Dritte hat unsere Mandantin naturgemäß keinen Einfluss. Eine Nutzung durch Dritte wird aber ohnehin auch nicht erst durch unsere Mandantin ermöglicht. Die von unserer Mandantin verlinkten Bildinhalte sind frei im Internet abrufbar. Sofern Sie eine rechtsverletzende Nutzung durch Dritte feststellen, müssen Sie sich an diese Personen wenden.
- Ihre Fristsetzung betrachten wir daher als gegenstandslos. Wir weisen außerdem darauf hin, dass unsere Mandantin gemäߧ 97a Abs. 4 UrhG Schadenersatzansprüche geltend machen kann, wenn diese unberechtigt urheberechtlich in Anspruch genommen wird.
Wir hoffen, dass wir Ihre Bedenken mit unseren Ausführungen ausräumen konnten und stehen Ihnen für Rückfragen gern zur Verfügung.“
Ja, ihr lest das vollkommen richtig. Urhebern, die nicht wollen, dass ihr Werke für Trainingszwecke benutzt werden, werden Schadensersatzansprüche angedroht.
Die restlichen Aussagen im Schreiben lassen einen ebenfalls etwas verwundert zurück. Die angebliche Gemeinnützigkeit eines Vereins, welcher unter anderem von einer Firma wie Stability AI mitfinanziert wird, welche wiederum von den Ergebnissen des Vereins kommerziell profitiert, hat mindestens ein „Geschmäckle“, was meiner Meinung nach danach riecht, hier absichtlich eine Konstruktion zu bauen, welche Haftungsfragen auslagern soll.
Auch das „ledigliche Unterhalten einer Datenbank“ ist hier meiner Meinung nach etwas zu kurz gegriffen, da neben den oben genannten Datenpunkten auch Daten wie „similarity“, „pwatermark“ oder „punsafe“ enthalten, welche nicht einfach ausgelesen, sondern erstellt werden müssen, was vermutlich zumindest eine temporare Speicherung der Bilddaten erfordert haben wird. Das legt auch diese Infografik nahe, in der erklärt wird, das die Bilder und Daten „heruntergeladen“ wurden:
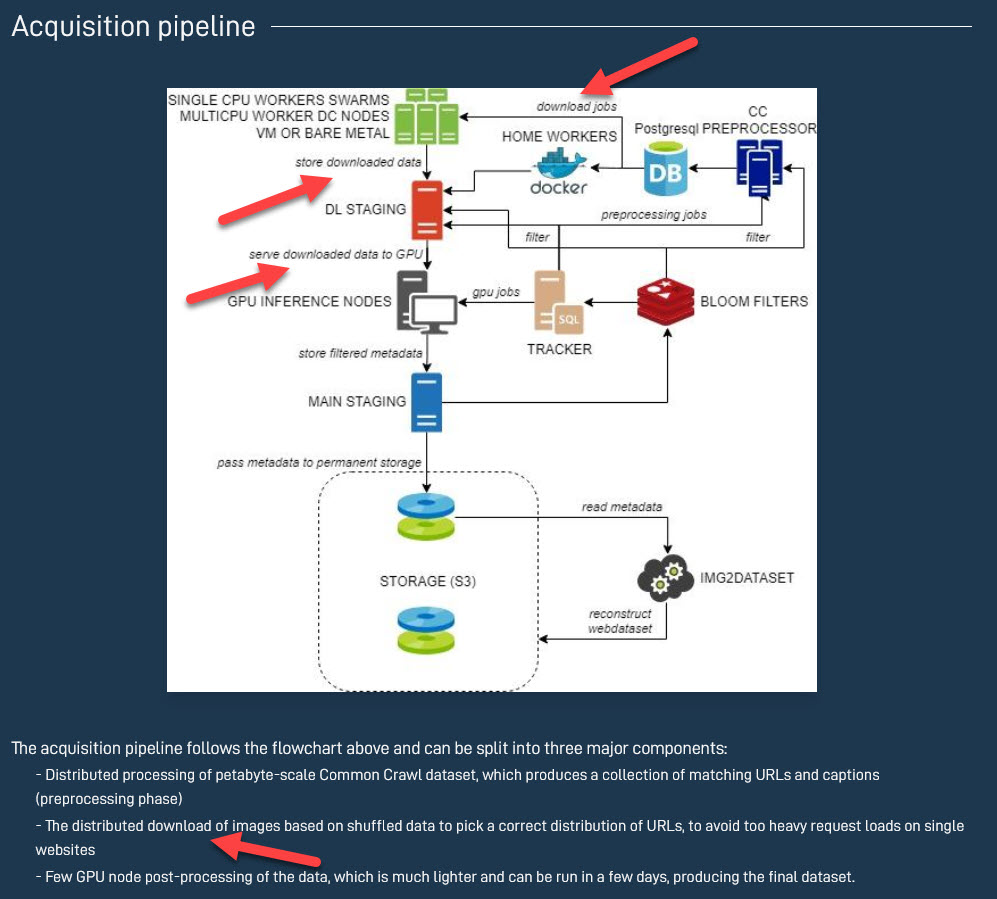
Das sind im Detail aber auch Vermutungen, welche wahrscheinlich bei einem Gerichtsprozess geklärt werden müssen.
Genau so einen Prozess werde ich nun anstreben, um die Frage richterlich klären zu lassen, ob das Vorgehen tatsächlich rechtlich so einwandfrei ist, wie die Anwaltskanzlei behauptet.
Falls ihr als Urheber ebenfalls einige eurer Werke im Datensatz von LAION findet und vielleicht auch Post von obiger Anwaltskanzlei erhalten wollt, findet ihr die Emailadresse für eure Anfrage zur Datenlöschung hier im Impressum von LAION e.V..




