Was ist der aktuell beste KI-Upscaler?
Vor wenigen Tagen hat die KI-Firma Midjourney einen neuen Upscaler veröffentlicht, der deren KI-Bilder um den Faktor 2 oder 4 vergrößern kann.
Da ich bisher ein anderes Tool genutzt habe, wollte ich herausfinden, wie sich die Bildqualität unterscheidet. Wo ich schon dabei war, habe ich noch paar andere Upscaler verglichen und die Ergebnisse bei Facebook und LinkedIn gepostet. Da gab es in den Kommentaren noch weitere Vorschläge, welche Upscaler ich berücksichtigen sollte.
Na gut, dachte ich mir, dann ziehe ich das eben größer auf und veröffentliche hier einen umfassenden Test über die Bildqualität und Unterschiede der aktuell auf dem Markt erhältlichen Upscaler.

Der Testaufbau und das Ausgangsbild
Ich habe mir mit dem KI-Tool Midjourney ein quadratisches PNG-Bild einer blonden Frau generieren lassen mit der Auflösung 1024x1024 Pixel (1,05 Megapixel):

Dieses Bild habe ich dann mit verschiedenen Methoden um den Faktor 4 auf 4096x4096 Pixel (16,7 Megapixel) vergrößern lassen.
Da die Beurteilung der Ergebnisse subjektiv gefärbt ist und jeder andere Maßstäbe an seine Bilder anlegt, veröffentliche ich hier auch die PSD-Datei der verschiedenen Ergebnisse als Download, jede Ebene ist sauber nach der genutzten Upscaler-Methode benannt.
DOWLOAD-Link (Dropbox) als gepackte .rar-Datei (ACHTUNG: Datei ist 610 MB groß, entpackt dann 889 MB!) BACKUP-Link (Wetransfer).
Damit kann jede*r durch das Ein- und Ausblenden der Ebenen in der 100%-Ansicht selbst entscheiden, welches Ergebnis ihm/ihr am meisten zusagt.
Für diesen Blogartikel habe ich einen Bereich des linken Auges ausgeschnitten, damit hier die 100%-Ansicht (500x500 Pixel) gezeigt werden kann. Die Ausschnitte habe ich sauber benannt und als JPG (Qualität 10) abgespeichert. Der Ausschnitt ist in der Photoshop-Datei auch als Pfad hinterlegt.
Der große Upscaler-Test: Die Ergebnisse
1. Midjourney Upscaler
Beginnen wir mit dem Upscaler von Midjourney. Obwohl dieser erst wenige Tage alt ist, gibt es schon zwei Versionen und Midjourney behält sich vor, den Upscaler auch in Zukunft zu verändern/verbessern:
„The upscaler is subtle and tries to keep details as close as possible to the original image (but may not fix glitches or issues with the old image)“

Die erste Version (V1) des Midjourney-Upscaler bügelte die Hauttextur ziemlich glatt, das ganze Bild wirkt insgesamt sehr nach 1980er-Jahre-Airbrush-Retusche.
Das Entwickler-Team nahm sich die Kritik der Community jedoch zu Herzen und schob zwei Tage später das erste Update hinterher:
„We’re […] hearing everyone’s feedback that the 4x upscaler is a bit soft and we’re looking at improvements which may further improve things. This means the upscaler settings may change suddenly over the next week without warning as we tweak things.
[…]
The V5 4x Upscale now features improved sharpness, and in some cases smaller scale high frequency details“
Dadurch sieht das Ergebnis deutlich besser aus, die Haare und Wimpern sehen täuschend echt aus und auch die Hauttextur kann überzeugen:

Der erste große Nachteil dieses Upscalers ist logischerweise, dass er nur auf KI-Bilder anwendbar ist, die direkt in Midjourney erstellt wurden.
Ein weiterer Punkt sind die Kosten: Der 4x Upscaler kostet grob 6x soviel GPU-Minuten wie die Generierung eines 4x4-Bilder-Grids. Diese Zeit wird von dem bezahlten Minutenkontingent abgezogen, welches die Nutzer je nach Abomodell zur Verfügung haben. Im Standard-Plan sind das zum Beispiel 15 Stunden pro Monat.
Eine Stunde Rechenzeit kann aktuell für 4 USD dazu gekauft werden. Ich habe mal geschaut, wie viel Zeit für ein 4x-Upscale von Midjourney berechnet wird. Beim obigen Bild waren das ca. 3 Minuten. Mit einer Stunde Rechenzeit könnten damit 20 Bilder hochskaliert werden. Bei Kosten von 4 USD/Stunde würde ein Upscale ca. 20 US-Cent kosten. Wer die inklusiven Stunden im Standard- oder Pro-Plan nutzt, zahlt nur die Hälfte.
2. Topaz Photo AI
Der Upscaler von Topaz Labs war unsere bisherige bevorzugte Upscale-Methode. Getestet haben wir hier mit der Version 2.0.5.
Topaz Photo AI ist ein recht neues Tool, mit dem verschiedene KI-basierte Werkzeuge wie Topaz Gigapixel, Topaz Sharpen etc. zusammengefasst wurden.

Die Ergebnisse sehen sehr überzeugend aus, vor allem die Hauttextur ist sehr realistisch, die Details wie Wimpern und Haare sind jedoch etwas gröber.
Topaz hat auch eine Funktion namens „Recovering Face“, womit laut Hersteller die Ergebnisse von Gesichtern in geringer bis mittlerer Auflösung deutlich verbessert werden kann:
„Recover Faces dramatically improves low-medium quality faces.“
Es gibt einen Regler, der stufenlos von 0 bis 100% eingestellt werden kann. Bei 25% sieht das Ergebnis so aus:

Ich finde, dass das Gesicht dadurch einfach matschiger wird. Dieser Effekt nimmt mit der Stärke der Recover-Funktion zu, bei 100% ist das Ergebnis deutlich unbrauchbarer als ganz ohne die Funktion. Vermutlich liegt das daran, dass die Bildqualität vom Ausgangsmaterial schon „zu gut“ für diese Funktion ist, die der Verbesserung von „low quality faces“ dienen soll.
Ein weiterer Vorteil von Topaz Photo AI ist, dass hier Bilder als Batch bearbeitet werden können und neben dem Hochskalieren im gleichen Arbeitsgang wahlweise auch geschärft, entrauscht, farblich angepasst etc. werden können.
Mit 199 USD sind die Kosten initial recht hoch, dafür können damit unbegrenzt Bilder bearbeitet werden und es gibt regelmäßige Updates. Für Vielnutzer preislich die beste Wahl. Weiterer Pluspunkt: Es gibt ein Photoshop-Plugin.
3. Photoshop
Die früher übliche und seit langem verfügbare Methode mit Photoshop-Bordmitteln war, einfach die Bildgröße hochzusetzen. Das Ergebnis, getestet mit Photoshop 2024 (V25.0), sieht dann so aus:

Es ist damit sichtbar mit Abstand das schlechteste Ergebnis, was wenig verwundert, da hier noch keine KI Hilfestellung leistet. Selbst mit dem bekannten Kniff, das Bild in 10%-Schritten hochzuskalieren, war das Ergebnis nur minimal besser und reicht trotzdem nicht an die anderen Methoden heran.
In den Kommentaren zu meinem ersten Test gab es zwei Hinweise, wie ich die Ergebnisse verbessern könnte. Der erste war, dass sich hinter dem Häkchen „Neu berechnen“ noch eine Auswahlmöglichkeit für „Details erhalten 2.0“ verbirgt:
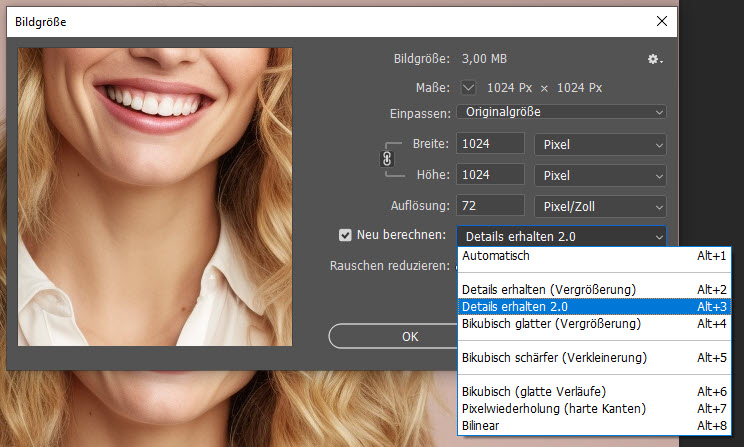

