Auf meiner Facebook-Seite hatte ich hier kürzlich gefragt, wie groß das Interesse sei, die Erstellung von solchen interaktiven 360°-Bildern zu lernen:
Da der Andrang groß war, gibt es heute das komplette Tutorial, wie ihr diese 360-Grad-Bilder selbst erstellen und anzeigen lassen könnt. Klickt gerne mit der Maus auf das Bild, um die Ansicht zu ändern oder unten rechts auf das „VR“-Symbol, um das Gleiche im Vollbild-Modus zu machen.
1. Die Bilderstellung
Zuerst braucht ihr dafür natürlich Zugang zu einem Generativen KI-Programm. Ich arbeite bevorzugt mit Midjourney, aber getestet habe ich es auch mit Dall‑E 3 und prinzipiell sollte es – je nach Qualität des KI-Generators – auch mit anderen Tools wie Adobe Firefly oder Stable Diffusion funktionieren.
Als Prompt habe ich bei Midjourney diesen hier verwendet (die eckige Klammer sollte weggelassen werden, mehr dazu unten):
/imagine 360° equirectangular photograph of [an empty futuristic spaceship commando room interior] –ar 2:1 –v 6.0–style raw
Wichtig sind hier vor allem die ersten beiden Begriffe 360° und die gleichwinklige Projektion (equirectangular projection) sowie das Seitenverhältnis von 2:1, welches im Midjourney-Prompt durch das Parameter-Kürzel –ar definiert wird.
Bei der gleichwinkligen Projektion wird diese aus einem einzigen Bild zusammengesetzt, wobei der horizontale Winkel 360° und der vertikale 180° beträgt. Daher sollte das Seitenverhältnis 2:1 sein, um unnötige Verzerrungen zu vermeiden. Adobe Firefly kommt z.B. nur bis zum Seitenverhältnis 16:9, weshalb die Ergebnisse weniger überzeugend aussehen.
Die Versionsnummer (v6) und der Style (raw) sind Geschmackssache und können variiert werden. Ich habe diese gewählt, weil sie aktuell die beste Renderqualität (v6) liefern bei realistisch anmutendem Ergebnis (raw).
Statt des Raumschiff-Prompts in der eckigen Klammer könnt ihr natürlich eurer Fantasie freien Lauf lassen. Beim oben verlinkten Facebook-Post lautete der Prompt zum Beispiel:
/imagine 360° equirectangular photograph of the rainforest –v 6.0 –ar 2:1 –style raw
Ihr könnt aber auch deutlich elaborierter in eurer Beschreibung werden, wenn ihr wollt.
Midjourney zeigt euch dann vier Auswahlmöglichkeiten an. Hier solltet ihr bei der Wahl eures Favoriten schon darauf achten, ob die linke und rechte Bildkante sich halbwegs dazu eignen, miteinander verbunden zu werden.
Die vier Ergebnisse des ersten Prompts
Im obigen Beispiel habe ich mit einem roten Pfeil markiert, wo die KI einen Lichteinfall gerendert hat, der sich nicht auf der rechten Kante wiederfindet. Das würde die optische Illusion zerstören. Beim oberen linken Bild sind oben und unten schwarze Balken, die ebenfalls störend sind. Daher habe ich mich für das Bild links unten entschieden.
Hinweis: Es gibt in Midjourney auch den Parameter „–tile“, der dafür sorgen soll, dass die Bilder nahtlos kachelbar sind, was für unsere Zwecke erst mal prinzipiell gut klingt. Manchmal funktioniert es auch gut, aber leider achtet Midjourney dann auch darauf, dass die obere und untere Kante zusammenpassen, was bei Außenaufnahme, wo oben Himmel und unten Erde ist, selten gute Ergebnisse bringt. Bei Innenaufnahmen ist die Trefferquote höher. Daher: Einfach mal testen.
Das fertige Bild wird mit „U3“ vergrößert (upscaling) und dann noch mal „Upscale (Subtle)“ vergrößert. Damit haben wir schon eine Auflösung von 1536x3072 Pixeln. Wer will, kann diese Auflösung mit einer der hier aufgezählten Upscale-Methoden noch weiter erhöhen. Das Raumschiff-Bild habe ich mit Topaz Photo AI auf 3072x6144 Pixel vergrößert.
