Vor einigen Wochen meldete sich ein Fotograf bei mir, welcher über die Distributionsplattform Wirestock seine Bilder bei verschiedenen Bildagenturen anbietet, darunter auch Shutterstock und Pond5.
Er wies mich darauf hin, dass die Einnahmen, welche Wirestock im Rahmen von „Dataset Earnings“ erhalten würde, bisher nicht an die Fotografen ausgezahlt habe.

„Dataset Earnings“ sind Erlöse aus den Fotografen-Portfolios, wenn diese Bilder oder Videos zum Beispiel für KI-Trainings benutzt werden. Mehr dazu findet ihr in diesem Artikel von mir.
Bisher gab es drei Auszahlungsrunden für diese Arten von Erlösen:
- Shutterstock: Auszahlung Dezember 2022
- Pond5: Auszahlung April 2023
- Shutterstock: Auszahlung Anfang Mai 2023
Von diesen drei Auszahlungen haben die Wirestock-Fotografen bisher kein Geld gesehen.
Da der Fotograf bei Wirestock nur sehr ausweichende Antworten auf seine Nachfragen erhalten hat, wandte er sich an mich. Ich habe das mit anderen Wirestock-Fotografen verifiziert und ebenfalls eine Anfrage an Wirestock gestellt.
Wirestock ändert die AGB
Vorher noch änderte Wirestock aber einseitig die Allgemeinen Geschäftsbedingungen (AGB): Statt der bisher gültigen Aufteilung der Erlöse 85% an die Fotografen und 15% an Wirestock wurde am 26. Mai 2023 von Wirestock beschlossen, dass für „Dataset Deals“ nur 50% ausgezahlt würden. Fotografen können diese Deals per Opt-Out verweigern laut Wirestock:
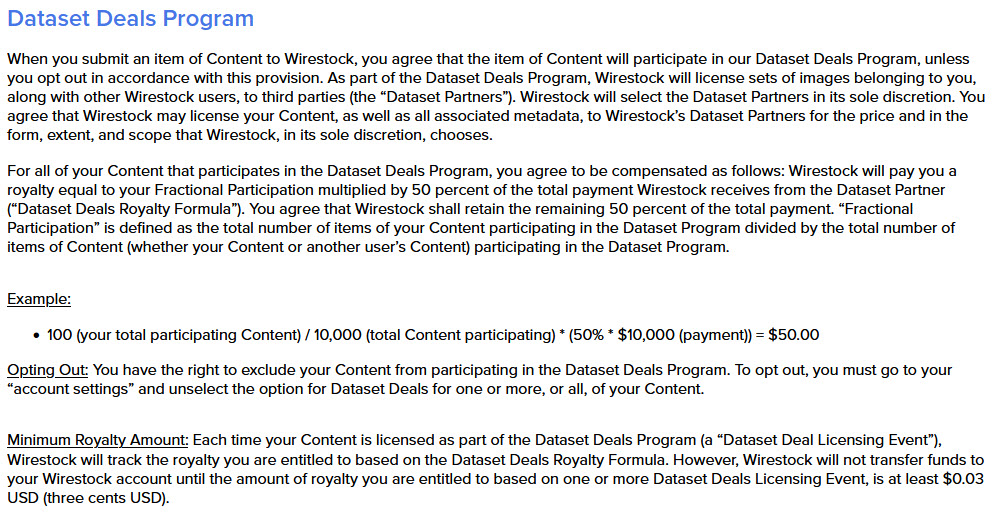
Antwort von Wirestock
Auf meine Nachfrage kam dann am 3.8.2023 von Wirestock endlich eine Stellungnahme, die ich hier übersetzt wiedergebe:
„Wir freuen uns, Ihnen mitteilen zu können, dass wir die Einnahmen aus den Dataset-Deals so bald wie möglich an unsere Fotografen ausschütten werden. Wirestock ist derzeit dabei, die Einnahmen aus allen Dataset-Deals zu akkumulieren und beabsichtigt, sie vor Ende des dritten Quartals 2023 auf die Konten der Fotografen zu übertragen. Bezüglich des Provisionssatzes sollte ich klarstellen, dass der in Ihrer E‑Mail genannte Provisionssatz von 15 % für Foto‑, Video- und Vektorlizenzen gilt. Bis Anfang dieses Jahres gab es bei Wirestock kein Dataset-Deals-Programm, und daher wurde auch kein Provisionssatz für Dataset-Deals festgelegt.
Mit der Einführung des Dataset Deals-Programms haben wir einen Provisionssatz von 50 % für diese speziellen Geschäfte eingeführt. Wir sind uns der Bedeutung von Transparenz und Fairness bewusst und glauben, dass der Provisionssatz von 50 % ein ausgewogenes Verhältnis zwischen dem Nutzen für unsere Teilnehmer und der Deckung der mit Dataset-Transaktionen verbundenen höheren Bearbeitungskosten darstellt.“
Wenn wir den ganzen Marketing-Fluff weglassen, ist die einzig konkrete Aussage: Ja, bisher wurden die Datendeals-Honorare nicht ausgezahlt, wir werden das bis Ende September 2023 nachholen. Mal sehen, ob das stimmt.