Das Ergebnis ist zwar „besser“ und schärfer, dafür aber mit sichtbaren Artefakten übersät. Wenn ich den Regler „Rauschen reduzieren“ auf 50% setze, verschwinden die Artefakte, aber das Bild sieht etwas weichgezeichnet aus.
Kurz: Der schlechteste Upscaler im Test. Es wundert mich etwas, dass hier die Adobe Sensei-KI noch nicht Einzug gehalten hat, aber vermutlich wird das ein Feature sein, was eher früher als später veröffentlicht werden wird.
Jemand meinte noch, dass sich unter den „Neural Filters“ ein „Superzoom“-Filter verberge. Das ist jedoch kein richtiger „Upscaler“, weil damit das Bild tatsächlich „rangezoomt“ wird, ich verliere also die Bildmotive am Rand.
Dafür sind die Kosten jedoch unschlagbar, da jeder mit einem Photoshop-Abo unbegrenzt viele Bilder hochskalieren kann.
Kurzes Update 23.10.2023: (sample images not included in download yet)
Einige Leser wiesen mich darauf hin, dass die „Superzoom“-Funktion doch das ganze Bild anzeigt, wenn die Option „Bild > Alles einblenden“ genutzt wird. Zusätzlich gibt es einige Auswahlmöglichkeiten wie z.B. „Gesichtsdaten verbessern“ und „JPG Artefakte reduzieren“:

Das Ergebnis sieht schon besser als mit der alten Photoshop-Methode aus und rangiert damit im oberen Mittelfeld. Für die Top-Liga sind die Bereiche wie Haare oder Wimpern noch etwas zu matschig.
Außerdem bietet Adobe in Lightroom oder Camera Raw die „Verbessern“-Option, welche ebenfalls hochskaliert, aber nur bei Raw-Dateien funktionieren soll.
4. Luminar Neo

Luminar Neo ist, ähnlich wie Topaz Labs, ein weiteres KI-gestütztes Tool-Kit für die Fotobearbeitung mit vielen Funktionen. Getestet wurde hier mit der Version 1.14.1.12230 im Upscale Type „Universell“.
Gefühlt würde ich sagen, dass das Ergebnis irgendwo zwischen Midjourney und Topaz liegt. Die Details sind etwas gröber als bei den anderen beiden Upscalern, die Haut weichgezeichneter als bei Topaz, aber weniger als bei Midjourney.

Es gibt bei der Hochskalieren-Funktion noch das optionale Häkchen „Gesichtsverstärker AI“, welches jedoch schlicht gesagt (bisher) grausame Ergebnisse liefert. Es sieht so aus als würde hier ein Geisterbild über dem anderen liegen. Kurz: Finger weg von dem Häkchen.
Die Kosten von Luminar Neo liegen bei 219 Euro für die lebenslange Nutzung, es gibt aber auch Abo-Modelle ab 11,95 Euro/Monat, was sich gut zum Testen eignet. Dafür bekommt man aber nicht nur die Hochskalieren-Funktion, sondern ein breites Bündel an Werkzeugen wie Entrauschen, Schärfen, Lichtmanipulationen, und vieles mehr. Die Handhabung mit dem separaten Installieren der verschiedenen Plugins finde ich jedoch nicht ganz intuitiv.
5. Pixelcut
Pixelcut ist ein kostenloser Online-Upscaler, welcher bequem via Drag & Drop funktioniert.
Das Ergebnis ist relativ grob, aber besser als Photoshop. Dafür sind die Kosten gleich null. Für Gelegenheitsnutzer also sehr praktisch.
Es ist auch eine Batch-Nutzung möglich, die dann jedoch im „Pixelcut Pro“ 9.99 USD pro Monat oder 59.99 USD im Jahr kostet. Dafür ist dann auch eine iPhone/Android-App-Nutzung enthalten und unbegrenzte Hintergrundentfernung.
6. Neural.love
Neural.love ist ein online-basierter AI-gestützter HD Portrait-Generator, der als Leserhinweis seinen Eingang in diesen Test fand.
Der Leistungsumfang reicht von der direkten KI-Bilderstellung über Image-to-Image Bildremixe, Portraitrestaurierungen etc. und eben auch ein Upscaler namens „Image Enhance/Quality Enhance“.