Wie schon oben erwähnt, funktioniert es prinzipiell auch mit ChatGPT, wenn auch das Seitenverhältnis nicht korrekt als 2:1 ausgegeben wurde und die fertige Auflösung geringer ist:
2. Die Bildbearbeitung
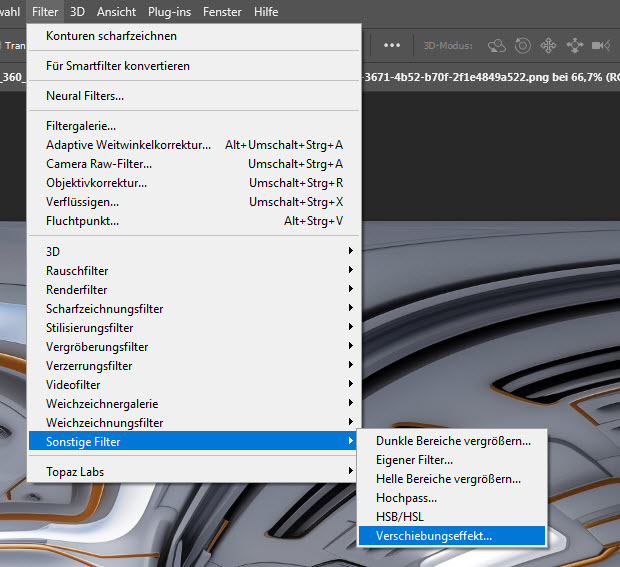
Das fertige PNG-Bild öffne ich nun in Photoshop und wähle den Befehl „Verschiebungseffekt“ (unter Filter/Sonstige Filter):
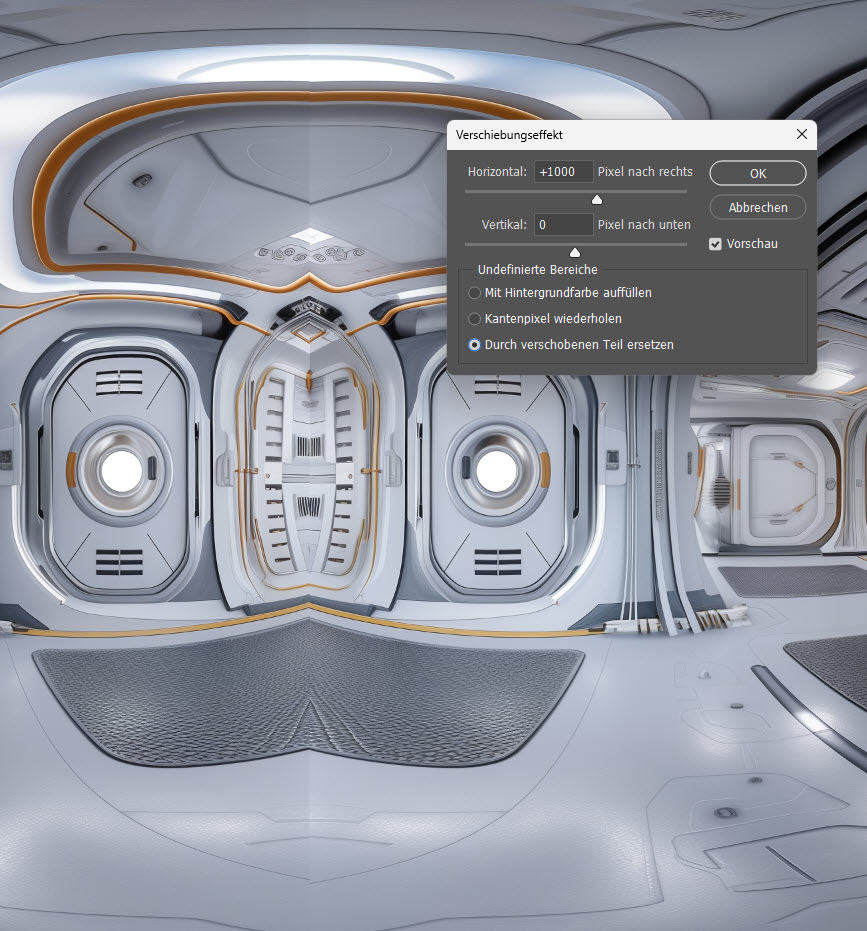
Im sich öffnenen Menüfenster gebe ich nun „horionzal +1000 Pixel nach rechts“ ein. Wichtig ist, dass unten die Option „Durch verschobenen Teil ersetzen“ aktiv ist.
Damit verschiebt sich das Bild um eintausend Pixel nach rechts und wir sehen auch im Screenshot schon, wo die Nahtkante unseres Bildes ist. Diese können wir mit den Photop-Bordmitteln wie „generatives Entfernen“, „generatives Füllen“ und den altbekannten Stempel-Werkzeugen bearbeiten, bis die Kante nicht mehr so stark erkennbar ist. Tipp: Einfach den Übergang komplett mit dem rechteckigen Auswahlwerkzeug markieren und „Generatives Füllen“ anklicken, wirkt oft wahre Wunder.
Hier meine bearbeitete Version:
Zusätzlich könnt ihr natürlich je nach Belieben das Bild vom Farbton, Kontrast etc. anpassen oder andere Bildbereiche verbessern, entfernen oder austauschen.
Wenn ihr fertig seid, könnt ihr den „Verschiebungseffekt“ in die andere Richtung (also ‑1000) anwenden, damit das Bild wieder in seine Ausgangsposition verschoben wird.
Das ist nicht unbedingt notwendig, aber die meisten 360°-Anzeigen nutzen die Bildmitte als Startpunkt, welcher dadurch von uns beeinflusst werden kann.
Das fertige Bild sollte als JPG abgespeichert werden.
3. Die Bild-Metadaten
Damit Tools unser Bild nun auch als „echtes“ 360°-Bild erkennen, müssen wir manuell Metadaten hinzufügen, welche durch 360°-Kameras erzeugt werden. Wir täuschen damit quasi vor, unser KI-Bild sei mit einer richtigen Kamera aufgenommen worden.
Die Pixelwerte können (und sollten) natürlich abweichen, wenn euer Bild andere Pixelmaße aufweist.
Damit ihr nicht wie der letzte Höhlenmensch in eure EXIF-Daten eingreifen müsst, gibt es verschiedene Offline- und Online-Tools, welche das für euch übernehmen.
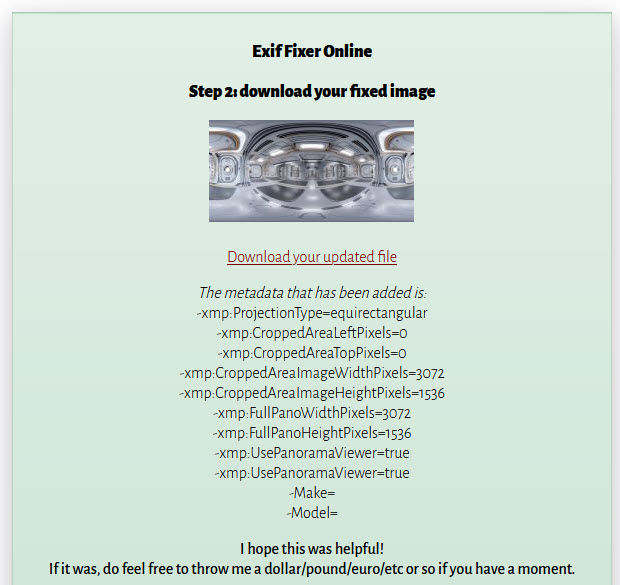
Ich nutze selbst gerne den „Exif Fixer Online“. Dieser unterstützt JPG-Bilder bis zu 15 MB. Nach dem Hochladen des Bildes erhaltet ihr einen Link, wo ihr die „gefixte“ Version mit den korrekten Metadaten runterladen könnt:
WICHTIG: Damit die Datei als 360°-Bild ausgelesen werden kann, müssen diese Metadaten intakt bleiben. Das Versenden der Datei mit Whatsapp oder Email etc. kann dazu führen, dass diese Metadaten wieder gelöscht werden und das Bild nicht interaktiv angezeigt werden kann.
