Seit Tagen ist in der KI-Welt kaum von etwas anderem die Rede als den beeindruckenden Ergebnissen von Sora.
Sora ist der Name des kürzlich hier vorgestellten Text2Video-Generators der Firma OpenAI, welche auch schon den Text2Bild-Generator Dall‑E und das Text2Text-Generator ChatGPT veröffentlicht hat.

Mit Sora können durch simple Texteingaben hochauflösende Videos von bis zu einer Minute Länge generiert werden.
Einen Überblick über die Ergebnisse findet ihr haufenweise, entweder auf der Sora-Seite direkt oder bei YouTube, zum Beispiel in diesem Video:
Auf der offiziellen Webseite wird lang und breit über die Sicherheit des Tools geredet und gerne erwähnt, dass geplant sei, den C2PA-Metadaten-Standard zur Erkennung von KI-generierten Inhalten zu unterstützen. Auffällig ist aber, dass andere Informationen fehlen.
Das Geheimnis der Trainingsdaten
Auffällig ist, dass an keiner Stelle der Vorstellung von Sora darauf eingegangen wird, wie genau das KI-Tool trainiert wurde. Welche Daten wurden dafür verwendet?
Im technischen Report findet sich nur der lapidare Satz:
“[…] we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios.“
Ach? Ja, das war uns allen klar, aber welche Videos und Bilder habt ihr dafür nun genau benutzt?
In der Vergangenheit hat sich OpenAI nicht mit Ruhm bekleckert, wenn es um Rücksicht auf Urheberrechte bei Trainingsdaten ging.
Das „Opt-Out“, um zu verhindern, dass Bilder für Dall‑E trainiert werden, ist berüchtigt und wurde auch viel zu spät eingeführt. Dall‑E 2 wurde laut dieser GitHub-Seite unter anderem auch mit Hilfe des Vereins LAION e.V. trainiert, welchen ich selbst gerade wegen Urheberrechtsverletzung verklage.
Auch beim zweiten Produkt von OpenAI, ChatGPT, liegt die Sache ähnlich. OpenAI wird gerade von der Zeitung New York Times verklagt, weil urheberrechtlich geschützte Trainingsdaten der Zeitung für das KI-Training von ChatGPT benutzt worden seien.
Bei einer Zeugenanhörung von OpenAI durch das Oberhaus des britischen Parlaments fiel seitens OpenAI auch der folgenschwere Satz:
„Because copyright today covers virtually every sort of human expression–including blog posts, photographs, forum posts, scraps of software code, and government documents–it would be impossible to train today’s leading AI models without using copyrighted materials. Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today’s citizens“
Frei übersetzt: Ohne den Zugriff auf urheberrechtlich geschützte Trainingsdaten könnten wir unsere Tools nicht anbieten.
Genau wegen diesem bisher schon bekannten rücksichtslosen Umgang mit Urheberrechten muss eine Frage viel lauter gestellt werden:
Welche Videos und Bilder wurden für das Training der Sora-KI verwendet?
Die Wahrscheinlichkeit ist sehr hoch, dass auch hier – ähnlich wie beim Training von Dall‑E und ChatGPT urheberrechtlich geschützte Videos (und Bilder) zum Einsatz kamen.
Selbst Wasserzeichen in Videos sind für KI-Entwickler schon lange kein Hindernis mehr. Schon 2017 hat Google selbst eine Technik vorgestellt, mit der Wasserzeichen aus Bildern entfernt werden können.
Auch der LAION-Verein bietet auf GitHub ein kostenloses Tool für die „Wasserzeichen-Erkennung“ an. Von der Erkennung zur Entfernung ist es für geübte Programmierer dann nur noch ein kleiner Schritt, über den aus rechtlichen Gründen nicht so gerne öffentlich geredet wird.
Manchmal aber doch:
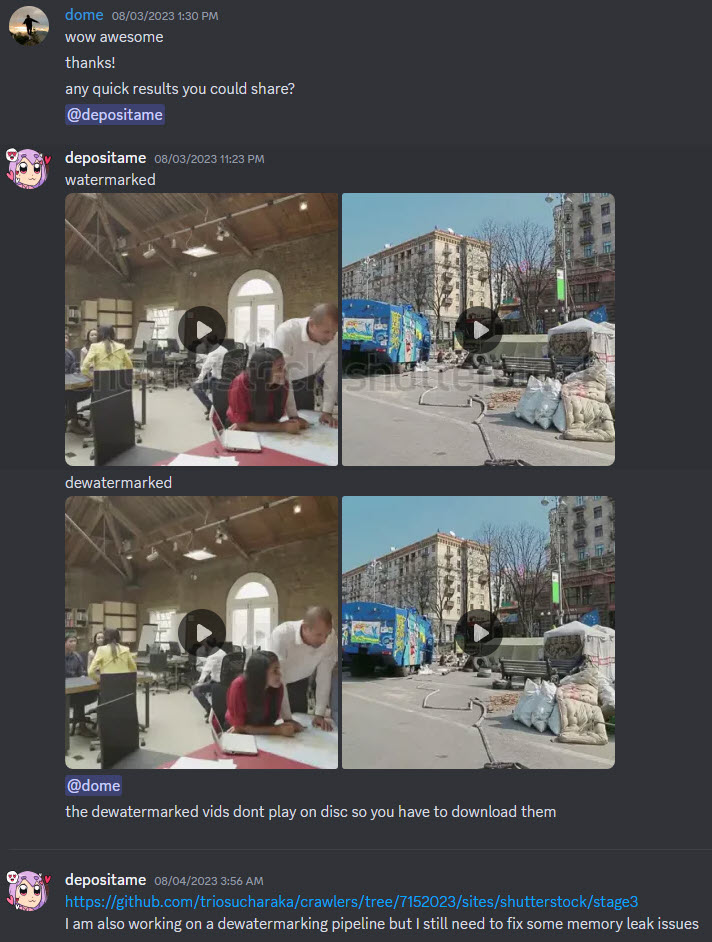
Bei LAION wird zwar an einem eigenen Text2Video-Generator namens phenaki gearbeitet, die technischen Details des Trainings sind denen von Sora aber sehr ähnlich, soweit ich das beurteilen kann.
Die Wahrscheinlichkeit, dass OpenAI daher mit der gleichen Rücksichtslosigkeit wie LAION gegenüber Urhebern beim KI-Training vorgeht, halte ich für hoch, zumal die bisherigen Aussagen und Handlungen von OpenAI leider nicht geeignet sind, Zweifel zu zerstreuen.
Beim ganzen Hype vom SORA und dem Staunen über die tollen Ergebnisse sollte nicht vergessen werden zu fragen, welche (Video-)Künstler beim Training beteiligt waren.