Das Ergebnis ist etwas detaillierter als bei Pixelcut, reicht aber von der Schärfe nicht an Topaz oder Midjourney heran.

Es gibt noch die Option, „Smart Noise“ zu aktivieren, was – wie der Name schon vermuten lässt – ein feines Rauschen über das Bild liegt. In der 100%-Ansicht ist das recht auffällig, beim Rauszoomen ist der Eindruck aber positiver als ohne das Rauschen.
Das Online-Tool erfordert eine Registrierung per Email und arbeitet mit einem Credit-System für die Kosten. Die ersten fünf Credits sind frei (also 5x Upscaling), danach können 300 Credits im Abo für 30 Euro/Monat oder zeitlich unbegrenzt für 57 Euro gekauft werden. Das wären dann 10 bzw. 19 Cent pro Upscale.
7. Upscale.media
Upscale.media ist ein weiterer Online-Upscaler auf Credit-Basis:

Das Ergebnis rangiert solide im Mittelfeld und ist schon gut brauchbar.

Es gibt auch die Option, ein Häkchen bei „Qualität verbessern“ zu setzen, doch das scheint das Gegenteil zu bewirken. Das Bild verliert an Details und die Konturen werden unnatürlich stark betont. Würde ich nicht empfehlen.
Kosten? Pro Tag sind zwei Uploads ohne Registrierung kostenlos möglich, nach Registrierung gibt es fünf kostenlose Uploads. 100 Credits kosten im Abo 19 USD bzw. zeitlich unbegrenzt 49 USD, was 19 US-Cent bzw. 49 US-Cent pro Upscaling entspricht.
8. Stable Diffusion Upscaler
Auch im quelloffenen KI-Generator Stable Diffusion gibt es gleich mehrere Upscaler. Hier öffnet sich aber auch die Büchse der Pandora, weil es neben den sieben verschiedenen Upscalern, die im Web-UI von Automatic111 dabei sind, noch unzählige weitere gibt, die auch jeweils noch viele verschiedene Settings haben.
Allein in der Datenbank OpenModelDB finden sich unter „General Upscaler“ 66 verschiedene Modelle, die kostenlos heruntergeladen und installiert werden können und alle ihre Stärken und Schwächen haben.
Um die Sache noch komplexer zu machen, können Bilder auch mittels der „IMG2IMG“-Methode hochskaliert werden, wobei hunderte verschiedene KI-Modelle zur Auswahl stehen.
Deshalb habe ich hier nur mal einen internen Upscaler getestet, den Upscaler „ESRGAN_4x“ mit einer GFPGAN visibility von 0.5.