4. Die Anzeige
Kommen wir zur Belohnung für unsere Mühen. Damit wir das 360°-Bild anzeigen lassen können, müssen wir es irgendwo hochladen, wo diese Art der Anzeige unterstützt wird.
Hier im Blog habe ich auf die Schnelle das kostenlose Plugin „Algori 360 Image“ installiert, es gibt aber auch etliche andere.
Eine andere Möglichkeit ist das Hochladen des Bildes bei Facebook oder Google Photos. Zusätzlich gibt es hier eine Liste von weiteren Apps, welche diese 360°-Anzeige unterstützen.
5. Galerie und Material zum Testen
Wer sehen will, dass das oben kein Glückgriff war, sondern auch mehrmals funktioniert, kann sich hier meine „360° KI-Bilder“-Galerie auf Facebook ansehen.
Wer gerade keinen Zugriff auf einen KI-Generator hat, kann sich die Rohdaten für die Galerie-Bilder hier runterladen, direkt ohne Bildbearbeitung aus Midjourney exportiert. Die jeweiligen Prompts findet ihr in den Metadaten in der Bildbeschreibung oder in der Facebook-Galerie.
Wichtiger Hinweis: Die Bilder sind die rohen Ausgangsbilder, es müssen also weiterhin die Schritte 2–4 durchlaufen werden, wenn die Bilder 360°-tauglich werden sollen. Alternativ könnt ihr die Bilder direkt in der Galerie ansehen.
Nach der Veröffentlichung dieser beiden Artikel haben sich wiederholt Fotograf*innen bei mir gemeldet, welche ebenfalls Probleme hatten, sich von der Bildagentur Clipdealer ihre offenen Honorare auszahlen zu lassen. Vor allem für Fotograf*innen aus dem Ausland ist auch der vergleichsweise einfache Weg über ein Mahnverfahren oft zu komplex, um die Ansprüche durchzusetzen.
Auch im Microstock-Forum microstockgroup.com gibt es viele Erfahrungsberichte von verzweifelten Fotograf*innen, welche ihre Clipdealer-Honorare nicht ausgezahlt bekommen. Einfach mal den Agenturnamen in das Suchfeld dort eintippen.
Das Vorgehen von Clipdealer, auf Auszahlungsanforderungen nicht zu reagieren, scheint demnach leider weder ein Einzelfall noch kurzfristiger Natur gewesen zu sein.
Ich habe daraufhin zwei dieser Fotograf*innen meine Hilfe angeboten: Sie haben mir ihre Honoraransprüche abgetreten, welche ich selbst dann in deren Namen mit Hilfe meines Rechtsanwalts Sebastian Deubelli von SLD IP LAW auf eigene Kosten eingefordert habe.
Clipdealer hat beide Mahnbescheide zwar ignoriert, aber nachdem wir dadurch einen Vollstreckungsbescheid erwirken konnten und der Gerichtsvollzieher zwei Mal bei Clipdealer für eine Zwangsvollstreckung vorstellig wurde, hat die Bildagentur die offenen Honorare sowie die Verfahrenskosten an uns ausgezahlt.
Für die beiden Fotograf*innen sind keine Kosten entstanden, aber das gesamte Verfahren hat jeweils etwas über ein Jahr gedauert.
Wer ebenfalls Probleme hat, seine offenen Fotografenhonorare von der Bildagentur Clipdealer einzufordern, kann sich gerne bei mir melden. Ich schaue dann, ob ich ebenfalls unterstützend tätig werden kann.
ENGLISH: Photographers issue legal warnings: The bailiff at the picture agency Clipdealer
After the publication of these two articles, I was repeatedly contacted by photographers who also had problems getting their outstanding fees paid by the stock agency Clipdealer. Especially for photographers from abroad, the comparatively simple route via a dunning procedure is often too complex to enforce their claims.
In the microstock forum microstockgroup.com there are also many testimonials from desperate photographers who have not been paid their Clipdealer earnings. Just type the agency name into the search field there.
Unfortunately, Clipdealer’s practice of not responding to payment requests does not appear to have been an isolated case or of a short-term nature.
I then offered my help to two of these photographers: They assigned their royalty claims to me, which I then claimed myself on their behalf with the help of my lawyer Sebastian Deubelli from SLD IP LAW at my own expense.
Clipdealer ignored both reminder notices, but after we were able to obtain a writ of execution and the bailiff made two visits to Clipdealer for enforcement, the stock agency paid us the outstanding fees and the costs of the proceedings.
The two photographers did not incur any costs, but the entire process took a little over a year in each case.
Anyone who also has problems claiming their outstanding photographer’s fees from the stock agency Clipdealer is welcome to contact me. I will then see if I can also provide support.
Meine Klage gegen den deutschen Verein LAION e.V., welcher unter anderem Trainingsdatensätze für KI-Anwendungen bereitstellt, hat weltweit für viel Aufmerksamkeit gesorgt.
Da es auch regelmäßig viele Anfragen zum aktuellen Stand des Verfahren gibt, hier ein kurzes Update.
Den Hintergrund für das Einreichen meiner Klage könnt ihr hier und hier ausführlich in meinen Blogartikeln nachlesen.
Kurz gefasst befinden sich etliche meiner Fotos im Datensatz „LAION 5B“. Anhand eines konkreten Fotos als Beispiel fordere ich Unterlassung und Auskunft über den Nutzungsumfang, da ich der Meinung bin, dass die Verwendung des Fotos für das Trainieren des Datensatzes eine urheberrechtlich relevante Vervielfältigung darstellt.
Der Verein LAION e.V. sieht das naturgemäß anders, wie in den beiden zitierten Blogartikeln gut erkennbar ist. Daher blieb uns nur die Möglichkeit des Klagewegs.