Ich bezweifle auch, dass Wirestock „höhere Bearbeitungskosten“ hat, die mehr als das dreifache des bisherigen Honorars rechtfertigen. Die Argumentation, dass die 15% Kommission nur für Lizenzen gelten, halte ich für stark an den Haaren herbeigezogen, da auch beim oben gezeigten Screenshot davon die Rede ist, dass beim „Daten Deal“ Bilder lizenziert werden.
Weitere Änderungen bei Wirestock
Einen Tag vor Erhalt der Email von Wirestock gab es noch eine weitere Nachricht. Wirestock kündigte an, dass ab sofort mindestens ein kostenpflichtiger „Premium-Account“ Pflicht sei für die Möglichkeit, seine Bilder mittels Wirestock bei verschiedenen Bildagenturen anzubieten. Zusätzlich wird die monatliche Uploadmenge beschränkt. Kostenpunkt: Aktuell 12,99 USD pro Monat für den Upload von 100 Bildern im Monat. Die 15% Kommissionen (bzw. 50% bei Dataset Deals) will Wirestock aber natürlich weiterhin von den Honoraren abziehen.
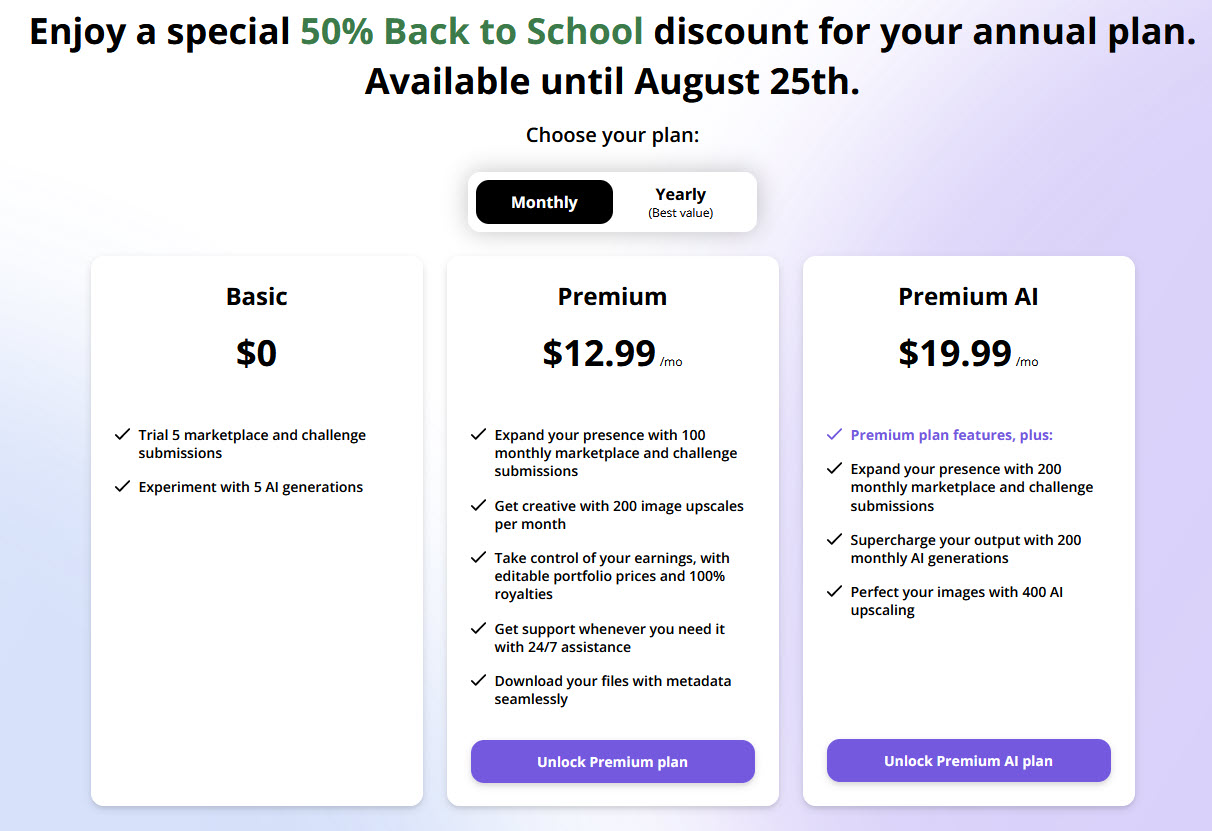
Als Begründung wird die stark wachsende Anzahl an Bildeinreichungen genannt, welche zu Verzögerungen bei der Überprüfung und Verarbeitung von Inhalten, zu steigenden Kosten für deren Kennzeichnung, Überprüfung, Verarbeitung und Speicherung und zu
Schwierigkeiten bei der Aufdeckung von Urheberrechtsverletzungen und betrügerischen Aktivitäten führt.
Diese Änderung reiht sich damit ein in die länger werdende Liste fragwürdiger Business-Entscheidungen wie die Einführung des „Instant Pay“-Programms in Zusammenarbeit mit Freepik.
Was sagt ihr zu diesen Änderungen?