Das Ergebnis ist ca. doppelt so gut wie die Photoshop-Methode, aber sichtbar schlechter als die meisten anderen Upscaler im Test.
Dazu kommt, dass die Geschwindigkeit des Skalierens ganz stark von der lokal verwendeten Hardware abhängt. Mit einer RTX 2080-Grafikkarte dauerte das Hochskalieren über 15 Minuten. Wer die Settings noch etwas mehr hochdreht, muss exponentiell länger warten.
Auch die Bedienung gestaltet sich komplex, da die Modelle gefunden und runtergeladen werden müssen und für die verschiedenen Settings keine Anleitung existiert. Ihr werdet also auf etlichen Webseiten rumsurfen, um euch die empfohlenen Einstellungen zusammenzusuchen.
Dafür sind die Kosten fast Null, da alle benötigten Tools kostenlos erhältlich sind. Ihr zahlt also nur für euren Strom.
Wer mehr Stable Diffusion Upscaler im Vergleich sehen will, findet hier einen ähnlichen Test.
9. ChaiNNer Upscaler
ChaiNNer ist ein weiterer Tipp aus den Kommentaren. Das ist ein OpenSource-Projekt, welches ursprünglich als KI-Upscaler gestartet ist, mittlerweile aber sehr umfangreiche Bildverarbeitungsfunktionen bietet.
ChaiNNER ist node-basiert, was sehr ungewohnt ist, für die, die es nicht kennen, aber wer das Prinzip verstanden hat, kann auf diese Weise sehr komplexe Workflow-Ketten aufbauen, die dann mit einem Klick abgearbeitet werden. Der Workflow für das einfache Hochskalieren sieht dann so aus:
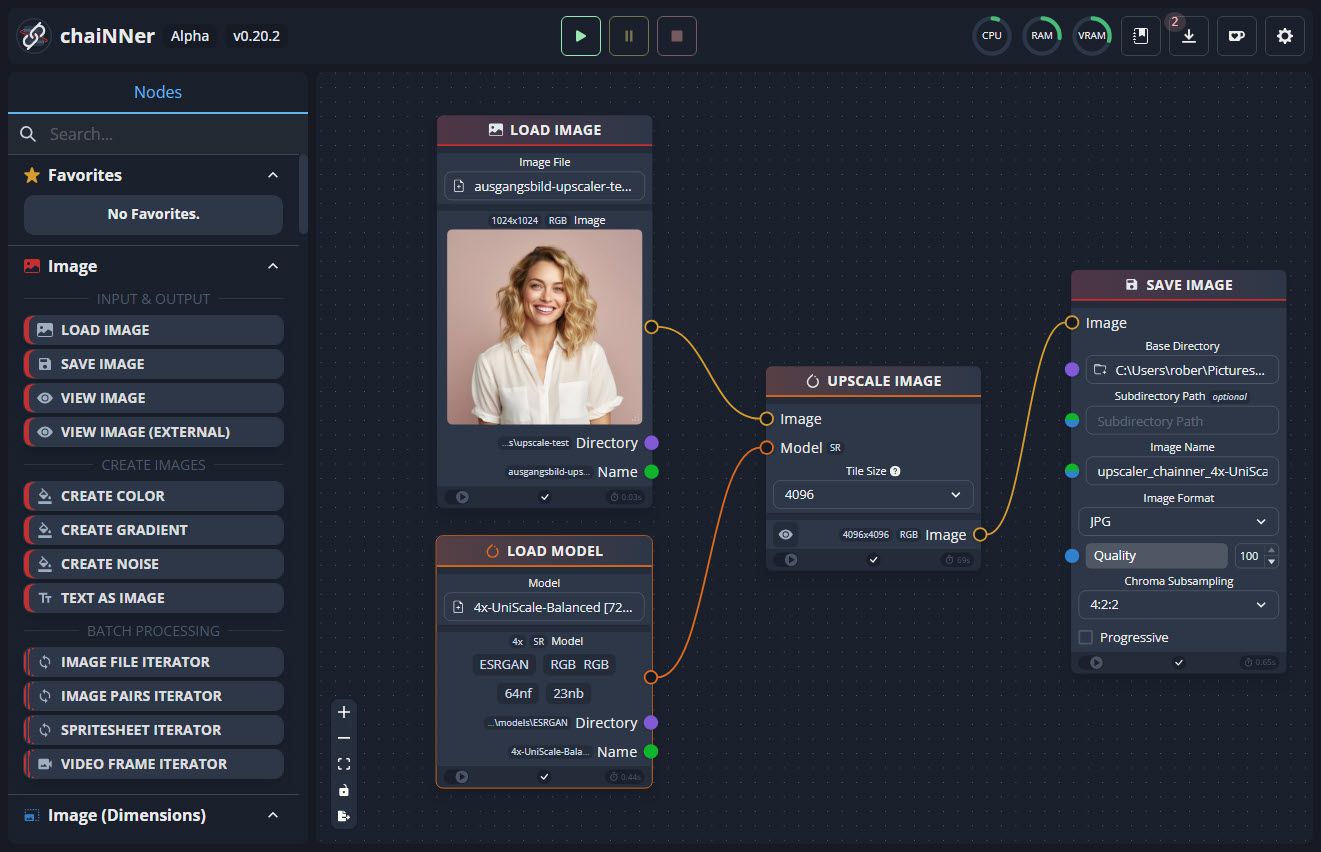
Das Programm ist noch in der Alpha-Phase (ich habe v0.20.2 genutzt) und kostenlos für Windows, Mac und Linux erhältlich. Die Installation erfordert etwas Zeit, ist aber in der GitHub-Anleitung gut beschrieben.
ChainNNer selbst ist genau genommen gar kein Upscaler, sondern dient als GUI (grafische Benutzeroberfläche) für andere OpenSource-Upscaler auf PyTorch-Basis. Das heißt, fast alle Upscaler die bei Stable Diffusion integriert werden können, sind auch in ChaiNNer nutzbar. Wie im Bereich „Stable Diffusion“ erwähnt, stehen euch also mindestens 66 verschiedene Möglichkeiten zur Verfügung.