Zeitlicher Ablauf der Klage:
27.04.2023: Klage eingereicht beim Landgericht Hamburg
28.06.2023: Verfügung des Landgericht Hamburg, der Verein kann Verteidigungsbereitschaft anzeigen und Klage erwidern
01.08.2023: LAION e.V. reicht Klageerwiderung ein
20.09.2023: Stellungnahme meines Anwalts zur Klageerwiderung
25.04.2024 um 13:00 Uhr: Gerichtstermin vor dem Landgericht Hamburg (Update 12.4.2024: Die Uhrzeit wurde geändert)
Das Landgericht Hamburg hat also in ca. einem halben Jahr den Gerichtstermin angesetzt, in dem dann mündlich weiter über die Klage verhandelt werden wird. Das Verfahren ist öffentlich. Hier die aktuelle Zusammenfassung des Falls durch die mich vertretende Kanzlei SLD.
Andere aktuelle Klagen im KI-Bereich
Ich bin jedoch nicht der einzige, welcher sich daran stört, dass seine urheberrechtlich geschützten Werke ohne Nachfragen oder Entlohnung durch KI-Firmen verwertet werden.
In den USA läuft aktuell diese Sammeklage dreier Künstlerinnen gegen Stability AI, Midjourney und DeviantArt.
Die US-Komikerin Sarah Silverman klagt derzeit zusammen mit zwei anderen Autoren gegen den ChatGPT-Betreiber OpenAI und den Facebook-Mutterkonzern Meta wegen der Verwendung einiger ihrer Bücher in den KI-Trainingsdaten.
Auch gegen Google läuft diese Klage wegen der unerlaubten Verwendung von Daten für das KI-Training.
Schon länger bekannt ist die Klage der Bildagentur Getty Images gegen Stability AI wegen deren Verwendung von Bildern im KI-Trainingsdatensatz.
Schon drei Mal haben Silke Güldner und ich zusammen in Hamburg einen ganztätigen Praxis-Workshop zum Thema „KI in der Berufsfotografie“ gegeben.
Jedes Mal war der Workshop schnell ausgebucht und über unsere Social-Media-Kanäle erreichte uns oft der Wunsch, ob wir das Ganze auch online anbieten würden.
Deshalb wird der vierte Workshop nun online stattfinden am Freitag, den 26.01.2024.
Seit anderthalb Jahren beschäftige ich mich nun schon intensiv mit der Bilderstellung durch Künstliche Intelligenz. Zusammen mit meinem Team habe ich mittlerweile ein Portfolio von über 7000 KI-Bildern, welche ich bei Bildagenturen anbiete.
„Hintergründe & Möglichkeiten der KI-Tools in der fotografischen Praxis mit KI-Experte & Fotograf Robert Kneschke und Fotografenberaterin Silke Güldner
Der Workshop bietet eine einzigartige Gelegenheit, um tiefer in die Welt der künstlichen Intelligenz einzutauchen und ihre Anwendungsmöglichkeiten in der Fotografie zu entdecken. Hier lernen Profi- und Nachwuchsfotografen die Funktionsweise und verschiedenen KI-Tools kennen, können diese im praktischen Teil selbst ausprobieren und diese für ihre eigene Positionierung im Markt reflektieren. Durch Diskussionen und den Austausch mit der Gruppe und den Referenten erhalten sie darüber hinaus auch Feedback und Inspirationen für ihre künftige Arbeit und die Kommunikation mit ihren Kunden. Am Ende des Workshops sind die Teilnehmer bestens vorbereitet, um die Entwicklungen und Herausforderungen im Kontext von KI und Fotografie zu verstehen und zukünftige Möglichkeiten zu nutzen.
Inhalte
Einführung KI
Wie funktioniert KI-Bilderstellung
Vorstellung der Tools Stable Diffusion, Dall‑E 3, Midjourney, Firefly
Anwendungsmöglichkeiten, Unterschiede und Motivbeispiele
Praxis Teil 1
Anhand der Teilnehmer-Portfolios sprechen wir über Möglichkeiten, die KI für die eigenen Ziele bieten kann und wann konventionelle Fotografie der bessere Weg ist
Portfolio Vorstellung der Teilnehmenden
Vorteile und Nutzen von konventioneller Fotografie gegenüber KI-Lösungen in der Kundenberatung
Praxis Teil 2
Hands On & Live Demos
Testen der KI-Tools am Beispiel von Midjourney
Erläuterung von Prompt-Engineering, In- and Outpainting
Tools für den KI Workflow
Überblick der Nutzungsmöglichkeiten & Best Practice Beispiele
Meta Themen
Rechtliche & moralische Probleme der KI-Nutzung
Veränderung der Berufsfotografie & Einfluss auf die Preisfindung
Ausblick & Kooperationsmöglichkeiten“
Der Workshop wird am Freitag, den 26.01.2025 online stattfinden, mehr Informationen zur Veranstaltung findet ihr hier auf der Webseite des Veranstalters Photo+Medienforum Kiel.
Die Teilnehmer*innen ist begrenzt, also zögert nicht, euch bei Interesse rechtzeitig euren Platz zu sichern.
Was ist der aktuell beste KI-Upscaler? Vor wenigen Tagen hat die KI-Firma Midjourney einen neuen Upscaler veröffentlicht, der deren KI-Bilder um den Faktor 2 oder 4 vergrößern kann.
Da ich bisher ein anderes Tool genutzt habe, wollte ich herausfinden, wie sich die Bildqualität unterscheidet. Wo ich schon dabei war, habe ich noch paar andere Upscaler verglichen und die Ergebnisse bei Facebook und LinkedIn gepostet. Da gab es in den Kommentaren noch weitere Vorschläge, welche Upscaler ich berücksichtigen sollte.
Na gut, dachte ich mir, dann ziehe ich das eben größer auf und veröffentliche hier einen umfassenden Test über die Bildqualität und Unterschiede der aktuell auf dem Markt erhältlichen Upscaler.
Alle Testausschnitte im direkten Vergleich (Klicken zum Vergrößern)
Der Testaufbau und das Ausgangsbild
Ich habe mir mit dem KI-Tool Midjourney ein quadratisches PNG-Bild einer blonden Frau generieren lassen mit der Auflösung 1024x1024 Pixel (1,05 Megapixel):
Das Testbild
Dieses Bild habe ich dann mit verschiedenen Methoden um den Faktor 4 auf 4096x4096 Pixel (16,7 Megapixel) vergrößern lassen.
Da die Beurteilung der Ergebnisse subjektiv gefärbt ist und jeder andere Maßstäbe an seine Bilder anlegt, veröffentliche ich hier auch die PSD-Datei der verschiedenen Ergebnisse als Download, jede Ebene ist sauber nach der genutzten Upscaler-Methode benannt.
DOWLOAD-Link (Dropbox) als gepackte .rar-Datei (ACHTUNG: Datei ist 610 MB groß, entpackt dann 889 MB!) BACKUP-Link (Wetransfer).
Damit kann jede*r durch das Ein- und Ausblenden der Ebenen in der 100%-Ansicht selbst entscheiden, welches Ergebnis ihm/ihr am meisten zusagt.
Für diesen Blogartikel habe ich einen Bereich des linken Auges ausgeschnitten, damit hier die 100%-Ansicht (500x500 Pixel) gezeigt werden kann. Die Ausschnitte habe ich sauber benannt und als JPG (Qualität 10) abgespeichert. Der Ausschnitt ist in der Photoshop-Datei auch als Pfad hinterlegt.
Der große Upscaler-Test: Die Ergebnisse
1. Midjourney Upscaler
Beginnen wir mit dem Upscaler von Midjourney. Obwohl dieser erst wenige Tage alt ist, gibt es schon zwei Versionen und Midjourney behält sich vor, den Upscaler auch in Zukunft zu verändern/verbessern:
„The upscaler is subtle and tries to keep details as close as possible to the original image (but may not fix glitches or issues with the old image)“
Midjourney Upscaler 4x V1 (18.10.2023)
Die erste Version (V1) des Midjourney-Upscaler bügelte die Hauttextur ziemlich glatt, das ganze Bild wirkt insgesamt sehr nach 1980er-Jahre-Airbrush-Retusche.
Das Entwickler-Team nahm sich die Kritik der Community jedoch zu Herzen und schob zwei Tage später das erste Update hinterher:
„We’re […] hearing everyone’s feedback that the 4x upscaler is a bit soft and we’re looking at improvements which may further improve things. This means the upscaler settings may change suddenly over the next week without warning as we tweak things. […] The V5 4x Upscale now features improved sharpness, and in some cases smaller scale high frequency details“
Dadurch sieht das Ergebnis deutlich besser aus, die Haare und Wimpern sehen täuschend echt aus und auch die Hauttextur kann überzeugen:
Midjourney Upscaler 4x V2 (20.10.2023)
Der erste große Nachteil dieses Upscalers ist logischerweise, dass er nur auf KI-Bilder anwendbar ist, die direkt in Midjourney erstellt wurden.
Ein weiterer Punkt sind die Kosten: Der 4x Upscaler kostet grob 6x soviel GPU-Minuten wie die Generierung eines 4x4-Bilder-Grids. Diese Zeit wird von dem bezahlten Minutenkontingent abgezogen, welches die Nutzer je nach Abomodell zur Verfügung haben. Im Standard-Plan sind das zum Beispiel 15 Stunden pro Monat.
Eine Stunde Rechenzeit kann aktuell für 4 USD dazu gekauft werden. Ich habe mal geschaut, wie viel Zeit für ein 4x-Upscale von Midjourney berechnet wird. Beim obigen Bild waren das ca. 3 Minuten. Mit einer Stunde Rechenzeit könnten damit 20 Bilder hochskaliert werden. Bei Kosten von 4 USD/Stunde würde ein Upscale ca. 20 US-Cent kosten. Wer die inklusiven Stunden im Standard- oder Pro-Plan nutzt, zahlt nur die Hälfte.
2. Topaz Photo AI
Der Upscaler von Topaz Labs war unsere bisherige bevorzugte Upscale-Methode. Getestet haben wir hier mit der Version 2.0.5. Topaz Photo AI ist ein recht neues Tool, mit dem verschiedene KI-basierte Werkzeuge wie Topaz Gigapixel, Topaz Sharpen etc. zusammengefasst wurden.
Topaz Photo AI V2 Upscaler 4x
Die Ergebnisse sehen sehr überzeugend aus, vor allem die Hauttextur ist sehr realistisch, die Details wie Wimpern und Haare sind jedoch etwas gröber.
Topaz hat auch eine Funktion namens „Recovering Face“, womit laut Hersteller die Ergebnisse von Gesichtern in geringer bis mittlerer Auflösung deutlich verbessert werden kann:
Es gibt einen Regler, der stufenlos von 0 bis 100% eingestellt werden kann. Bei 25% sieht das Ergebnis so aus:
Topaz Photo AI V2 Upscaler 4x + 25% Recovering Face
Ich finde, dass das Gesicht dadurch einfach matschiger wird. Dieser Effekt nimmt mit der Stärke der Recover-Funktion zu, bei 100% ist das Ergebnis deutlich unbrauchbarer als ganz ohne die Funktion. Vermutlich liegt das daran, dass die Bildqualität vom Ausgangsmaterial schon „zu gut“ für diese Funktion ist, die der Verbesserung von „low quality faces“ dienen soll.
Ein weiterer Vorteil von Topaz Photo AI ist, dass hier Bilder als Batch bearbeitet werden können und neben dem Hochskalieren im gleichen Arbeitsgang wahlweise auch geschärft, entrauscht, farblich angepasst etc. werden können.
Mit 199 USD sind die Kosten initial recht hoch, dafür können damit unbegrenzt Bilder bearbeitet werden und es gibt regelmäßige Updates. Für Vielnutzer preislich die beste Wahl. Weiterer Pluspunkt: Es gibt ein Photoshop-Plugin.