Getestet habe ich ChaiNNer mit dem beliebten „Remacri“-Modell, welches eine überzeugende Kombination aus Schärfe und Struktur liefert. Ebenfalls nicht ganz so gut wie Topaz oder Midjourney, dafür kostenlos und seeehr flexibel.

Ich habe noch ein weiteres Modell getestet, das „UniScale-Balanced“ auf Basis der ESRGAN-Architektur. Das schnitt jedoch deutlich schlechter ab als „Remacri“.
Noch mal zum Verständnis: In Stable Diffusion und ChaiNNer können die gleichen Upscaler-Modelle eingesetzt werden, bei mir lief die Verarbeitung jedoch deutlich schneller bei ChaiNNer. Dafür gibt es bei Stable Diffusion etwas mehr Einstellmöglichkeiten, die ich auf die Schnelle nicht bei ChaiNNer gefunden habe.
Das Resultat
Es gibt noch unzählige weitere Tools, vor allem online, aber die meisten davon rangieren im Mittelfeld und sind preislich ähnlich angesiedelt.
Von der Bildqualität liegt Midjourney aktuell meiner Meinung nach stark vorne, hat eben aber den gravierenden Nachteil, dass damit nur Midjourney-Bilder hochskaliert werden können. Auch preislich ist Midjourney kein Zuckerschlecken, wenn man nicht gerade eh Stunden übrig hat in deren Abo-Modell.
Für Power-User, die mehr als 1000 Bilder hochskalieren wollen, bleibt die Wahl zwischen Topaz Photo AI und Luminar Neo preislich die bessere Wahl, wobei Topaz in der Bedienung wegen der Automatisierungsmöglichkeiten etwas die Nase vorn hat.
Insgesamt ist die Qualität aber auch subjektiv behaftet und kann sich je nach Motiv oder mit einem Update eines Tools auch wieder ändern.
Bei den ganzen, teils kostenlosen, Online-Upscalern solltet ihr auch bedenken, dass ihr eure Daten in fremde Hände gebt und dem Anbieter vertrauen solltet, damit vertraulich umzugehen. Vermutlich werden auch die meisten dieser Anbieter unter der Haube eines der unzähligen OpenSource-Upscaler laufen haben.
Welchen Upscaler nutzt ihr aktuell und welches Ergebnis hat euch hier am meisten überzeugt?
Die Community-Test-Erweiterung
Wer den Test mit eigenen Modellen oder anderen Anbietern erweitern will, hat in diesem Artikel alle notwendigen Grundlagen: Das 1024x1024-Ausgangsbild steht oben zum Download zur Verfügung sowie die Photoshop-Datei mit den Ebenen der Upscaler und der Pfad-Auswahl für die Ausschnittvergrößerung.
Ihr könnt also gerne weitere Methoden testen und das Ergebnis gerne in den Kommentaren posten (Bilder bitte als Link).