3. Photoshop
Die früher übliche und seit langem verfügbare Methode mit Photoshop-Bordmitteln war, einfach die Bildgröße hochzusetzen. Das Ergebnis, getestet mit Photoshop 2024 (V25.0), sieht dann so aus:
Es ist damit sichtbar mit Abstand das schlechteste Ergebnis, was wenig verwundert, da hier noch keine KI Hilfestellung leistet. Selbst mit dem bekannten Kniff, das Bild in 10%-Schritten hochzuskalieren, war das Ergebnis nur minimal besser und reicht trotzdem nicht an die anderen Methoden heran.
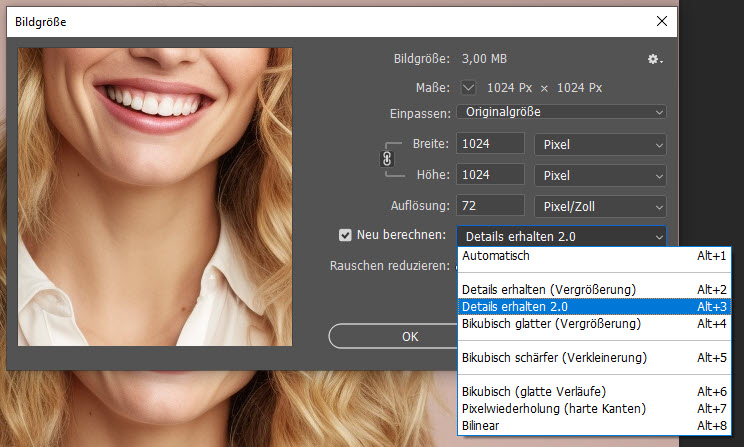
In den Kommentaren zu meinem ersten Test gab es zwei Hinweise, wie ich die Ergebnisse verbessern könnte. Der erste war, dass sich hinter dem Häkchen „Neu berechnen“ noch eine Auswahlmöglichkeit für „Details erhalten 2.0“ verbirgt:
Das Ergebnis ist zwar „besser“ und schärfer, dafür aber mit sichtbaren Artefakten übersät. Wenn ich den Regler „Rauschen reduzieren“ auf 50% setze, verschwinden die Artefakte, aber das Bild sieht etwas weichgezeichnet aus.
Kurz: Der schlechteste Upscaler im Test. Es wundert mich etwas, dass hier die Adobe Sensei-KI noch nicht Einzug gehalten hat, aber vermutlich wird das ein Feature sein, was eher früher als später veröffentlicht werden wird.
Jemand meinte noch, dass sich unter den „Neural Filters“ ein „Superzoom“-Filter verberge. Das ist jedoch kein richtiger „Upscaler“, weil damit das Bild tatsächlich „rangezoomt“ wird, ich verliere also die Bildmotive am Rand.
Dafür sind die Kosten jedoch unschlagbar, da jeder mit einem Photoshop-Abo unbegrenzt viele Bilder hochskalieren kann.
Kurzes Update 23.10.2023: (sample images not included in download yet) Einige Leser wiesen mich darauf hin, dass die „Superzoom“-Funktion doch das ganze Bild anzeigt, wenn die Option „Bild > Alles einblenden“ genutzt wird. Zusätzlich gibt es einige Auswahlmöglichkeiten wie z.B. „Gesichtsdaten verbessern“ und „JPG Artefakte reduzieren“:
Photoshop Neural Filter „Superzoom“ mit „Gesichtsdaten verbessern“ und „JPG Artefakt-Reduzierung“ aktiv
Das Ergebnis sieht schon besser als mit der alten Photoshop-Methode aus und rangiert damit im oberen Mittelfeld. Für die Top-Liga sind die Bereiche wie Haare oder Wimpern noch etwas zu matschig.
Außerdem bietet Adobe in Lightroom oder Camera Raw die „Verbessern“-Option, welche ebenfalls hochskaliert, aber nur bei Raw-Dateien funktionieren soll.
4. Luminar Neo
Luminar Neo Hochskalieren 4x
Luminar Neo ist, ähnlich wie Topaz Labs, ein weiteres KI-gestütztes Tool-Kit für die Fotobearbeitung mit vielen Funktionen. Getestet wurde hier mit der Version 1.14.1.12230 im Upscale Type „Universell“.
Gefühlt würde ich sagen, dass das Ergebnis irgendwo zwischen Midjourney und Topaz liegt. Die Details sind etwas gröber als bei den anderen beiden Upscalern, die Haut weichgezeichneter als bei Topaz, aber weniger als bei Midjourney.
Luminar Neo Hochskalieren 4x + Gesichtsverstärker AI
Es gibt bei der Hochskalieren-Funktion noch das optionale Häkchen „Gesichtsverstärker AI“, welches jedoch schlicht gesagt (bisher) grausame Ergebnisse liefert. Es sieht so aus als würde hier ein Geisterbild über dem anderen liegen. Kurz: Finger weg von dem Häkchen.
Die Kosten von Luminar Neo liegen bei 219 Euro für die lebenslange Nutzung, es gibt aber auch Abo-Modelle ab 11,95 Euro/Monat, was sich gut zum Testen eignet. Dafür bekommt man aber nicht nur die Hochskalieren-Funktion, sondern ein breites Bündel an Werkzeugen wie Entrauschen, Schärfen, Lichtmanipulationen, und vieles mehr. Die Handhabung mit dem separaten Installieren der verschiedenen Plugins finde ich jedoch nicht ganz intuitiv.
5. Pixelcut
Pixelcut ist ein kostenloser Online-Upscaler, welcher bequem via Drag & Drop funktioniert.
Pixelcut Upscaler 4x
Das Ergebnis ist relativ grob, aber besser als Photoshop. Dafür sind die Kosten gleich null. Für Gelegenheitsnutzer also sehr praktisch.
Es ist auch eine Batch-Nutzung möglich, die dann jedoch im „Pixelcut Pro“ 9.99 USD pro Monat oder 59.99 USD im Jahr kostet. Dafür ist dann auch eine iPhone/Android-App-Nutzung enthalten und unbegrenzte Hintergrundentfernung.
6. Neural.love
Neural.love ist ein online-basierter AI-gestützter HD Portrait-Generator, der als Leserhinweis seinen Eingang in diesen Test fand.
Der Leistungsumfang reicht von der direkten KI-Bilderstellung über Image-to-Image Bildremixe, Portraitrestaurierungen etc. und eben auch ein Upscaler namens „Image Enhance/Quality Enhance“.
Neural.love Upscaler 4x
Das Ergebnis ist etwas detaillierter als bei Pixelcut, reicht aber von der Schärfe nicht an Topaz oder Midjourney heran.
Neural.love Upscaler 4x + Smart Noise
Es gibt noch die Option, „Smart Noise“ zu aktivieren, was – wie der Name schon vermuten lässt – ein feines Rauschen über das Bild liegt. In der 100%-Ansicht ist das recht auffällig, beim Rauszoomen ist der Eindruck aber positiver als ohne das Rauschen.
Das Online-Tool erfordert eine Registrierung per Email und arbeitet mit einem Credit-System für die Kosten. Die ersten fünf Credits sind frei (also 5x Upscaling), danach können 300 Credits im Abo für 30 Euro/Monat oder zeitlich unbegrenzt für 57 Euro gekauft werden. Das wären dann 10 bzw. 19 Cent pro Upscale.
7. Upscale.media
Upscale.media ist ein weiterer Online-Upscaler auf Credit-Basis:
Upscale.media 4x Upscaler
Das Ergebnis rangiert solide im Mittelfeld und ist schon gut brauchbar.
Upscale.media 4x Upscaler + Qualität verbessern
Es gibt auch die Option, ein Häkchen bei „Qualität verbessern“ zu setzen, doch das scheint das Gegenteil zu bewirken. Das Bild verliert an Details und die Konturen werden unnatürlich stark betont. Würde ich nicht empfehlen.
Kosten? Pro Tag sind zwei Uploads ohne Registrierung kostenlos möglich, nach Registrierung gibt es fünf kostenlose Uploads. 100 Credits kosten im Abo 19 USD bzw. zeitlich unbegrenzt 49 USD, was 19 US-Cent bzw. 49 US-Cent pro Upscaling entspricht.
8. Stable Diffusion Upscaler
Auch im quelloffenen KI-Generator Stable Diffusion gibt es gleich mehrere Upscaler. Hier öffnet sich aber auch die Büchse der Pandora, weil es neben den sieben verschiedenen Upscalern, die im Web-UI von Automatic111 dabei sind, noch unzählige weitere gibt, die auch jeweils noch viele verschiedene Settings haben.
Allein in der Datenbank OpenModelDB finden sich unter „General Upscaler“ 66 verschiedene Modelle, die kostenlos heruntergeladen und installiert werden können und alle ihre Stärken und Schwächen haben.
Um die Sache noch komplexer zu machen, können Bilder auch mittels der „IMG2IMG“-Methode hochskaliert werden, wobei hunderte verschiedene KI-Modelle zur Auswahl stehen.
Deshalb habe ich hier nur mal einen internen Upscaler getestet, den Upscaler „ESRGAN_4x“ mit einer GFPGAN visibility von 0.5.
Das Ergebnis ist ca. doppelt so gut wie die Photoshop-Methode, aber sichtbar schlechter als die meisten anderen Upscaler im Test.
Dazu kommt, dass die Geschwindigkeit des Skalierens ganz stark von der lokal verwendeten Hardware abhängt. Mit einer RTX 2080-Grafikkarte dauerte das Hochskalieren über 15 Minuten. Wer die Settings noch etwas mehr hochdreht, muss exponentiell länger warten.
Auch die Bedienung gestaltet sich komplex, da die Modelle gefunden und runtergeladen werden müssen und für die verschiedenen Settings keine Anleitung existiert. Ihr werdet also auf etlichen Webseiten rumsurfen, um euch die empfohlenen Einstellungen zusammenzusuchen. Dafür sind die Kosten fast Null, da alle benötigten Tools kostenlos erhältlich sind. Ihr zahlt also nur für euren Strom.
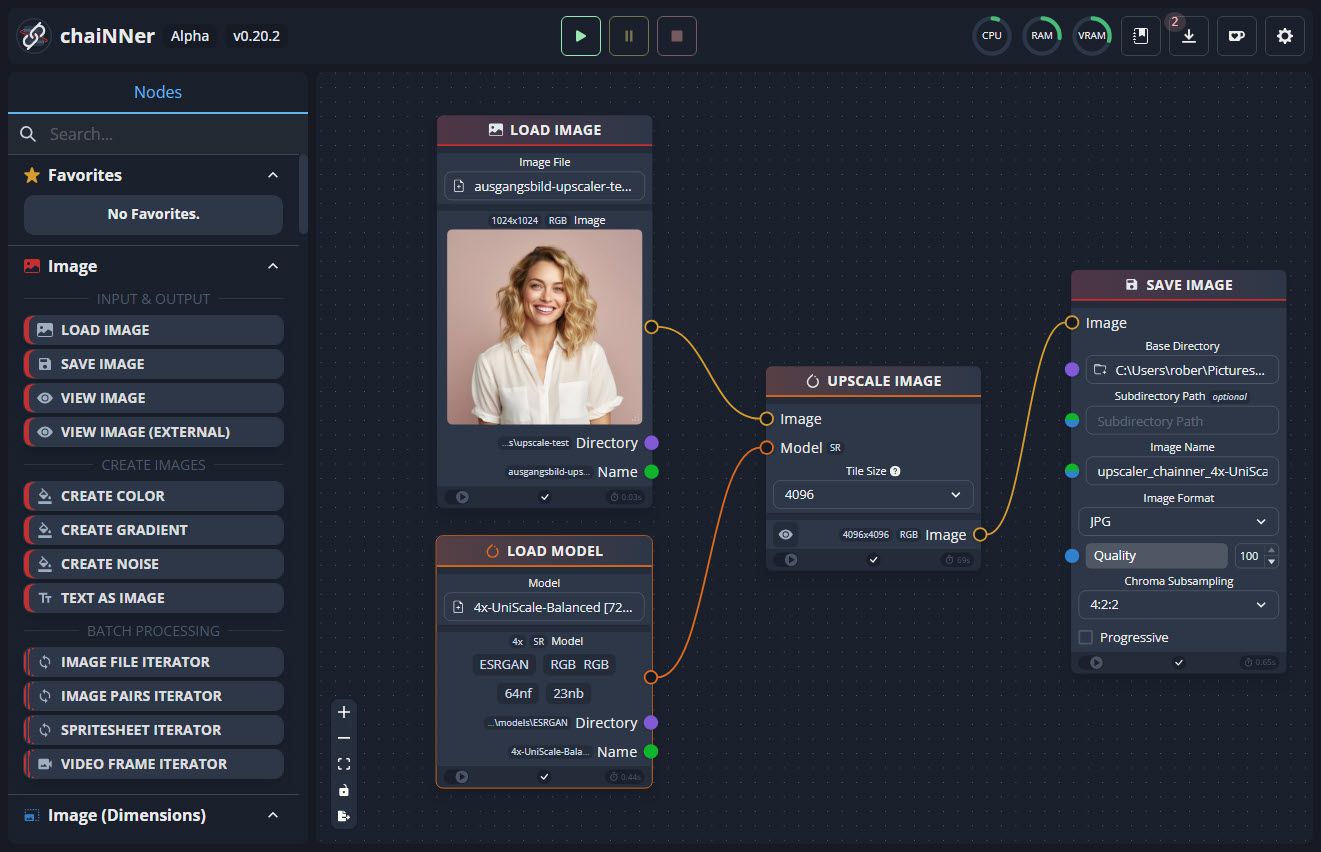
ChaiNNer ist ein weiterer Tipp aus den Kommentaren. Das ist ein OpenSource-Projekt, welches ursprünglich als KI-Upscaler gestartet ist, mittlerweile aber sehr umfangreiche Bildverarbeitungsfunktionen bietet.
ChaiNNER ist node-basiert, was sehr ungewohnt ist, für die, die es nicht kennen, aber wer das Prinzip verstanden hat, kann auf diese Weise sehr komplexe Workflow-Ketten aufbauen, die dann mit einem Klick abgearbeitet werden. Der Workflow für das einfache Hochskalieren sieht dann so aus:
ChaiNNer-Upscaling-Workflow (Klicken zum Vergrößern)
Das Programm ist noch in der Alpha-Phase (ich habe v0.20.2 genutzt) und kostenlos für Windows, Mac und Linux erhältlich. Die Installation erfordert etwas Zeit, ist aber in der GitHub-Anleitung gut beschrieben.
ChainNNer selbst ist genau genommen gar kein Upscaler, sondern dient als GUI (grafische Benutzeroberfläche) für andere OpenSource-Upscaler auf PyTorch-Basis. Das heißt, fast alle Upscaler die bei Stable Diffusion integriert werden können, sind auch in ChaiNNer nutzbar. Wie im Bereich „Stable Diffusion“ erwähnt, stehen euch also mindestens 66 verschiedene Möglichkeiten zur Verfügung.
ChaiNNer 4x Upscaler mit Model „Remacri“
Getestet habe ich ChaiNNer mit dem beliebten „Remacri“-Modell, welches eine überzeugende Kombination aus Schärfe und Struktur liefert. Ebenfalls nicht ganz so gut wie Topaz oder Midjourney, dafür kostenlos und seeehr flexibel.
ChaiNNer 4x Upscaler mit Model „UniScale-Balanced“
Ich habe noch ein weiteres Modell getestet, das „UniScale-Balanced“ auf Basis der ESRGAN-Architektur. Das schnitt jedoch deutlich schlechter ab als „Remacri“.
Noch mal zum Verständnis: In Stable Diffusion und ChaiNNer können die gleichen Upscaler-Modelle eingesetzt werden, bei mir lief die Verarbeitung jedoch deutlich schneller bei ChaiNNer. Dafür gibt es bei Stable Diffusion etwas mehr Einstellmöglichkeiten, die ich auf die Schnelle nicht bei ChaiNNer gefunden habe.
Das Resultat
Es gibt noch unzählige weitere Tools, vor allem online, aber die meisten davon rangieren im Mittelfeld und sind preislich ähnlich angesiedelt.
Von der Bildqualität liegt Midjourney aktuell meiner Meinung nach stark vorne, hat eben aber den gravierenden Nachteil, dass damit nur Midjourney-Bilder hochskaliert werden können. Auch preislich ist Midjourney kein Zuckerschlecken, wenn man nicht gerade eh Stunden übrig hat in deren Abo-Modell.
Für Power-User, die mehr als 1000 Bilder hochskalieren wollen, bleibt die Wahl zwischen Topaz Photo AI und Luminar Neo preislich die bessere Wahl, wobei Topaz in der Bedienung wegen der Automatisierungsmöglichkeiten etwas die Nase vorn hat.
Insgesamt ist die Qualität aber auch subjektiv behaftet und kann sich je nach Motiv oder mit einem Update eines Tools auch wieder ändern.
Bei den ganzen, teils kostenlosen, Online-Upscalern solltet ihr auch bedenken, dass ihr eure Daten in fremde Hände gebt und dem Anbieter vertrauen solltet, damit vertraulich umzugehen. Vermutlich werden auch die meisten dieser Anbieter unter der Haube eines der unzähligen OpenSource-Upscaler laufen haben.
Welchen Upscaler nutzt ihr aktuell und welches Ergebnis hat euch hier am meisten überzeugt?
Die Community-Test-Erweiterung
Wer den Test mit eigenen Modellen oder anderen Anbietern erweitern will, hat in diesem Artikel alle notwendigen Grundlagen: Das 1024x1024-Ausgangsbild steht oben zum Download zur Verfügung sowie die Photoshop-Datei mit den Ebenen der Upscaler und der Pfad-Auswahl für die Ausschnittvergrößerung.
Ihr könnt also gerne weitere Methoden testen und das Ergebnis gerne in den Kommentaren posten (Bilder bitte als Link).